DigitalLearningGmbH/MATH-lighteval
收藏Hugging Face2025-01-15 更新2025-04-12 收录
下载链接:
https://hf-mirror.com/datasets/DigitalLearningGmbH/MATH-lighteval
下载链接
链接失效反馈官方服务:
资源简介:
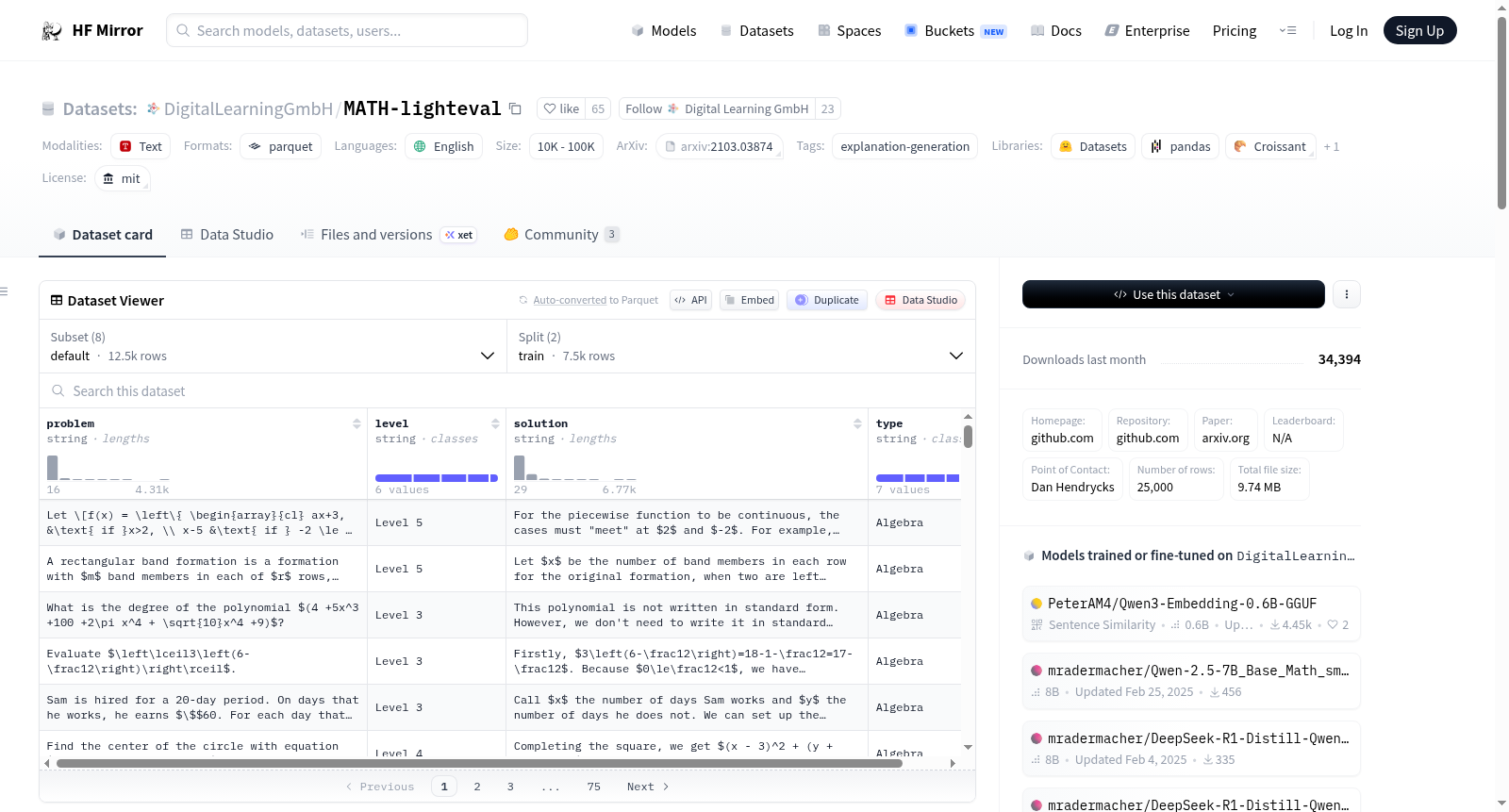
MATH数据集是一个包含数学竞赛问题的数据集,其中包括每个问题的详细解题步骤。这些问题覆盖了代数、计数与概率、几何、中级代数、数论、初等代数以及预微积分等领域,并按照问题难度分为不同的等级。数据集适用于训练模型生成数学问题的解答和解释。
The MATH dataset consists of math competition problems along with detailed step-by-step solutions. These problems span across Algebra, Counting & Probability, Geometry, Intermediate Algebra, Number Theory, Prealgebra, and Precalculus, and are categorized by difficulty levels from Level 1 to Level 5. The dataset is suitable for training models to generate answers and explanations for math problems.
