flax-sentence-embeddings/stackexchange_titlebody_best_voted_answer_jsonl
收藏Hugging Face2022-07-11 更新2024-03-04 收录
下载链接:
https://hf-mirror.com/datasets/flax-sentence-embeddings/stackexchange_titlebody_best_voted_answer_jsonl
下载链接
链接失效反馈官方服务:
资源简介:
该数据集是从Stack Exchange网络自动提取的问题和答案(Q&A)对集合,涵盖了从3D打印、经济学到Raspberry Pi或Emacs等多个领域的社区。每个问题都与最高评分的答案相对应,形成了一个平行语料库。数据集主要用于训练句子嵌入,特别是在对比学习设置中。数据集结构详细,每个数据样本包括问题标题和主体以及最高评分的答案。此外,数据集根据不同的社区进行了分割,每个社区都有特定数量的Q&A对。
提供机构:
flax-sentence-embeddings
原始信息汇总
数据集概述
名称: StackExchange
语言: 主要为英语(en)
许可证: CC-BY-NC-SA-4.0
多语言性: 多语言
任务类别: 问答(Closed-Domain QA)
数据集来源: 原始数据
数据集大小: 未知
数据集详细信息
数据集结构
-
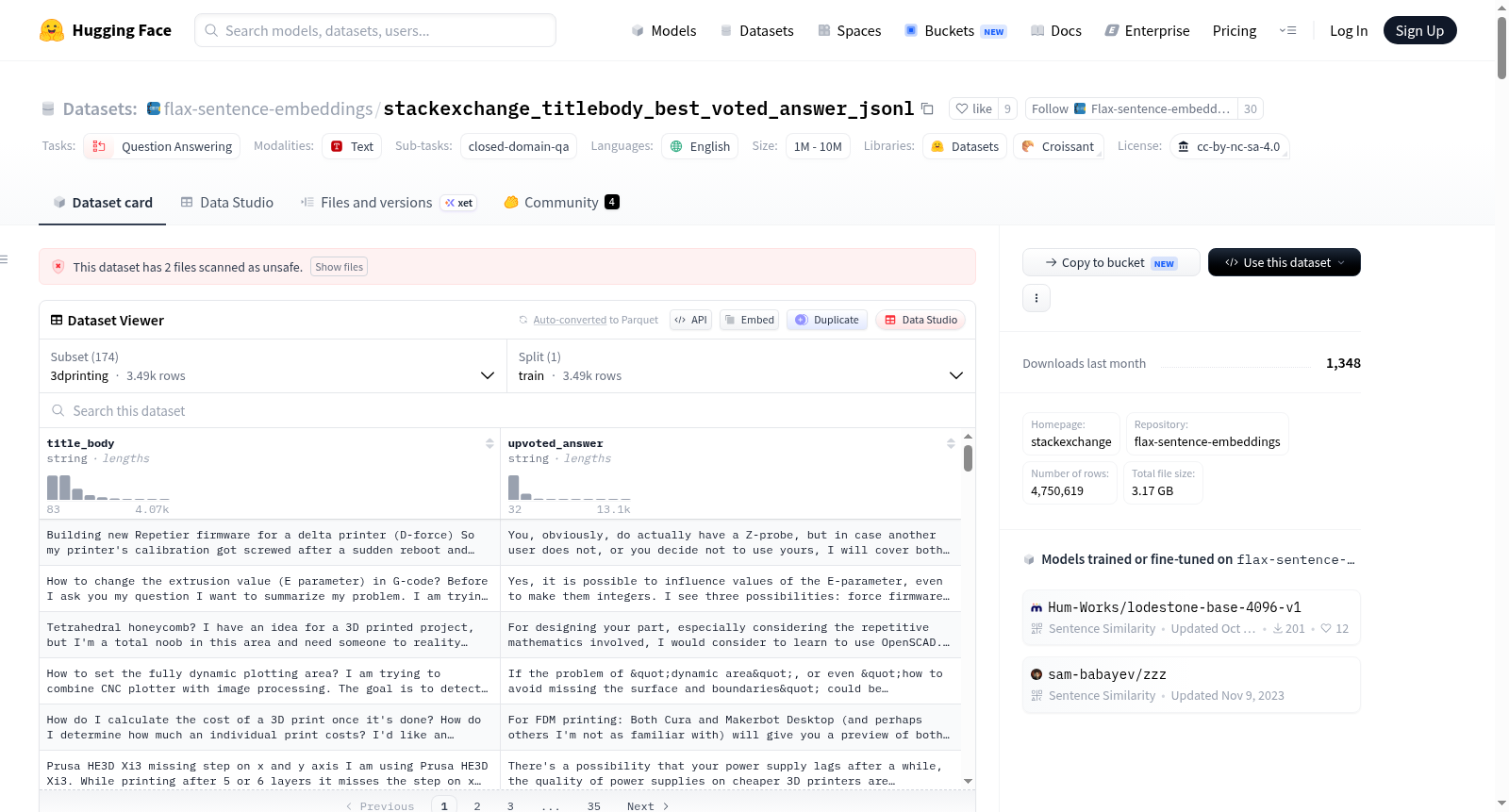
数据实例: 每个数据样本包含以下字段:
title_body: 问题的标题和正文合并。upvoted_answer: 最高票答案的正文。
-
数据字段:
title_body: 包含问题的标题和正文。upvoted_answer: 包含最高票答案的正文。
-
数据分割: 数据集根据不同的社区频道进行分割,每个分割包含的配对数量不同,例如:
- apple: 92,487 对
- english: 100,640 对
- codereview: 41,748 对
- ...
- total: 4,750,619 对
数据集创建
-
采集理由: 主要用于句子嵌入训练,利用对比学习设置,模型训练以关联每个句子与其对应的多个提议中的配对。
-
源数据: 数据来源于Stack Exchange的转储。
-
初始数据收集和规范化: 从数学社区收集数据,过滤标题或正文长度低于20个字符的问题,以及正文长度超过4096个字符的问题。提取最高票答案时,仅考虑票数差距至少为100票的配对。
-
源语言生产者: 问题和答案由Stack Exchange社区的开发者编写。
附加信息
-
许可证信息: 请参阅https://archive.org/details/stackexchange。
-
引用信息:
