MAGA
收藏数据集概述:MAGA
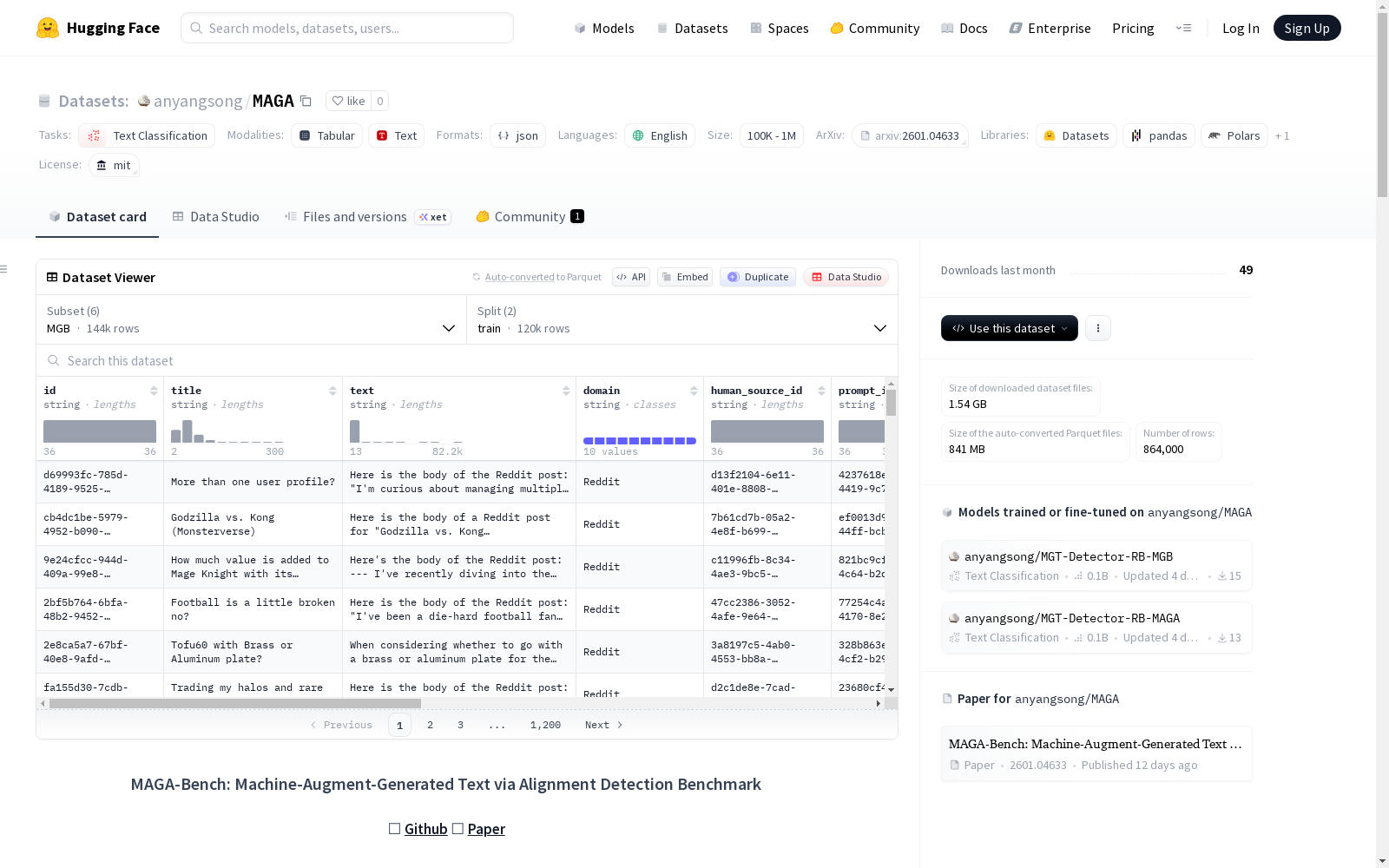
数据集基本信息
- 数据集名称:MAGA (Machine-Augment-Generated Text via Alignment Detection Benchmark)
- 发布者/维护者:anyangsong
- 许可证:MIT
- 主要语言:英语 (en)
- 任务类别:文本分类 (text-classification)
- 数据规模:100K < n < 1M (近一百万条生成文本)
数据集描述与目的
MAGA 是一个通过对齐增强构建的综合性数据集,旨在推进机器生成文本检测器的泛化研究。它包含近一百万条生成文本,覆盖12个生成器、20个领域(10个英文领域和10个中文领域)、4种对齐方法以及多样化的解码策略。该数据集是测试检测器鲁棒性和增强微调检测器泛化能力的宝贵资源。
数据集结构与配置
数据集包含多个配置(config),每个配置对应不同的数据子集,并划分为训练集(train)和验证集(validation)。
可用配置
- MGB (默认配置)
- 数据文件:
train/MGB_train.jsonlval/MGB_val.jsonl
- 数据文件:
- MAGA
- 数据文件:
train/MAGA_train.jsonlval/MAGA_val.jsonl
- 数据文件:
- MAGA-extra-BPO
- 数据文件:
extra/train/MAGA_extra_train_BPO.jsonlextra/val/MAGA_extra_val_BPO.jsonl
- 数据文件:
- MAGA-extra-roleplaying
- 数据文件:
extra/train/MAGA_extra_train_role_playing.jsonlextra/val/MAGA_extra_val_role_playing.jsonl
- 数据文件:
- MAGA-extra-self-refine
- 数据文件:
extra/train/MAGA_extra_train_self_refine.jsonlextra/val/MAGA_extra_val_self_refine.jsonl
- 数据文件:
- MAGA-extra-RLDF-CMD
- 数据文件:
extra/train/MAGA_extra_train_RLDF_CMD.jsonlextra/val/MAGA_extra_val_RLDF_CMD.jsonl
- 数据文件:
完整数据集构成说明
完整的 MAGA 数据集由两个子集(对应两个 Hugging Face 仓库)构成:
- MAGA (英文版本):即本仓库。
- MAGA-cn (中文版本):位于 https://huggingface.co/datasets/anyangsong/MAGA-cn。
每个子集都包含 6 种划分(对应上述6个配置):
- MGB:未经对齐的基线数据。
- MAGA:融合了全部4种对齐方法的完整MAGA数据。
- MAGA-extra-<alignment method>:四种单独的对齐方法数据(BPO, roleplaying, self-refine, RLDF-CMD)。
