LieUr/Qwen2-0.5B-Instruct_csqa_oai_contrastive
收藏Hugging Face2026-04-30 更新2026-05-03 收录
下载链接:
https://hf-mirror.com/datasets/LieUr/Qwen2-0.5B-Instruct_csqa_oai_contrastive
下载链接
链接失效反馈官方服务:
资源简介:
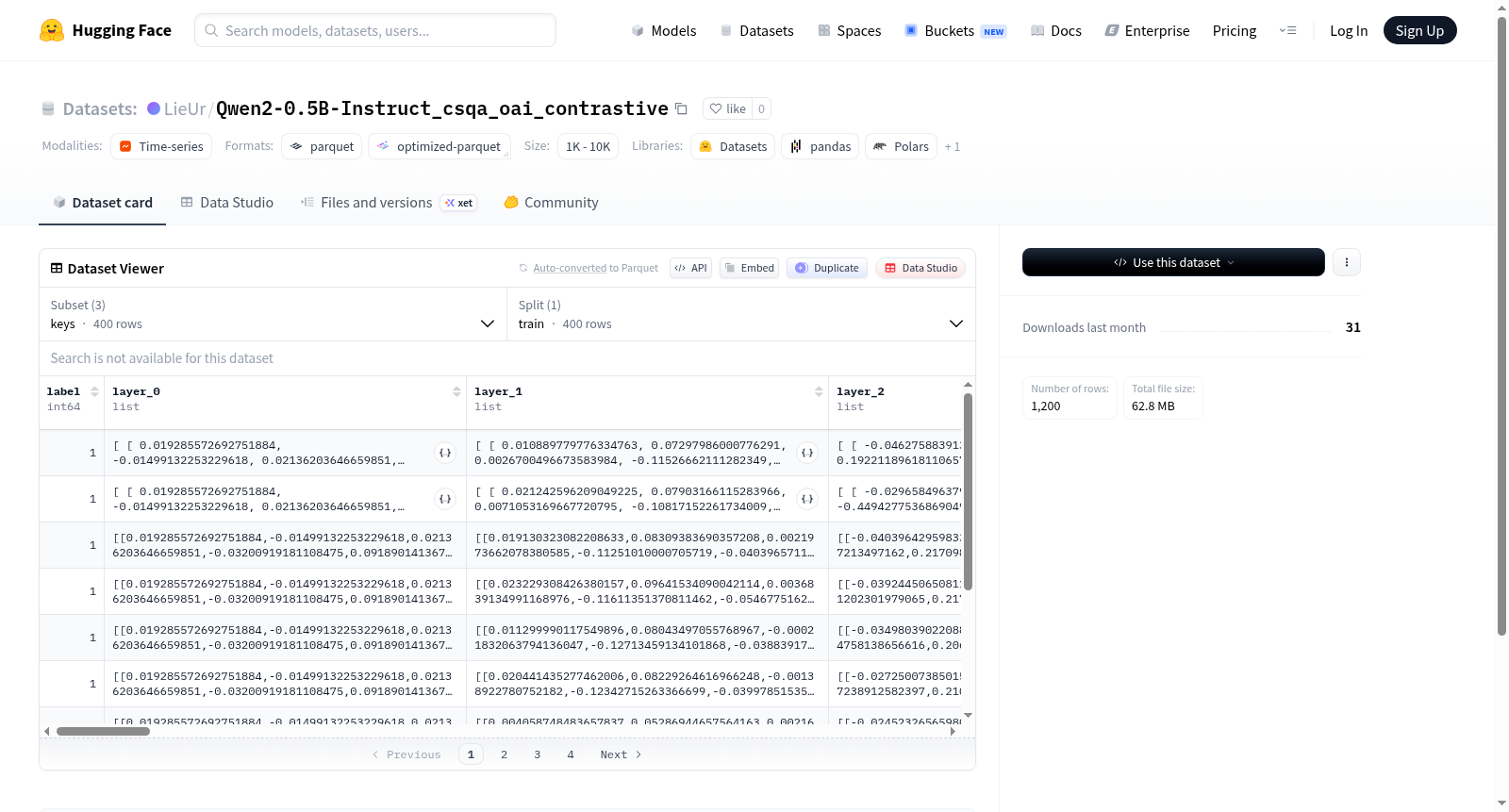
该数据集包含三个配置:keys、residuals和values,每个配置有400个训练示例。特征包括一个标签(int64类型)和24个层(layer_0到layer_23),其中keys和values配置的每个层是float32类型的列表的列表,而residuals配置的每个层是float32类型的列表。数据集可能用于机器学习模型(如Transformer)的内部表示分析或相关任务,但具体用途和内容未在README中详细描述。
This dataset includes three configurations: keys, residuals, and values, each with 400 training examples. Features consist of a label (int64 type) and 24 layers (layer_0 to layer_23), where keys and values configurations have each layer as a list of lists of float32, while residuals configuration has each layer as a list of float32. The dataset may be used for internal representation analysis of machine learning models (e.g., Transformers) or related tasks, but specific purposes and content are not detailed in the README.
