samuellachisa/tenacious-bench
收藏Hugging Face2026-05-02 更新2026-05-03 收录
下载链接:
https://hf-mirror.com/datasets/samuellachisa/tenacious-bench
下载链接
链接失效反馈官方服务:
资源简介:
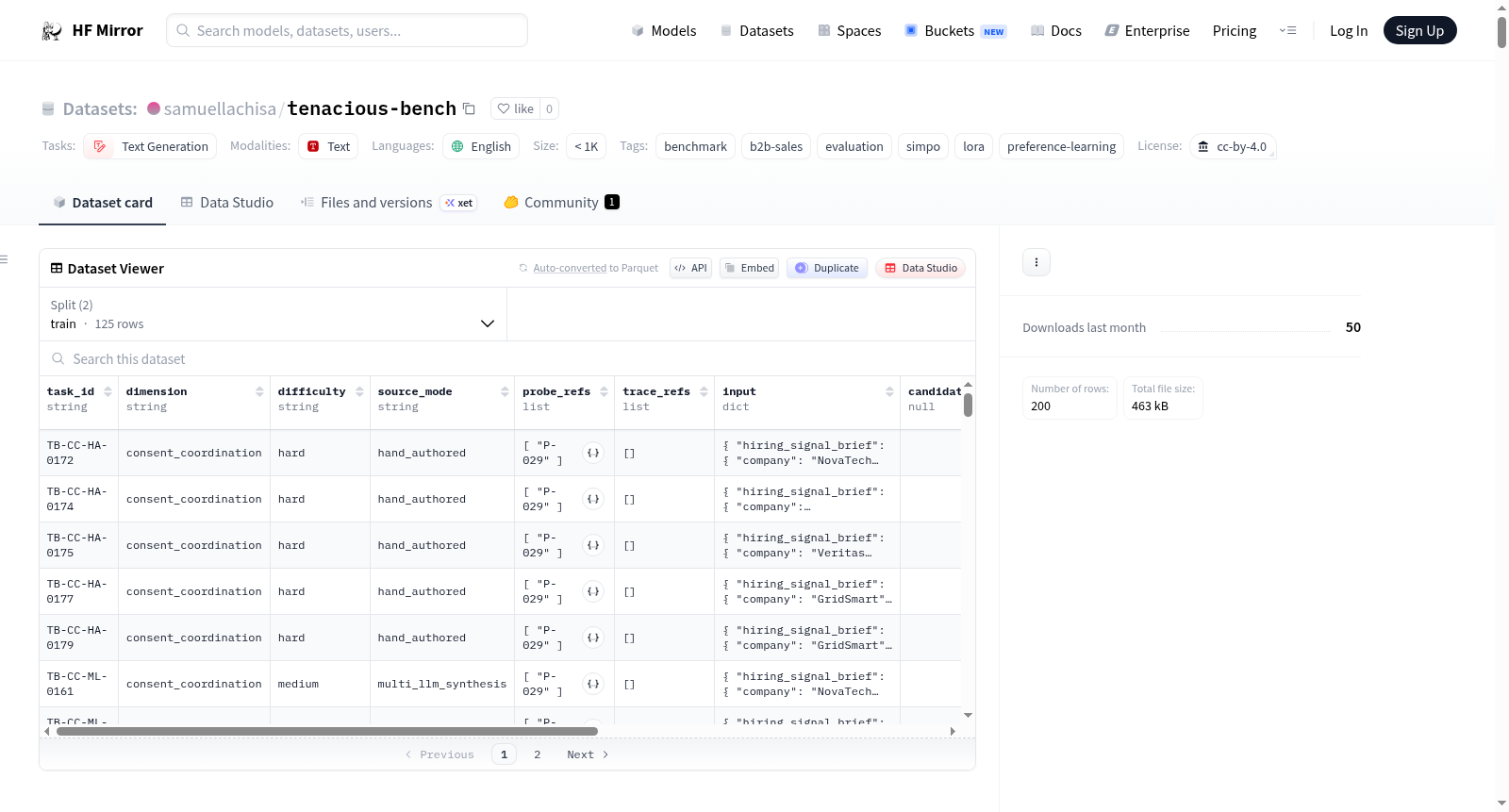
Tenacious-Bench v0.1 是一个专门用于评估B2B销售代理的基准测试。它测量了现有基准测试(如τ²-Bench零售、WebArena、BrowseComp)未涵盖的五个关键维度:信号基础、能力诚实、语气保持、同意优先协调和差距框架。这些维度直接映射到Tenacious Conversion Engine(第10周证据)中观察到的最高成本故障模式。数据集包含250个任务,分为训练(125个)、开发(75个)和保留(50个)三个部分,并经过污染检查和模式验证。
Tenacious-Bench v0.1 is a specialized benchmark for B2B sales agent evaluation. It measures five critical dimensions that existing benchmarks (τ²-Bench retail, WebArena, BrowseComp) do not capture: signal grounding, capacity honesty, tone preservation, consent-first coordination, and gap framing. These dimensions map directly to the highest-cost failure modes observed in the Tenacious Conversion Engine (Week 10 evidence). The dataset includes 250 tasks across these dimensions, partitioned into train (125), dev (75), and held_out (50) sets, with contamination checks and schema validation ensuring data integrity.
