b-mc2/sql-create-context
收藏Hugging Face2024-01-25 更新2024-03-04 收录
下载链接:
https://hf-mirror.com/datasets/b-mc2/sql-create-context
下载链接
链接失效反馈官方服务:
资源简介:
该数据集sql-create-context基于WikiSQL和Spider,包含78,577个自然语言查询、SQL CREATE TABLE语句及使用CREATE语句作为上下文的SQL查询答案。数据集通过SQLGlot工具进行数据清洗和增强,生成CREATE TABLE语句,并确保SQL查询和CREATE TABLE语句无误。此外,数据集计划进一步扩展,包括转换为不同SQL方言和支持更多上下文信息。
The dataset sql-create-context is built upon WikiSQL and Spider, comprising 78,577 natural language queries, SQL CREATE TABLE statements, and SQL query answers that use the CREATE statements as context. The dataset undergoes data cleaning and augmentation via the SQLGlot tool to generate valid CREATE TABLE statements, while ensuring the correctness of both the SQL queries and the CREATE TABLE statements. Additionally, further expansion of the dataset is planned, including converting it into different SQL dialects and supporting additional contextual information.
提供机构:
b-mc2
原始信息汇总
数据集概述
- 名称: sql-create-context
- 许可证: cc-by-4.0
- 任务类别:
- text-generation
- question-answering
- table-question-answering
- 语言: en
- 标签:
- SQL
- code
- NLP
- text-to-sql
- context-sql
- spider
- wikisql
- sqlglot
- 大小: 10K<n<100K
数据集内容
- 来源: 基于WikiSQL和Spider数据集构建。
- 示例数量: 78,577个自然语言查询、SQL CREATE TABLE语句和使用CREATE语句作为上下文的SQL查询答案。
- 目的: 为防止文本到SQL数据集中常见的列名和表名幻觉问题,特别设计用于训练文本到SQL的大型语言模型。
数据处理
- 清洗与增强: 使用SQLGlot对Spider和WikiSQL的查询进行解析,推断列数据类型,并生成CREATE TABLE语句。
- 特殊处理: 对于没有列名的查询,添加默认Id列;对于使用通用表名的查询,将其替换为特定表名。
未来计划
- 数据增强: 将查询和CREATE TABLE语句转换为不同的SQL方言。
- 上下文扩展: 支持除CREATE TABLE之外的其他信息上下文。
- 数据类型解析: 改进数据类型解析,清理如列名中的数字等问题。
引用信息
- 作者: b-mc2
- 年份: 2023
- 标题: sql-create-context Dataset
- URL: https://huggingface.co/datasets/b-mc2/sql-create-context
搜集汇总
数据集介绍
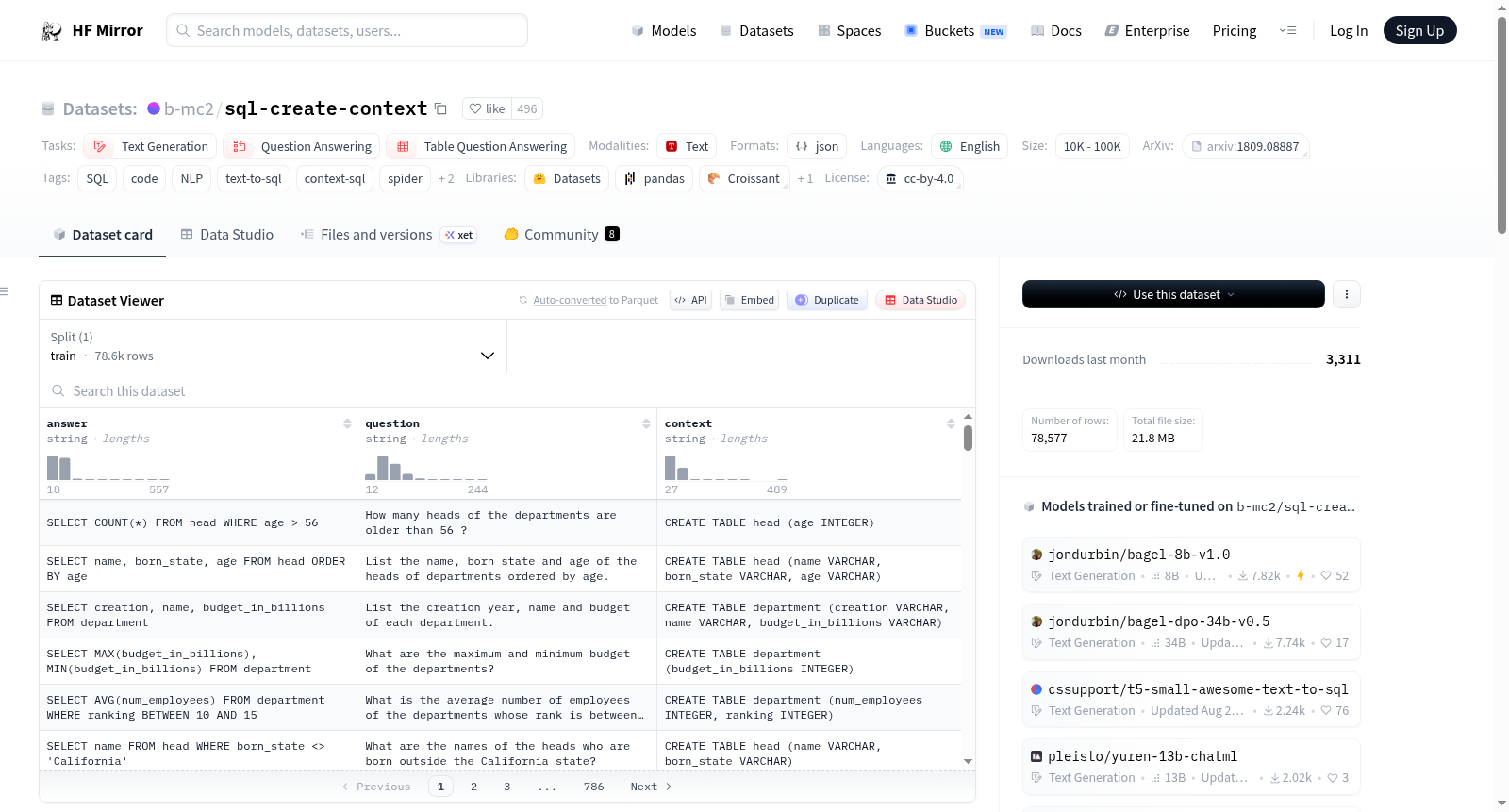
构建方式
