CSTBIR (Composite Sketch+Text Based Image Retrieval)
收藏arXiv2025-02-12 更新2025-02-14 收录
下载链接:
https://vl2g.github.io/projects/cstbir
下载链接
链接失效反馈官方服务:
资源简介:
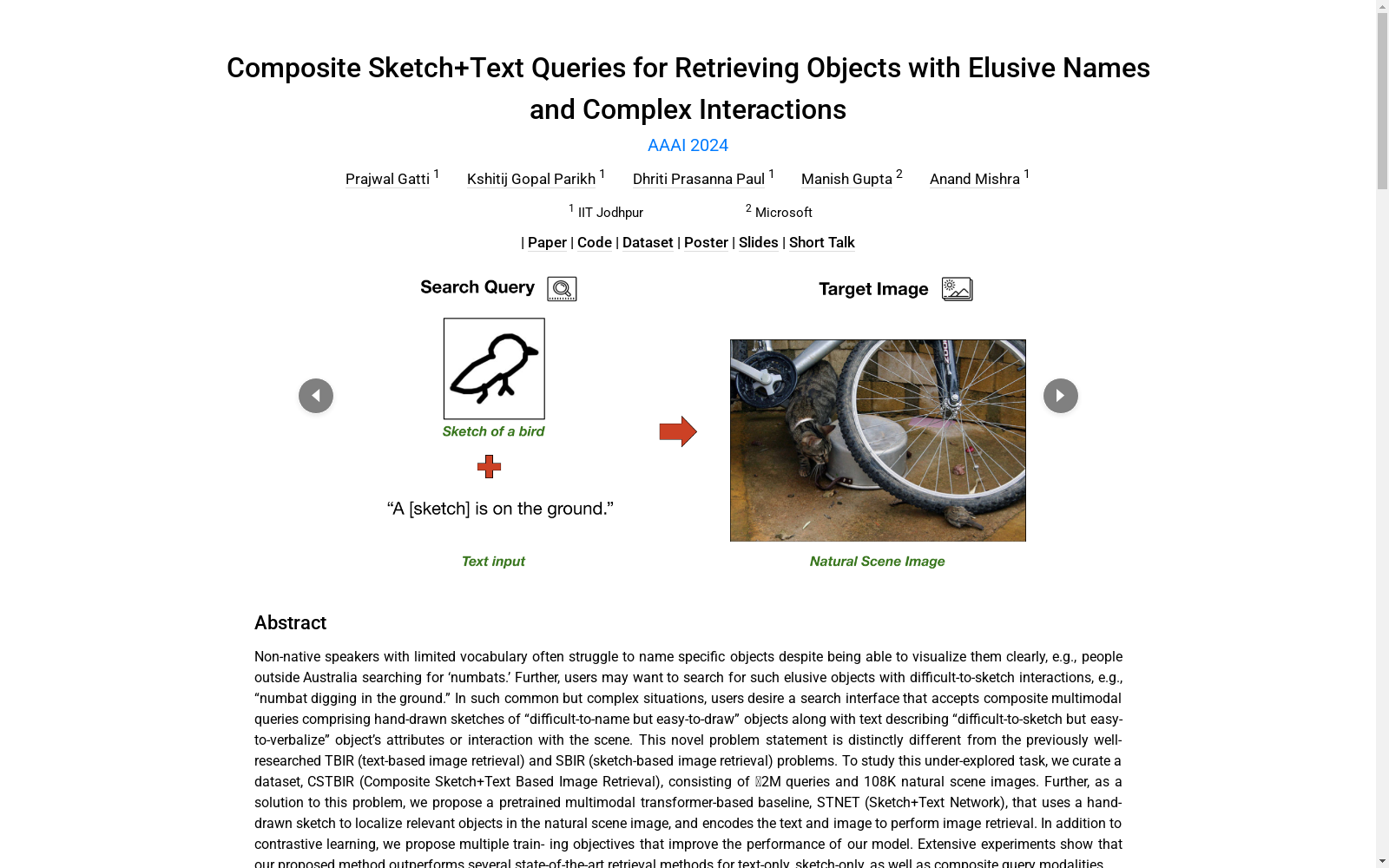
CSTBIR数据集是由印度理工学院贾伊普尔分校的研究人员创建的,包含约200万个查询和108000个自然场景图像。该数据集由手绘草图、补充的自然语言文本描述和相关自然场景图像组成,旨在解决非母语人士在搜索难以命名的特定对象时的问题。数据集中的图像和文本描述来源于Visual Genome和Quick, Draw!数据集,经过处理后形成独特的复合查询,适用于对象检测、分类和检索等任务。
The CSTBIR dataset was created by researchers from the Indian Institute of Technology (IIT) Jaipur. It contains approximately 2 million queries and 108,000 natural scene images. The dataset is composed of hand-drawn sketches, supplementary natural language text descriptions and associated natural scene images, aiming to address the challenges faced by non-native speakers when searching for specific objects that are difficult to name. The images and text descriptions in the dataset are sourced from the Visual Genome and Quick, Draw! datasets, and have been processed into unique composite queries applicable to tasks such as object detection, classification and retrieval.