@misc{StackExchangeDataset, author = {Flax Sentence Embeddings Team}, title = {Stack Exchange question pairs}, year = {2021}, howpublished = {https://huggingface.co/datasets/flax-sentence-embeddings/}, }
-
贡献者: Flax Sentence Embeddings团队。
搜集汇总
数据集介绍
构建方式
该数据集源自Stack Exchange网络,通过自动抽取各社区中问题与最佳答案对构建而成。具体而言,从Stack Exchange的公开数据转储中收集原始数据,筛选出标题或正文长度超过20字符且正文不超过4096字符的问题,并确保每个问题对应的最佳答案与次佳答案之间至少存在100票的差距,从而提取出高质量的问题-答案对。最终形成包含约475万对的平行语料库,覆盖从3D打印到经济学等众多领域。
特点
数据集以社区为单位进行分割,每个子集对应Stack Exchange网络中的一个特定频道,如apple、english、mathoverflow等,总计超过100个社区。每个样本包含两个字段:title_body(问题标题与正文的拼接)和upvoted_answer(得票最高的答案正文)。这种结构使得数据集既适用于跨领域的通用问答任务,也便于针对特定领域进行细粒度分析。其多领域覆盖特性为训练鲁棒的句子嵌入模型提供了丰富的对比学习素材。
使用方法
该数据集主要面向句子嵌入模型的对比学习训练。用户可通过HuggingFace Datasets库加载,指定社区名称(如'apple')获取相应子集。每个样本可直接用作正样本对(问题与最佳答案),在训练中与负样本(来自其他问题或社区)组合,构建三元组损失或对比损失。数据集遵循CC-BY-NC-SA 4.0许可,适用于非商业研究场景,推荐在引用时注明Flax Sentence Embeddings团队的工作。
背景与挑战
背景概述
在自然语言处理领域,句向量表示学习是语义理解的核心任务之一,其质量高度依赖于大规模、高质量且覆盖多领域语料的支撑。由Flax Sentence Embeddings团队于2021年构建的Stack Exchange问答语料库,正是为应对这一需求而生。该数据集从Stack Exchange网络(涵盖Stack Overflow等50余个技术社区)中自动提取问题与最佳答案的配对,累计包含约475万对样本,覆盖从3D打印到经济学等广泛领域。其核心研究问题在于:如何利用社区驱动的结构化问答数据,通过对比学习范式高效训练通用句向量模型。这一资源的发布,为句嵌入模型的预训练提供了跨领域、高质量的自然语言平行语料,显著推动了语义匹配与信息检索技术的研究进展。