提供机构:
DigitalLearningGmbH
搜集汇总
数据集介绍
构建方式
在数学推理与人工智能交叉研究的背景下,MATH数据集旨在评估模型解决数学竞赛问题的能力。该数据集由专家精心构建,源自从AMC 10、AMC 12、AIME等数学竞赛中收集的问题,每个问题均附带详细的逐步解答。数据集分为训练集和测试集,涵盖代数、几何、数论等七个学科领域,并细分为不同难度等级。本版本通过适当的构建配置,实现了与lighteval格式的无缝兼容,便于直接用于模型评估。
使用方法
使用MATH数据集时,可通过HuggingFace的datasets库加载不同配置,如default加载完整数据集,或选择algebra等特定学科子集。加载后数据可直接用于文本生成任务,例如训练模型生成解题步骤或答案。该数据集支持多学科评估,适合用于对比不同模型在数学推理上的能力。建议在加载时指定split参数以区分训练集和测试集,并利用level和type字段进行分层分析。
背景与挑战
背景概述
数学推理能力是衡量人工智能系统认知水平的重要标尺,而数学竞赛题目因其对逻辑推演与创造性思维的严苛要求,成为评估模型高阶智能的理想试金石。在此背景下,由Dan Hendrycks领衔、加州大学伯克利分校等机构研究人员于2021年创建的MATH数据集应运而生,其核心研究问题聚焦于如何系统性地评估和提升机器学习模型在复杂数学问题上的求解与解释生成能力。该数据集汇集了来自AMC 10、AMC 12、AIME等知名数学竞赛的题目,涵盖代数、几何、数论等七大子领域,总计12,500道题目,并附有详尽的逐步解答。这一开创性工作不仅为数学自然语言处理研究树立了标杆,更深刻推动了可解释人工智能与教育技术领域的发展,成为后续众多数学推理模型与评估框架的基石。
当前挑战
MATH数据集所面临的挑战首先体现在领域问题的复杂性上:数学竞赛题目要求模型具备多步逻辑推理、符号操作与抽象概念理解能力,远超传统自然语言处理任务所涉及的语义匹配或事实检索,这对模型的认知架构构成了根本性考验。其次,数据集构建过程本身亦充满挑战,包括如何确保题目难度评级的客观性——从Level 1到Level 5的划分需兼顾人类解题者的认知梯度,以及如何设计清晰且无歧义的逐步解答,使其既能作为训练目标又能作为可解释性评估的依据。此外,题目中广泛使用的LaTeX数学符号与自然语言的混合表述,为数据解析与模型输入表示带来了额外的工程与学术难题,这些挑战共同构成了当前数学推理研究领域的核心瓶颈。
常用场景
经典使用场景
MATH数据集汇聚了来自AMC 10、AMC 12、AIME等数学竞赛的题目,涵盖代数、几何、数论、计数与概率、预科数学等七大领域,每道题目均配有详尽的逐步解答与最终答案。该数据集最经典的使用场景是作为数学推理能力的基准测试集,用于评估和比较语言模型在解决复杂数学问题时的表现。研究者通过让模型生成最终答案或完整的推导过程,来衡量其数学逻辑与符号运算能力,从而推动人工智能在形式化推理领域的进展。
解决学术问题
MATH数据集有效解决了长期以来缺乏高质量、多难度层级数学推理评测基准的学术困境。传统数据集多侧重简单算术或常识问答,难以反映模型在抽象符号操作与多步推理上的真实能力。MATH通过引入从Level 1到Level 5的难度分级,并覆盖多个数学分支,使得研究者能够系统性地诊断模型在何种类型的数学问题上存在短板,进而为设计更具鲁棒性的推理架构提供了关键参照,对理解神经网络的泛化边界具有深远意义。
实际应用
在实际应用中,MATH数据集被广泛用于训练和微调能够进行数学解题与解释生成的智能教育系统。例如,基于该数据集训练的模型可嵌入在线学习平台,为学生提供分步骤的解题辅导与错误纠正,辅助个性化教学。此外,该数据集也用于开发自动化的竞赛试题解答系统,帮助教师快速生成试题解析,或为数学研究中的符号计算工具提供验证样本,从而提升教育科技与科研自动化的效率与质量。
数据集最近研究
最新研究方向
在人工智能与数学推理交叉领域,MATH数据集已成为评估大语言模型符号推理与逐步解题能力的关键基准。当前前沿研究聚焦于利用该数据集的多样化难度等级与分科配置,探索模型在代数、几何、数论等子领域的泛化表现,尤其关注从答案生成迈向可解释的推导过程建模。结合大模型在数学竞赛题上的突破性进展,如GPT-4与Claude等模型在AMC/AIME级别问题中的表现,MATH-lighteval的轻量化格式正推动高效评估框架的构建,支持模型在有限资源下实现鲁棒性测试。这一方向不仅揭示了当前模型在复杂逻辑链条与多步推理上的短板,也为教育科技中自适应学习系统的智能辅导提供了数据驱动的优化路径,其影响已延伸至神经符号系统与可解释AI的范式融合。
以上内容由遇见数据集搜集并总结生成


