blenderllm-v2-polyhaven-dataset
收藏Hugging Face2026-04-11 更新2026-04-12 收录
下载链接:
https://huggingface.co/datasets/LiM-De/blenderllm-v2-polyhaven-dataset
下载链接
链接失效反馈官方服务:
资源简介:
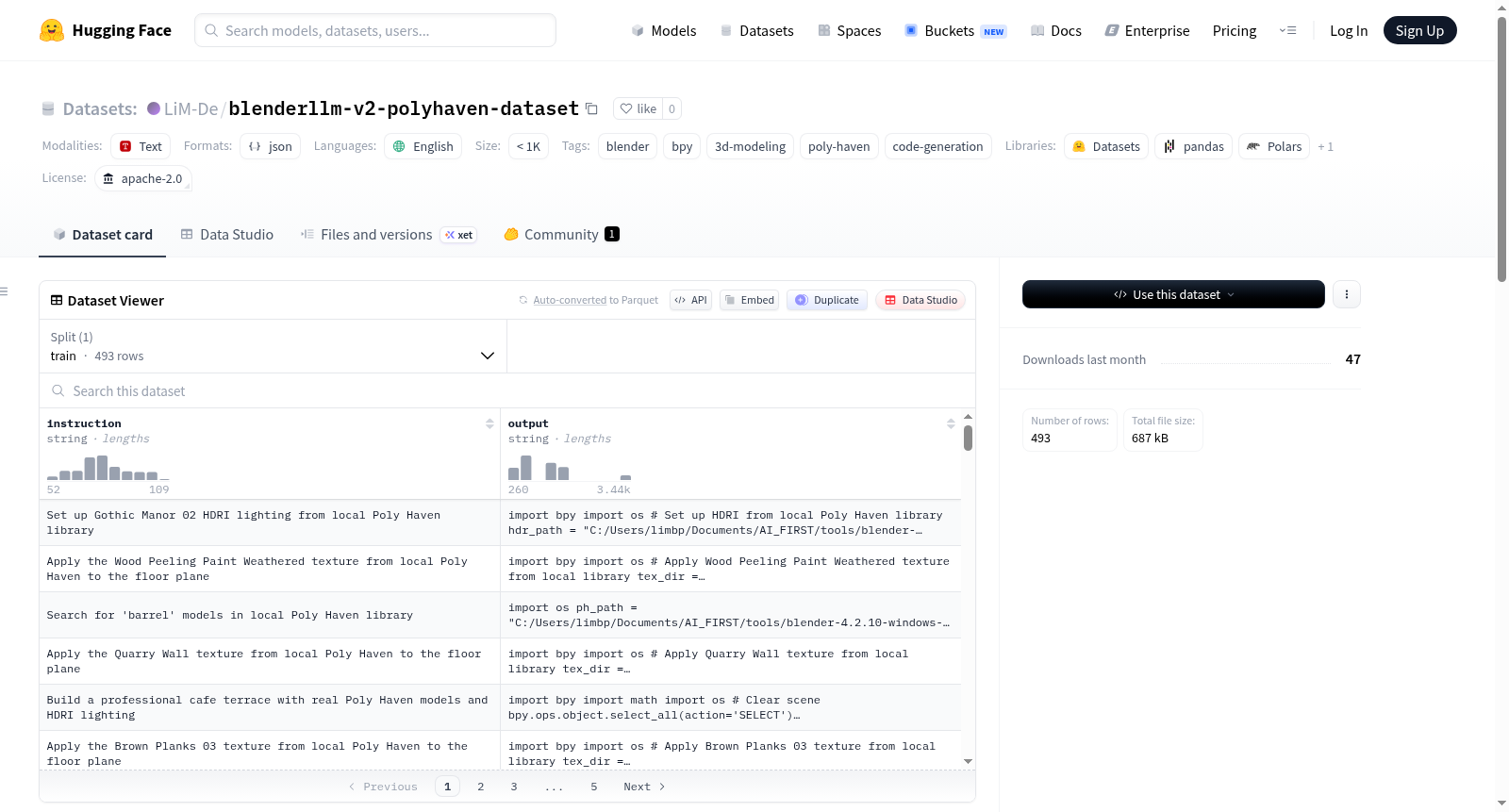
BlenderLLM v2 - Poly Haven 训练数据集是一个用于微调BlenderLLM模型的数据集,旨在利用本地Poly Haven库(包含2,194个资源)进行3D建模任务。该数据集的主要目的是扩展BlenderLLM v1的功能,使其能够从本地.blend文件加载模型(426个模型)、应用HDRIs实现真实光照(963个HDRIs)、应用带有PBR材质的纹理(805个纹理)、组合场景(结合真实资源和基本几何体)、搜索/列出可用资源、以及处理错误(如资源缺失或重叠验证)。数据集包含493个样本,分为8个类别:加载单个模型(100个样本)、加载并定位模型(100个样本)、HDRI光照(80个样本)、应用纹理(80个样本)、场景组合(32个样本)、搜索资源(20个样本)、错误处理(33个样本)以及组合场景(48个样本)。每个样本包含'instruction'和'output'两个字符串字段。数据集使用Apache-2.0许可证,语言为英语,适用于3D建模、代码生成等任务。
创建时间:
2026-04-11
搜集汇总
数据集介绍
构建方式
在三维建模与自动化脚本生成领域,BlenderLLM v2 - Poly Haven训练数据集的构建聚焦于扩展模型对本地资源库的操作能力。该数据集通过精心设计的493条样本,系统覆盖了从单一模型加载、场景光照设置到材质纹理应用及错误处理等多个关键任务。每条样本均包含自然语言指令与对应的Blender Python脚本输出,旨在教导模型理解并执行基于本地Poly Haven资源库(包含2,194项资产)的复杂操作,从而弥补了早期版本仅能生成基础几何体脚本的局限。
使用方法
该数据集主要用于对基础模型BlenderLLM(基于Qwen2.5-Coder-7B微调)进行指令跟随能力的进一步微调,以使其掌握操作本地三维资产库的技能。使用者可按照提供的训练笔记本,采用Unsloth LoRA等高效微调方法,利用数据集中‘instruction-output’配对样本进行监督学习。在实际应用中,微调后的模型能够接收如“加载一个沙发模型并应用木纹材质”之类的自然语言指令,并自动生成对应的、可执行的Blender Python代码,从而显著提升三维内容创作的自动化水平与效率。
背景与挑战
背景概述