当前挑战
该数据集面临的核心挑战体现在三个维度。其一,领域问题层面,句向量模型需要从问答对中学习到语义等价关系,但Stack Exchange社区中问题表述的多样性(如数学公式、代码片段混杂)与答案质量的波动性,使得模型难以稳定捕捉深层语义关联。其二,数据构建过程中,自动提取机制面临噪声干扰:尽管设置了20至4096字符的长度阈值及100票的答案分差过滤条件,但低质量或偏离主题的答案仍可能混入,同时跨社区的语言风格差异(如Stack Overflow的技术严谨性与Worldbuilding的创意发散性)加剧了数据一致性维护的难度。其三,多领域覆盖虽扩展了语料广度,却导致不同子集间的样本分布极不均衡(如AskUbuntu包含26.7万对,而Conlang仅334对),这对模型的泛化能力与训练效率构成严峻考验。
常用场景
经典使用场景
该数据集以Stack Exchange网络中海量的问答对为基石,将每个问题与其获得最高票数的答案精心配对,构建了一个规模宏大、领域多元的平行语料库。其最经典的使用场景在于训练句子嵌入模型,通过对比学习范式,让模型在海量候选句子中精准识别出与给定问题语义匹配的答案,从而学习到高质量的句子表征。这种任务设计不仅考验模型对语义相似度的捕捉能力,还因其覆盖了从编程技术到人文社科等数十个垂直社区,使得训练出的嵌入具备卓越的跨领域泛化性能,成为自然语言处理中语义匹配与表示学习研究的标杆性资源。
衍生相关工作
该数据集的诞生催生了一系列具有影响力的后续工作。最直接的是,它被用作训练Flax Sentence Embeddings系列模型的核心语料,这些模型在语义文本相似度(STS)基准上取得了优异表现。研究者基于此数据集进一步探索了弱监督对比学习、多任务联合训练以及知识蒸馏等优化策略,衍生出如利用社区标签进行分层对比学习的方法。此外,该数据集的跨领域特性启发了关于句子嵌入中领域不变特征与领域特异特征解耦的研究,推动了可解释语义表征的发展。其在问答匹配任务上的成功,也为后续构建更大规模、更细粒度的社区问答数据集(如基于Stack Overflow的代码-文本对齐数据集)提供了方法论参考。
数据集最近研究
最新研究方向
该数据集聚焦于利用Stack Exchange社区的海量问答对,推动句子嵌入模型的对比学习研究。当前前沿方向包括基于语义相似度的跨领域问答匹配、多任务学习中的知识迁移,以及大规模预训练语言模型在技术问答场景下的微调优化。随着Stack Overflow等平台成为开发者日常知识获取的核心枢纽,该数据集在构建高效问答系统、增强对话式AI的上下文理解能力方面具有显著意义。其覆盖从编程到学术的多元领域,为探索通用型句子表征的泛化性提供了宝贵资源,同时助力于解决低资源社区中的信息检索难题,展现了社区驱动数据在自然语言处理中的深远影响。
以上内容由遇见数据集搜集并总结生成


