juletxara/xstory_cloze
收藏数据集概述
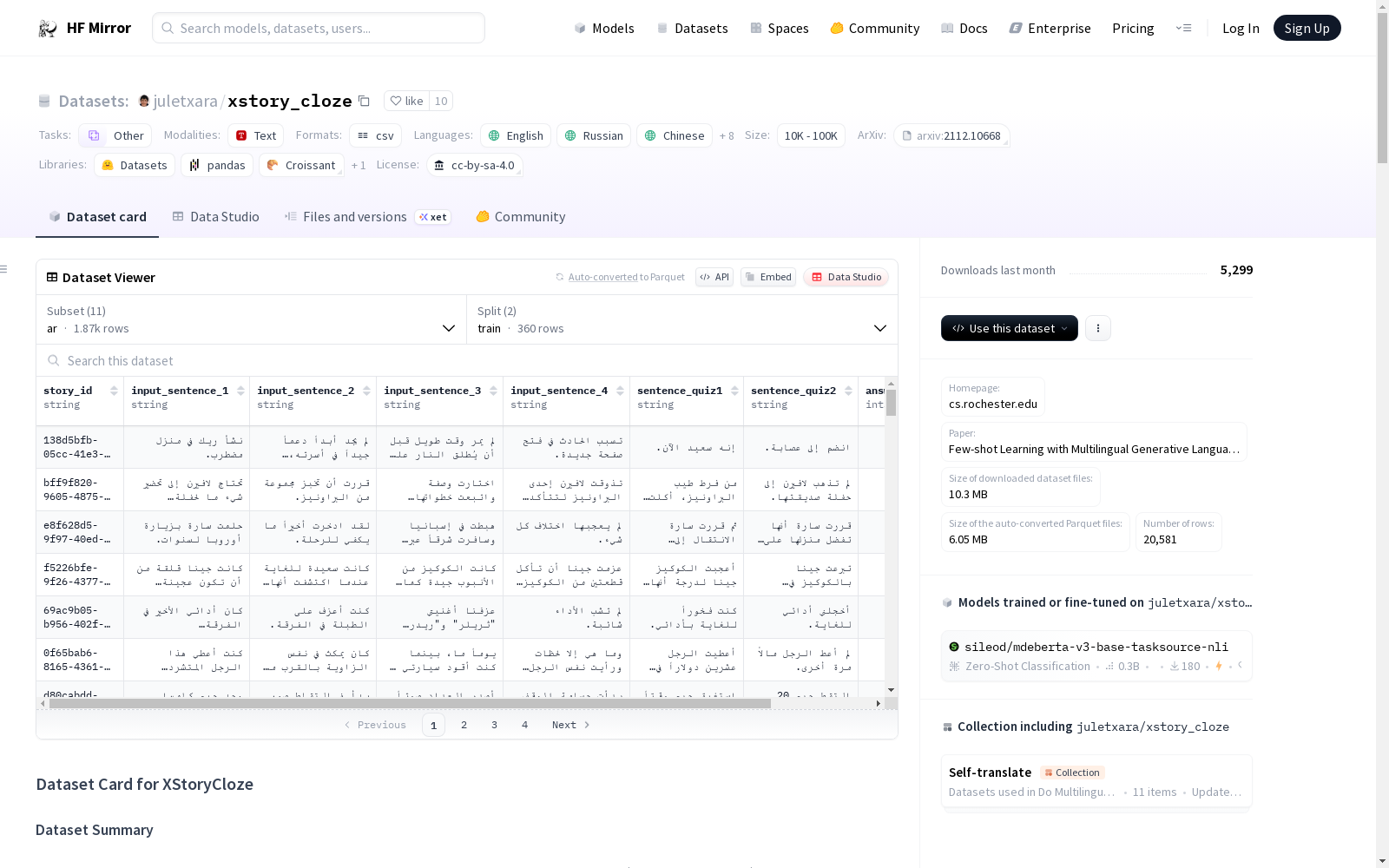
数据集名称: XStoryCloze
数据集描述: XStoryCloze 包含由Meta AI发布的专业翻译版本的英语StoryCloze数据集(2016年春季版本)到10种非英语语言。
支持任务: 常识推理
语言: 英语(en)、俄语(ru)、简体中文(zh)、西班牙语(es)、阿拉伯语(ar)、印地语(hi)、印度尼西亚语(id)、泰卢固语(te)、斯瓦希里语(sw)、巴斯克语(eu)、缅甸语(my)
许可证: CC BY-SA 4.0
多语言性: 多语言
数据集大小: 1K<n<10K
数据集结构
数据实例:
story_id: 故事ID,数据类型为字符串。input_sentence_1到input_sentence_4: 故事的四个陈述,数据类型为字符串。sentence_quiz1和sentence_quiz2: 故事的两个可能的延续,数据类型为字符串。answer_right_ending: 正确的可能结局,数据类型为int32。
数据分割:
- 每个语言版本的数据集被分为训练集和测试集,分别包含360和1511个示例。
数据集创建
语言创建者: 发现(found)和专家生成(expert-generated)
注释创建者: 发现(found)
源数据集: 扩展自story_cloze
数据集使用注意事项
许可证: 数据集根据CC BY-SA 4.0许可证开放源代码。
引用信息:
@article{DBLP:journals/corr/abs-2112-10668, author = {Xi Victoria Lin and Todor Mihaylov and Mikel Artetxe and Tianlu Wang and Shuohui Chen and Daniel Simig and Myle Ott and Naman Goyal and Shruti Bhosale and Jingfei Du and Ramakanth Pasunuru and Sam Shleifer and Punit Singh Koura and Vishrav Chaudhary and Brian OHoro and Jeff Wang and Luke Zettlemoyer and Zornitsa Kozareva and Mona T. Diab and Veselin Stoyanov and Xian Li}, title = {Few-shot Learning with Multilingual Language Models}, journal = {CoRR}, volume = {abs/2112.10668}, year = {2021}, url = {https://arxiv.org/abs/2112.10668}, eprinttype = {arXiv}, eprint = {2112.10668}, timestamp = {Tue, 04 Jan 2022 15:59:27 +0100}, biburl = {https://dblp.org/rec/journals/corr/abs-2112-10668.bib}, bibsource = {dblp computer science bibliography, https://dblp.org} }