随着三维建模与计算机图形学领域的快速发展,自动化场景生成技术逐渐成为研究热点。BlenderLLM-v2-Polyhaven数据集由FreedomIntelligence团队于近期构建,旨在扩展大型语言模型在Blender环境中的实际应用能力。该数据集聚焦于解决基于本地Poly Haven资源库的复杂三维场景合成问题,通过493条精细标注的指令-输出对,教导模型如何加载外部模型、应用高动态范围图像照明、处理纹理材质以及组合多资产场景。其核心研究在于推动代码生成模型从仅操作几何图元向集成真实世界三维资产的跨越,为智能三维内容创作工具的发展提供了关键数据支撑。
当前挑战
该数据集致力于应对三维场景自动生成中的核心挑战:如何使语言模型准确理解并操作本地化、非结构化的三维资产库,以生成可靠且视觉逼真的Blender脚本。具体构建挑战包括:确保指令覆盖资产加载、照明设置、纹理应用及错误处理等多种复杂操作;保持代码输出的语法正确性与功能一致性;处理Poly Haven库中模型、HDRIs和纹理等异构资产的统一访问接口。此外,数据规模有限与场景组合的多样性不足,也可能影响模型在开放环境下的泛化能力与鲁棒性。
常用场景
经典使用场景
在计算机图形学与三维建模领域,BlenderLLM v2 - Poly Haven数据集为基于大语言模型的代码生成任务提供了关键训练资源。该数据集的核心应用场景在于微调模型,使其能够理解并执行复杂的Blender脚本指令,特别是针对本地Poly Haven资产库中的三维模型、高动态范围图像和纹理材质进行自动化加载与场景构建。通过涵盖从单一资产加载到多元素组合的多样化样本,数据集支持模型学习如何将自然语言描述转化为可执行的Python代码,从而在Blender环境中实现高效的三维内容创作流程。
解决学术问题
该数据集主要解决了三维建模自动化中代码生成的精确性与泛化能力问题。传统方法依赖手动编写脚本,效率低下且易出错。通过提供结构化的指令-输出对,数据集助力研究如何让大语言模型理解三维资产管理的语义,如资产搜索、错误处理与场景合成,从而推动程序化内容生成、人机交互与代码合成等学术方向的发展。其意义在于弥合自然语言与专业三维软件操作之间的鸿沟,为智能创作工具的开发奠定数据基础。
实际应用
在实际应用中,该数据集赋能了智能三维设计助手系统的构建。设计师或艺术家可通过自然语言指令快速调用本地资产库,自动生成Blender场景,大幅提升工作效率。例如,在游戏开发、影视预演或建筑可视化中,用户只需描述“加载一个沙发模型并应用木纹材质”,系统便能生成相应脚本,实现资产的精准放置与材质绑定。这种应用降低了三维软件的使用门槛,促进了创意产业的数字化转型。
数据集最近研究
最新研究方向
在三维建模与计算机图形学领域,BlenderLLM v2数据集正推动基于大语言模型的自动化场景生成研究迈向新阶段。该数据集聚焦于利用本地Poly Haven资产库进行精细化指令微调,旨在突破传统仅生成基础几何体脚本的限制,实现从模型加载、材质应用到光照合成的全流程自动化。前沿探索集中于多模态指令理解与代码生成的融合,通过结合真实资产与程序化元素,提升复杂场景构建的准确性与效率。这一方向与当前AIGC在三维内容创作中的热点紧密结合,为降低专业工具使用门槛、加速数字孪生与虚拟现实内容生产提供了关键数据支撑,具有显著的工程应用价值。
以上内容由遇见数据集搜集并总结生成