重要提示:为了进行横向比较,每个划分所使用的人类源文本是相同的。
数据字段说明
每条数据包含以下字段:
id:唯一标识文本内容的 uuid4。title:提示词中使用的文章标题。text:文本内容(人类撰写文本或机器生成文本)。domain:提示词/文本所属的领域类别(例如 Reddit)。human_source_id:人类撰写源文本的 uuid4。prompt_id:唯一标识所用提示词的 uuid4。system_prompt:生成时使用的系统提示词。user_prompt:生成时使用的用户提示词。model:生成文本的大型语言模型。temperature,top_p,top_k,repetition_penalty:文本生成的解码参数。
标签列说明:数据集中未直接包含 label 列。进行文本分类时,需根据 model 列手动添加标签:将 “human” 标记为 0,将所有其他值标记为 1。
相关资源链接
- 论文:https://www.arxiv.org/abs/2601.04633
- GitHub 仓库:https://github.com/s1012480564/MAGA
- 中文版本数据集:https://huggingface.co/datasets/anyangsong/MAGA-cn
- 角色扮演扩展数据集:https://huggingface.co/datasets/anyangsong/MAGA-ROLE-80
- 人类源文本数据集:https://huggingface.co/datasets/anyangsong/MAGA-human-source
- 预训练检测器模型:https://huggingface.co/anyangsong/MGT-Detector-RB-MAGA
- 外部泛化测试数据集:
- https://huggingface.co/datasets/anyangsong/SemEval2024-Task8-SubtaskA
- https://huggingface.co/datasets/anyangsong/COLING2025-MGT-Detection-Task1
加载方式
使用 datasets 库加载数据集:
python
from datasets import load_dataset
maga = load_dataset("anyangsong/MAGA")
引用信息
如果使用本数据集,请引用: latex @misc{song2026maga, title={MAGA-Bench: Machine-Augment-Generated Text via Alignment Detection Benchmark}, author={Anyang Song and Ying Cheng and Yiqian Xu and Rui Feng}, year={2026}, eprint={2601.04633}, archivePrefix={arXiv}, primaryClass={cs.CL}, url={https://arxiv.org/abs/2601.04633}, }