提供机构:
LieUr
搜集汇总
数据集介绍
构建方式
该数据集基于Qwen2-0.5B-Instruct模型在CommonSenseQA(CSQA)数据集上通过对比学习(OAI contrastive)范式构建而成。具体而言,它提取了模型在处理常识推理任务时每一层的隐藏状态,并按照三种配置进行组织:keys、residuals和values。keys和values分别对应注意力机制中的键和值矩阵的输出,residuals则记录了每层残差连接后的特征。每种配置均包含从第0层到第23层的激活向量,且每层特征维度均为浮点型向量列表,共计400条训练样本。这种多粒度、多层的设计使得研究者能够深入探究模型内部不同组件在推理过程中的表征演化。
使用方法
用户可通过HuggingFace datasets库直接加载该数据集,并指定需要的配置名称(keys、residuals或values)。加载后,每个样本包含一个整数标签以及layer_0至layer_23共24个浮点型向量字段。对于keys和values配置,每个字段是一个二维浮点列表,代表该层的多注意力头输出;对于residuals配置,则为一维浮点向量。数据集仅包含训练集划分,用户可根据研究目标选用单层或多层特征进行后续分析。典型的使用场景包括线性探针分类、相似度计算以及模型内部表示的对比分析。
背景与挑战
背景概述
Qwen2-0.5B-Instruct_csqa_oai_contrastive数据集诞生于大型语言模型可解释性研究蓬勃发展的背景下。该数据集由研究人员基于Qwen2-0.5B-Instruct模型构建,旨在通过对比学习范式探索模型在常识推理任务(CSQA)中的内部表征机制。其核心研究问题聚焦于如何从模型中间层的激活值、残差流等维度捕捉语义决策路径,为理解大语言模型的推理过程提供量化分析工具。作为连接模型内部状态与外部行为的桥梁,该数据集对揭示网络层级间信息流动规律、推动可解释人工智能领域发展具有重要意义。
当前挑战
该数据集面临的核心挑战源于语言模型内在的“黑箱”特性:首先,模型内部24层神经网络的高维激活数据(每层均含400个样本的浮点向量)使得特征与最终决策之间的因果链难以直接剥离;其次,对比学习框架要求精心设计正负样本对以捕捉语义边界,但常识推理中蕴含的模糊性与多义性显著增加了有效对比信号的构建难度;此外,数据采集过程中需平衡模型行为保真度与计算资源限制,如何在保持400样本规模的同时确保覆盖多样的推理失败模式,成为制约数据集效用的关键瓶颈。
常用场景
经典使用场景
在大型语言模型的可解释性研究中,Qwen2-0.5B-Instruct_csqa_oai_contrastive数据集为探究Transformer内部表征的层级演化提供了宝贵资源。该数据集记录了Qwen2-0.5B-Instruct模型在CommonSenseQA(CSQA)任务中,经过OpenAI对比学习微调后,各隐藏层(layer_0至layer_23)的键、残差和值三种中间表示。研究者可通过这些逐层激活向量,追踪模型如何从输入词嵌入逐步构建出具有常识推理能力的语义空间,从而揭示对比学习如何塑造模型内部的注意力分配与知识提炼过程。该数据集特别适合分析对比学习范式下,模型在多头注意力层中如何通过键值对互动实现正负样本的区分,为理解语言模型的常识推断机制提供了细粒度的神经层面视角。
解决学术问题
该数据集的核心贡献在于解决了对比学习增强型语言模型内部机制难以量化的学术难题。传统评估方法仅关注模型输出正确率,无法解释对比学习损失函数如何通过拉近语义相似样本、推开无关样本的方式重构隐藏状态空间。借助本数据集,研究者可以量化分析对比学习微调前后,模型在不同层级上对常识语义边界的修正程度,例如验证‘负样本难例挖掘’是否在中间层引发了更强烈的概率分布重构。此外,它填补了小型预训练模型(0.5B参数级别)在指令微调背景下可解释性研究的空白,为后续建立对比学习强度与模型推理鲁棒性之间的理论关联奠定了数据基础。这些发现对于设计更高效的对比学习策略具有方法论层面的指导意义。
实际应用
在实际应用中,该数据集可服务于语言模型安全性与可靠性评估工程。例如,通过分析各层级残差流的变化,工程师能够定位模型对对抗性常识问答的攻击脆弱层,从而设计针对性的防御机制,如在特定层插入保护性正则化项。同时,数据集中的键和值特征可被用于压缩或蒸馏模型,通过对比原始与微调模型的中间表征差异,筛选出对常识推理最关键的神经元连接,实现参数量减少下的性能保持。在对话系统开发中,这些数据还能帮助优化冷启动场景下的知识注入流程,利用层级表征差异自动判断模型何时需要外部常识知识增强,促进人机交互中回答的合理性与一致性。
数据集最近研究
最新研究方向
在大语言模型可解释性与安全对齐领域,Qwen2-0.5B-Instruct_csqa_oai_contrastive数据集聚焦于揭示模型内部表示机制的对比分析。该数据集基于Qwen2-0.5B-Instruct模型在常识问答任务上的激活状态,通过记录24个Transformer层的残差流、键与值向量,为研究模型如何编码与推理常识知识提供了精细化的神经表征快照。当前前沿方向集中在通过对比学习范式探索模型在一致与矛盾样本间的表征差异,以理解模型推理的鲁棒性和潜在偏见。这一研究方向与近年来对于AI安全性与对齐的热点事件紧密相联,例如通过激活操控实现模型行为的细粒度控制,以及利用隐藏状态诊断模型中的事实性与安全性缺陷。该数据集的独特之处在于其多层、多组件的结构设计,使得研究者能够深入不同Transformer子空间,分析语义信息在计算图中的演化路径,从而为构建更透明、可干预的下一代大语言模型奠定实证基础。
以上内容由遇见数据集搜集并总结生成