在自然语言处理领域,文本到SQL转换任务面临模型幻觉列名与表名的挑战。本数据集以WikiSQL和Spider为基础,通过SQLGlot工具对原始查询进行解析,从中推断表结构及列数据类型。基于运算符与聚合函数的使用模式,智能推测列的数据类型,未明确类型则默认为VARCHAR。随后,系统生成对应的CREATE TABLE语句,并确保所有SQL语句语法无误。部分无列名或使用通用表名的查询经过适当调整,以增强数据的一致性与可用性。
特点
该数据集囊括了78,577条样本,每条均包含自然语言查询、CREATE TABLE语句及对应的SQL答案。其核心特色在于仅提供CREATE TABLE语句作为上下文,有效避免了实际数据行的引入,从而降低了令牌消耗并保护了敏感信息。这种设计为模型提供了精准的结构化基础,显著减少了列与表名幻觉现象。数据集覆盖多种SQL操作场景,支持复杂的跨表查询与聚合运算,为文本到SQL任务提供了高质量、多样化的训练与评估资源。
使用方法
在文本到SQL模型的研究与应用中,本数据集可直接用于训练与评估。使用者可加载数据集的三个关键字段:自然语言问题、CREATE TABLE上下文及目标SQL查询。模型接收问题与上下文作为输入,学习生成准确的SQL语句。由于上下文仅包含表结构信息,模型需依赖语义理解与逻辑推理能力,而非记忆具体数据值。该数据集适用于多种深度学习架构,特别是基于Transformer的序列到序列模型,能够有效提升模型在真实数据库环境中的泛化性能与可靠性。
背景与挑战
背景概述
在自然语言处理与数据库交互的交叉领域,文本到SQL转换任务旨在将用户自然语言查询自动转化为结构化查询语言,以提升数据访问的智能化水平。sql-create-context数据集由研究者b-mc2于2023年构建,其核心源于WikiSQL与Spider两大经典数据集,专注于通过提供CREATE TABLE语句作为上下文,为大型语言模型提供精准的数据表结构信息,从而减少模型在生成SQL查询时出现的表名与列名幻觉问题。该数据集的创建推动了文本到SQL模型在实际应用中的可靠性,尤其在处理跨领域、复杂查询时,为模型提供了必要的结构化知识基础,促进了自然语言接口与数据库系统集成研究的发展。
当前挑战
该数据集致力于解决文本到SQL转换中模型因缺乏准确数据模式信息而导致的列名与表名幻觉挑战,这直接影响查询生成的精确性与实用性。在构建过程中,挑战主要体现在数据清洗与增强方面:通过SQLGlot工具解析并推断列数据类型时,依赖运算符与聚合函数的使用模式可能导致类型推断不完美,默认VARCHAR类型可能引入偏差;同时,处理无列名查询或通用表名时需进行标准化调整,以确保CREATE TABLE语句的完整性。此外,未来扩展计划包括支持多SQL方言转换与丰富上下文类型,这些均对数据集的泛化能力与质量提出了更高要求。
常用场景
经典使用场景
在自然语言处理与数据库交互的交叉领域,sql-create-context数据集为文本到SQL转换任务提供了经典的应用场景。该数据集通过精心构建的自然语言查询、SQL CREATE TABLE语句及对应的查询答案,为模型训练提供了结构化上下文。研究者通常利用这一数据集训练大型语言模型,使其能够准确理解自然语言问题,并基于表结构信息生成精确的SQL查询,从而有效模拟真实世界中用户通过自然语言访问数据库的需求。
实际应用
在实际应用层面,sql-create-context数据集为智能数据库接口、自动化报表生成以及商业智能工具的开发提供了关键支持。企业可利用基于该数据集训练的模型,构建能够理解自然语言查询的数据分析系统,使非技术用户能够直接通过日常语言获取数据库中的信息。这种应用不仅大幅降低了数据查询的技术门槛,还提升了工作效率,尤其在需要快速响应动态业务需求的场景中展现出重要价值。
衍生相关工作
围绕sql-create-context数据集,学术界衍生了一系列经典研究工作。这些工作主要集中在改进文本到SQL模型的架构设计、增强上下文理解能力以及扩展多方言SQL支持等方面。例如,结合SQLGlot工具的研究进一步探索了SQL语句的跨数据库方言转换,而基于该数据集的模型优化则推动了如语义解析增强、少样本学习等方向的创新。这些衍生工作共同深化了对结构化查询生成机制的理解,并持续拓展了自然语言与数据库交互的技术边界。
以上内容由遇见数据集搜集并总结生成