提供机构:
samuellachisa
搜集汇总
数据集介绍
构建方式
Tenacious-Bench v0.1 是一个专为 B2B 销售智能体评估而设计的基准测试数据集,由 250 个经过模式验证的任务组成。该数据集通过四种互补的构建方式生成:从真实智能体交互轨迹中提取关键场景、基于规则的生成脚本进行程序化扫描、利用多大型语言模型(如 DeepSeek 与 Qwen3)进行合成生成,以及由领域专家手工编写。所有任务均遵循严格的 JSON 模式规范,并经过双重标注验证(一致性达 90%,Cohen's κ=0.78),同时通过 n-gram 和余弦相似度检查确保与先前追踪数据无污染。数据集被划分为训练集(125 个)、开发集(75 个)和留存测试集(50 个),以支持模型的训练、调优与公平评估。
特点
该基准测试的核心特色在于聚焦现有评估体系(如 τ²-Bench 零售版、WebArena、BrowseComp)所忽视的五项关键维度:信号依据、容量诚实性、语气保持、同意优先协调与差距框架。每个维度直接映射至 B2B 销售流程中成本最高的失败模式,例如容量过度承诺(每 100 条线索损失 821 美元)和未经验证的断言(每 100 条线索损失 383 美元)。任务难度分为简单、中等、困难与对抗四种层级,并提供混合评分架构,结合确定性的规则检查(如禁止用语检测、升级模式验证)与语义型大语言模型评判,确保评估结果既高效又具备深度语义理解能力。
使用方法
使用者可通过命令行接口高效地执行评估。安装依赖后,使用 `scoring_evaluator.py` 并指定单个任务文件(`--task`)或批量任务目录(`--batch-dir`),同时通过 `--output` 参数传入待评估智能体的回复文本。系统将输出结构化的评分结果,包括每个检查点的通过/失败状态、归一化分数以及是否达到通过阈值。若需更深层的语义评判,可通过 `--llm-judge` 启用大语言模型评估器。评估结果支持以 JSON 格式输出,便于后续流水线处理,退出码(0 表示通过,1 表示失败)可无缝集成至持续集成流程中。
背景与挑战
背景概述
Tenacious-Bench v0.1 发布于2025年,由研究者 Samuel Lachisa 主导,专注于评估B2B销售场景下的对话智能体。其核心研究问题在于,现有基准如τ²-Bench零售版、WebArena及BrowseComp未能捕捉企业销售代理中的关键失败模式。该数据集填补了这一空白,通过衡量信号接地、容量诚实、语气保持、以同意为先的协调及差距框架五个维度,直接映射到高成本的销售转化失败场景。Tenacious-Bench 对偏好学习、大型语言模型评估及B2B销售自动化领域具有重要影响力,为构建更可靠、更符合商业伦理的销售代理提供了标准化评估工具。
当前挑战
该数据集所解决的领域问题主要在于,现有基准无法评估销售代理在高压、多轮对话中的关键能力,如避免过度承诺、基于弱信号做出合理推断、在客户施压下保持专业语气、先征得同意再行动以及将竞争差距转化为建设性提问。构建过程中的挑战则包括:设计可操作的评分准则以兼顾规则判断与语义理解,确保任务生成覆盖四个难度级别并避免数据泄露,以及实现零人工参与的混合评分架构。此外,如何通过合成数据生成高质量偏好对以训练SimPO模型,也是构建中的一大技术难点。
常用场景
经典使用场景
在企业级B2B销售对话智能体的评估领域,该数据集脱颖而出,专门用于衡量智能体在五个关键维度上的表现:信号接地准确性、容量诚实性、语气保持能力、同意优先协调以及差距框架构建。与传统基准不同,它聚焦于那些高频且高成本的失败模式,为评估销售对话系统提供了精细化的检测框架。研究者和工程师可通过预定义的JSON任务文件与响应评分器,精准定位智能体在销售场景中的薄弱环节,从而推动系统的定向优化。
解决学术问题
该数据集填补了现有零售或通用浏览基准无法触及的学术空白,系统性地解决了B2B销售对话智能体中最为棘手的评估难题。通过量化信号接地、容量诚实等维度的失败成本,它为探究对话系统在真实商业交互中的信任建立、信息谦逊表达及协作意愿激发提供了实证基础。其意义在于将抽象的对话质量转化为可测量的高成本失败模式,推动了对话评估从通用能力向专业场景风险控制的范式转移。
衍生相关工作
围绕该数据集衍生了一系列关键工作,包括基于SimPO算法与LoRA微调训练的偏好对齐适配器、用于无人类干预评分的混合评分器、以及验证智能体回答一致性的污染检测工具。此外,研究团队还构建了包含30个探测探针的失败模式分类法与经济学分析,并开发了在训练后验证修复效果的自动监测协议。这些衍生工作共同构成了一个从数据生成、模型训练到部署监控的完整智能体保障体系。
以上内容由遇见数据集搜集并总结生成


