LottieAnimation-660K
收藏arXiv2026-04-14 更新2026-04-15 收录
下载链接:
https://lottiegpt.github.io/
下载链接
链接失效反馈官方服务:
资源简介:
LottieAnimation-660K是由清华大学团队联合多家机构构建的全球最大规模矢量动画数据集,包含66万条经过严格清洗的Lottie格式动画数据。该数据集源自互联网公开的After Effects工程文件,通过Bodymovin插件转换为标准化JSON格式,并经过冗余字段删除等优化处理,文件体积平均减少34%。数据内容涵盖UI动效、卡通插画、多图层场景动画等丰富类型,配套15M静态矢量图形辅助训练。该数据集的建立突破了传统像素视频生成模型的局限,为分辨率无关、可编辑的矢量动画生成研究提供了关键基础设施,主要应用于数字内容创作、交互设计等领域。
提供机构:
清华大学深圳国际研究生院; 清华大学·智能产业研究院; 北京智源人工智能研究院; 香港理工大学; 南京大学; 广东省人工智能与数字经济实验室(深圳)
创建时间:
2026-04-14
搜集汇总
数据集介绍
构建方式
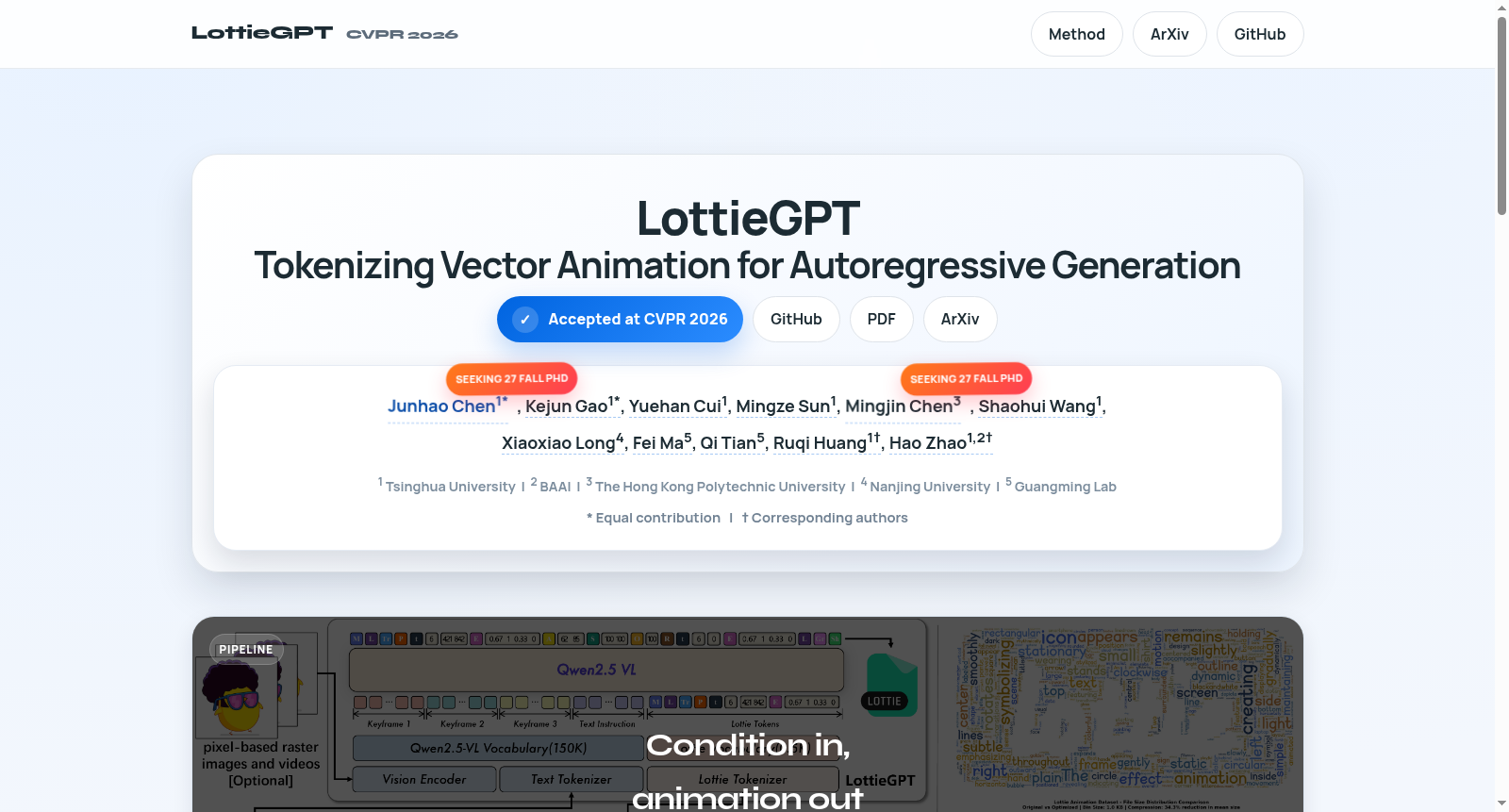
在向量动画生成领域,数据稀缺长期制约着模型发展。LottieAnimation-660K数据集通过系统化的数据收集与处理流程构建而成,其核心来源包括互联网公开的After Effects源文件与静态矢量图形资源。首先,利用Bodymovin插件将After Effects动画导出为Lottie JSON格式,这一轻量级跨平台表示支持关键帧、路径形变与颜色渐变。随后,整合了1500万静态矢量图形并统一转换为Lottie表示,以支持“先静态后动态”的渐进式训练策略。数据经过严格过滤,剔除渲染失败与视觉异常样本,并通过简化算法去除冗余字段,在保持渲染保真度的同时将序列长度压缩约34%。最终形成包含66万动画与1500万静态图形的迄今规模最大、最多样的矢量动画资源。
使用方法
该数据集为矢量动画生成研究提供了多层次的应用途径。在模型训练方面,支持两阶段渐进式学习策略:首先在静态Lottie图像上训练,掌握矢量图元与层次结构;随后引入动态动画数据,学习时间协调与运动建模。数据格式可直接用于训练自回归模型,通过专门设计的Lottie分词器将JSON结构转换为紧凑的语义对齐令牌序列。研究评估中,数据集支持构建LottieBench基准,从视觉保真度、结构正确性与语义对齐三个维度系统评估生成质量。实际应用中,生成模型可接受文本描述、参考图像或关键帧视频作为输入,输出完全可编辑的Lottie动画,适用于图标动态、UI过渡、插图卡通等多层场景动画生成任务。
背景与挑战
背景概述
LottieAnimation-660K数据集由清华大学深圳国际研究生院、清华大学人工智能研究院等机构的研究团队于2026年构建,旨在解决矢量动画生成领域长期存在的数据稀缺问题。该数据集包含66万条真实世界的Lottie动画和1500万张静态Lottie图像,是目前规模最大、多样性最丰富的矢量动画资源。其核心研究问题在于如何为自回归模型提供大规模、高质量的矢量动画训练数据,以支持从文本、图像或关键帧直接生成可编辑的、分辨率无关的矢量动画。该数据集的建立突破了传统像素视频生成模型的局限,为结构化视觉内容生成开辟了新方向,对UI/UX动效设计、教育内容制作、产品插画等专业领域产生了深远影响。
