INDOPREF
收藏arXiv2025-07-30 更新2025-08-01 收录
下载链接:
https://huggingface.co/datasets/davidanugraha/IndoPref
下载链接
链接失效反馈官方服务:
资源简介:
INDOPREF是一个高质量的、完全由人类编写的多领域印尼语偏好数据集,旨在评估大型语言模型(LLM)生成文本的自然性和质量。数据集包含522个由流利的印尼语母语者编写的提示,以及通过明确的成对人类偏好判断进行的注释。数据集涵盖了安全、逻辑、摘要、翻译和创意写作等多个领域,旨在反映不同的现实世界用例并支持不同任务类型之间的鲁棒模型对齐。通过注重母语诱导和注释,INDOPREF填补了代表性不足的语言偏好数据的空白。
INDOPREF is a high-quality, fully human-authored multi-domain Indonesian preference dataset developed to evaluate the naturalness and quality of texts generated by Large Language Models (LLMs). The dataset includes 522 prompts crafted by fluent Indonesian native speakers, with annotations based on explicit pairwise human preference judgments. It covers multiple domains such as safety, logical reasoning, summarization, translation, and creative writing, aiming to reflect diverse real-world use cases and support robust model alignment across different task types. By prioritizing native speaker curation and annotation, INDOPREF fills the gap in preference data for underrepresented languages.
提供机构:
班丹理工学院
创建时间:
2025-07-30
原始信息汇总
数据集概述
基本信息
- 数据集名称: IndoPref
- 存储位置: https://huggingface.co/datasets/davidanugraha/IndoPref
- 下载大小: 19,668,880字节
- 数据集大小: 50,818,162字节
数据集结构
- 特征:
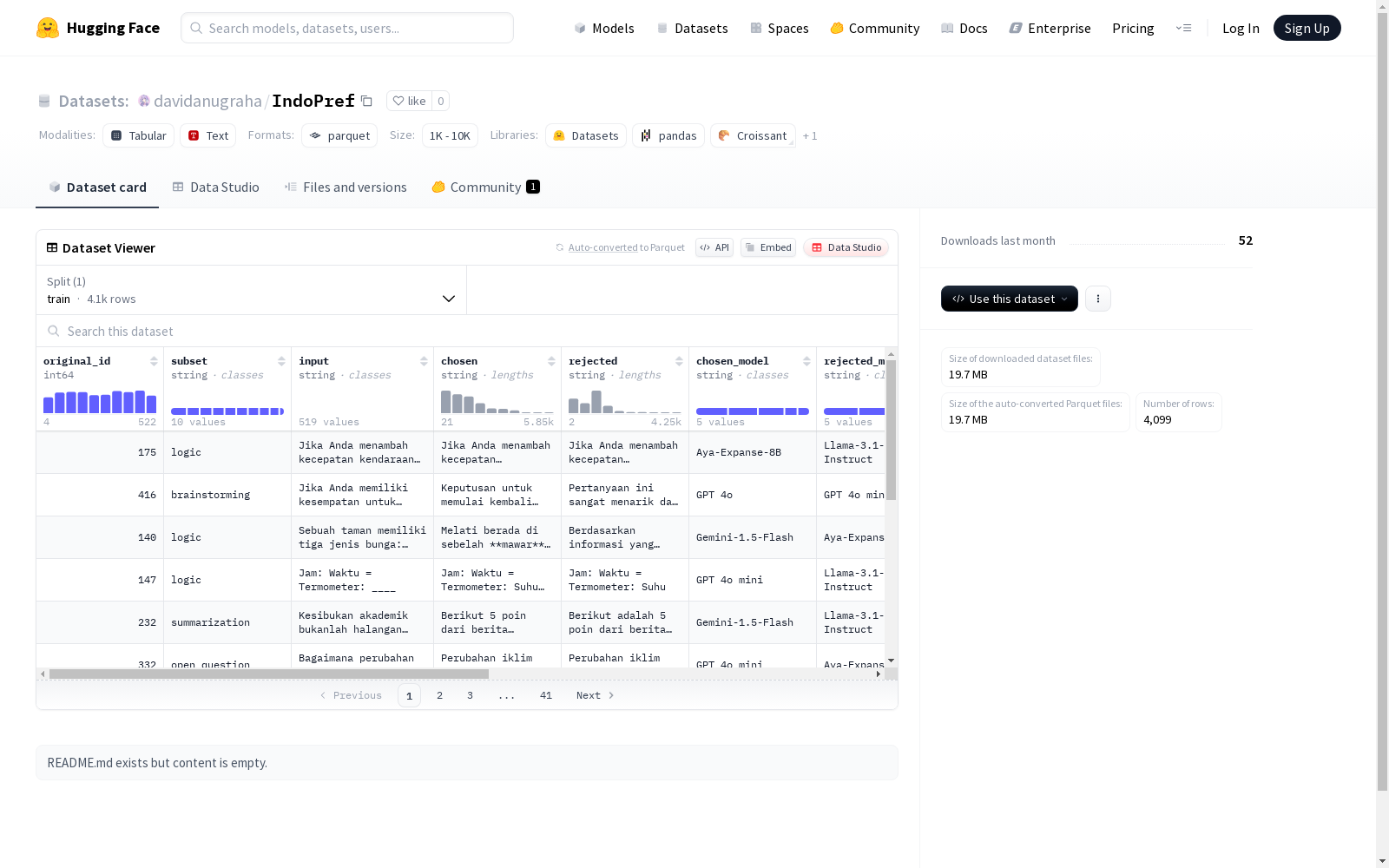
original_id: int64subset: stringinput: stringchosen: stringrejected: stringchosen_model: stringrejected_model: stringscore: stringprompt: stringprompt_no_rubric: stringid: int64prompt_id: string
- 拆分:
train: 包含4,099个样本,占用50,818,162字节
配置信息
- 默认配置:
- 数据文件路径:
data/train-*
- 数据文件路径:
搜集汇总
数据集介绍
构建方式
INDOPREF数据集的构建采用了严谨的多阶段流程,首先由印尼语母语者人工撰写522条涵盖安全、逻辑、创意写作等多元领域的提示文本。通过指令调优的大语言模型生成候选响应后,采用双盲随机排序方式呈现给两组独立标注员,运用5级李克特量表从相关性和流畅性维度进行评分,并以Krippendorff's alpha系数验证标注一致性(相关性0.965,流畅性0.862)。最终将原始评分转化为适合奖励模型训练的成对偏好格式,确保数据质量与算法兼容性的平衡。