提供机构:
印度理工学院贾伊普尔分校
创建时间:
2025-02-12
搜集汇总
数据集介绍
构建方式
CSTBIR数据集的构建方法是通过将自然场景图像与对应的对象草图和部分互补的自然语言文本描述相结合。自然场景图像来自Visual Genome数据集,文本描述则包含对象的属性和场景中的交互信息。草图则来自Quick, Draw!数据集,这些草图是由人类标注者在不到20秒的时间内绘制的,因此它们是粗糙的,缺乏图像的精确细节。CSTBIR数据集包含约108K张自然场景图像和约562K张草图,以及约2M个查询实例。数据集被分为训练集、验证集和测试集,其中测试集又分为Test-1K、Test-5K和Open-Category set,用于评估模型对新对象类别的泛化能力。
特点
CSTBIR数据集的特点在于它是一个复合查询数据集,每个查询实例都包含一个草图和一个文本描述,这两个模态相互补充,以描述难以命名但易于绘制的对象以及难以绘制但易于用语言描述的对象属性或场景中的交互。这种数据集设计允许用户在搜索时混合使用文本和草图,从而为复杂的搜索情境提供灵活和自然的接口。CSTBIR数据集是第一个针对这种复合查询图像检索任务的大规模数据集,它包含了丰富的对象类别、属性、关系和活动,为研究这一任务提供了宝贵的资源。
使用方法
使用CSTBIR数据集时,研究人员可以将其用于训练和评估基于草图和文本的图像检索模型。数据集中的查询实例可以用来训练模型以识别和定位图像中的对象,以及理解文本描述中的对象属性和交互。通过使用CSTBIR数据集,研究人员可以开发出能够处理复合查询的图像检索系统,这些系统可以帮助用户更有效地找到他们难以用语言描述的对象。此外,数据集中的测试集可以帮助研究人员评估他们的模型对新对象类别的泛化能力,这对于开发实用的图像检索系统至关重要。
背景与挑战
背景概述
在图像检索领域,传统的基于文本的图像检索(TBIR)和基于草图的图像检索(SBIR)已经得到了广泛的研究。然而,对于非母语者或对特定物体不熟悉的用户来说,这些系统在搜索具有“难以命名”的物体时存在局限性。例如,一个用户想要搜索“numbat在挖掘地面”,但他可能不知道“numbat”这个词,而且“挖掘地面”这个交互也很难用草图表示。为了解决这个问题,研究者们提出了一个新的任务,即复合草图+文本基于图像检索(CSTBIR),它允许用户通过结合手绘草图和文本描述来进行搜索。为了研究这个尚未充分探索的任务,研究人员创建了一个名为CSTBIR的数据集,它包含约200万条查询和10.8万张自然场景图像。此外,他们还提出了一种名为STNET的预训练多模态Transformer模型,该模型使用手绘草图来定位自然场景图像中的相关物体,并编码文本和图像以执行图像检索。
当前挑战
CSTBIR数据集和相关研究面临的主要挑战包括:1)解决领域问题:CSTBIR任务与传统的TBIR和SBIR问题有显著不同,它要求系统能够处理包含手绘草图和文本描述的复合多模态查询,这需要模型能够理解和融合两种模态的信息。2)构建过程中遇到的挑战:创建一个包含大量复合查询和自然场景图像的CSTBIR数据集是一项挑战,因为这需要收集和标注大量的草图和文本数据。此外,设计一个能够有效处理草图和文本输入的模型也是一个挑战,因为这需要模型能够理解和融合两种模态的信息,并进行图像检索。
常用场景
经典使用场景
CSTBIR数据集的经典应用场景是针对非母语者或词汇有限用户,他们在描述或搜索难以命名的对象时,往往只能通过视觉来识别,但无法准确描述或命名。例如,非澳大利亚用户搜索“袋獾”这样的对象。CSTBIR通过结合手绘草图和文本描述,为这类用户提供了一种全新的搜索方式,使得他们能够轻松地通过草图描绘“难以命名但易于绘制”的对象,并通过文本描述“难以绘制但易于口头表达”的对象属性或场景中的交互。这种复合多模态查询方式在图像检索领域是一个创新,它解决了传统文本检索和草图检索的局限性。
解决学术问题
CSTBIR数据集解决了传统文本检索(TBIR)和草图检索(SBIR)无法处理的多模态查询问题。传统的TBIR系统对于语言能力强的用户来说直观易用,但对于非母语者或对特定对象不熟悉的用户来说,他们难以找到“难以命名”的对象。SBIR系统虽然允许用户通过草图来指定对象的定性特征,但用户可能没有足够的时间、技能或工具来绘制所有细节,导致草图模糊不清。CSTBIR通过结合草图和文本描述,为用户提供了一种更灵活、自然的搜索接口,帮助他们轻松地绘制草图,并通过文本描述来定义对象的布局、颜色、姿态等特征,以及与其他对象在场景中的复杂交互。
衍生相关工作
CSTBIR数据集的提出引发了相关研究的热潮,衍生了许多经典工作。例如,STNET(Sketch+Text Network)是一种基于预训练的多模态Transformer的基线模型,它使用手绘草图来定位自然场景图像中的相关对象,并编码文本和图像以进行图像检索。此外,还有许多研究尝试解决CSTBIR问题的简化版本,例如,目标图像集合是聚焦对象而不是复杂的自然场景,草图是场景级别的而不是对象级别的,或者文本描述是全面的而不是部分的。这些研究工作为CSTBIR领域的发展提供了重要的理论和实践基础。
以上内容由遇见数据集搜集并总结生成