当前挑战
LottieAnimation-660K数据集面临的挑战主要体现在两个方面:在领域问题层面,矢量动画生成需解决时间协调复杂性、关键帧参数化以及运动曲线插值等难题,这些挑战超越了静态矢量图形生成,要求模型同时掌握空间构图与时间动态;在构建过程层面,研究团队遭遇了数据稀缺与质量控制的严峻考验,由于网络资源中矢量动画的稀缺性,需从After Effects源文件经Bodymovin插件转换并经过严格的渲染异常过滤、JSON结构简化和冗余字段剔除,同时通过Qwen2.5-VL生成时间对齐的文本描述,确保数据语义的一致性与训练稳定性。
常用场景
经典使用场景
在数字媒体设计与动态图形生成领域,LottieAnimation-660K数据集为向量动画的生成与理解提供了关键支撑。该数据集最经典的使用场景在于训练多模态模型从文本或图像直接生成可编辑的向量动画,例如通过LottieGPT框架,将自然语言描述转化为分层结构清晰、支持关键帧插值的Lottie格式动画。这一过程不仅实现了从像素空间到结构化向量空间的范式迁移,更使得生成内容具备无限分辨率与语义可编辑性,广泛应用于图标动态设计、界面交互动效以及卡通角色动画等场景。
解决学术问题
该数据集有效解决了向量动画生成领域长期存在的若干学术难题。首先,它填补了大规模向量动画数据资源的空白,为基于学习的生成模型提供了充足的训练样本。其次,通过引入专门的Lottie Tokenizer,将包含层次几何图元、变换属性与时间关键帧的复杂动画结构编码为紧凑的令牌序列,从而实现了对动态向量内容的自回归建模。这一创新使得生成模型能够同时处理空间构图与时间协调,克服了传统方法仅能生成静态向量图形或依赖简单插值的局限,推动了结构化数据生成研究向时序化、可编辑方向演进。
实际应用
在实际应用层面,LottieAnimation-660K数据集支撑的生成技术已深入多个产业领域。在用户界面与体验设计中,它能够自动生成轻量级、可无缝缩放的动态图标与转场动画,显著提升移动应用与网页的交互质感。在数字内容创作领域,创作者可通过文本描述快速生成插图风格的卡通动画或品牌宣传动效,大幅降低专业动画制作的门槛与时间成本。此外,该技术也为教育内容可视化、产品演示动画以及社交媒体动态素材的自动化生产提供了高效工具,体现了向量动画在跨平台、高性能渲染场景下的独特优势。
数据集最近研究
最新研究方向
在矢量动画生成领域,LottieAnimation-660K数据集的构建标志着结构化动态内容生成的重要突破。该数据集为LottieGPT等自回归模型提供了大规模、多样化的训练资源,推动了从传统像素视频生成向可编辑、分辨率无关的矢量动画生成的范式转移。当前研究前沿聚焦于设计紧凑的动画分词器,将分层几何图元、关键帧与时间动态统一编码为语义对齐的令牌序列,解决了矢量动画在格式表达、数据稀缺与时间协调方面的核心挑战。这一进展不仅强化了静态矢量图形的生成能力,更在UI动效、卡通插画等多层场景动画中展现出强大的泛化性能,为专业设计流程中的迭代优化与精准控制开辟了新路径。
相关研究论文
- 1LottieGPT: Tokenizing Vector Animation for Autoregressive Generation清华大学深圳国际研究生院; 清华大学·智能产业研究院; 北京智源人工智能研究院; 香港理工大学; 南京大学; 广东省人工智能与数字经济实验室(深圳) · 2026年
以上内容由遇见数据集搜集并总结生成