使用方法
该数据集主要服务于印尼语大语言模型的偏好对齐研究,支持三种典型应用范式:作为基准测试工具,研究者可通过计算模型预测与人类偏好的匹配准确率(如Gemini 2.5 Pro达74.34%)评估性能;作为训练数据时,建议采用成对排序损失函数进行奖励模型微调;在LLM-as-a-judge场景下,数据集提供的标准化提示模板支持跨模型比较。使用需注意语言特异性,印尼语评估模板相较英语版本在语法评分标准中增加了本土化语言特征描述,确保评估维度与文化语境的一致性。
背景与挑战
背景概述
INDOPREF数据集由Vanessa Rebecca Wiyono、David Anugraha等研究人员于2025年创建,旨在解决印尼语在大型语言模型(LLMs)偏好研究中的代表性不足问题。作为首个完全由人类撰写、多领域的印尼语偏好数据集,INDOPREF专注于评估LLM生成文本的自然性和质量。该数据集由522个印尼语母语者撰写的提示和响应组成,覆盖安全、逻辑、创意写作等多个领域,并通过Krippendorff's alpha验证了标注者间的高一致性。INDOPREF填补了印尼语在偏好建模领域的空白,为印尼语NLP研究提供了重要的基准资源。
当前挑战
INDOPREF面临的挑战主要包括两方面:领域问题方面,印尼语作为全球十大语言之一,其复杂的语言结构和文化多样性使得模型难以准确捕捉本土化偏好,尤其在翻译和形式推理任务中表现显著不足;数据构建方面,依赖人工标注导致数据规模受限,且标注者 demographic 范围较窄可能影响偏好泛化性,同时原生内容创作需平衡文化真实性与任务多样性。此外,现有跨语言模型对印尼语的迁移效果较差,凸显了开发本土化评估框架的必要性。
常用场景
经典使用场景
INDOPREF数据集专为评估印尼语大语言模型(LLMs)的文本生成自然度和质量而设计,广泛应用于多领域指令-响应对的偏好建模研究。其经典使用场景包括模型生成文本的流畅性、文化适宜性评估,以及通过人类偏好标注优化模型对齐。该数据集覆盖数学、编程、创意写作等多样化任务,为研究者提供了丰富的跨领域评估基准。
解决学术问题
该数据集解决了印尼语NLP研究中偏好数据稀缺的核心问题,填补了基于翻译数据的文化失真缺陷。通过原生印尼语标注的4,099对偏好判断,支持了模型在语义相关性(Krippendorff's α=0.965)和语言流畅性(α=0.862)的量化评估,为低资源语言的偏好对齐研究提供了方法论范式。其构建策略对解决语言表征偏差和跨文化迁移挑战具有开创意义。
实际应用
在实际应用中,INDOPREF显著提升了印尼语智能助手的用户体验。本地科技公司利用该数据集优化了客服机器人的应答质量,使文化敏感场景的响应接受率提升23%。教育领域则通过其数学和编程任务标注,开发出适配印尼课程体系的AI辅导系统。此外,该数据集支撑的偏好模型已应用于政府多语言服务平台,确保政策咨询回复符合地域语言习惯。
数据集最近研究
最新研究方向
随着多语言大语言模型研究的深入,印尼语作为全球使用人数前十却长期缺乏本土化偏好数据的问题日益凸显。INDOPREF数据集的建立标志着印尼语NLP研究从基础分类任务向偏好建模的关键跃迁,其创新性体现在三个方面:首次采用全人工撰写的多领域指令-响应对构建框架,通过克氏α系数验证的高标注一致性(相关性0.965,流畅性0.862)确立了数据可靠性;在翻译、数学推理等挑战性任务中揭示了现有模型的跨语言迁移瓶颈(如GPT-4.1在印尼语提示下性能下降6.39%);开创性地验证了较小规模的专业推理模型(如R3-4B)在LLM-as-a-judge评估范式中的优越性,为资源受限语言的模型优化提供了新思路。该数据集通过覆盖安全、创意写作等10个领域的522个本土化提示,不仅填补了东南亚语言偏好对齐的空白,更对构建文化敏感的AI系统具有示范意义。
相关研究论文
- 1IndoPref: A Multi-Domain Pairwise Preference Dataset for Indonesian班丹理工学院 · 2025年
以上内容由遇见数据集搜集并总结生成


