alphamed_sft_alpaca
收藏Hugging Face2025-09-08 更新2025-09-09 收录
下载链接:
https://huggingface.co/datasets/pittawat/alphamed_sft_alpaca
下载链接
链接失效反馈官方服务:
资源简介:
这是一个包含指令、输出和输入文本的医学相关数据集,适用于文本生成任务。数据集分为训练集,包括mcq(多项选择题)、qa(问答)和list(列表)三种类型的数据。总数据量超过265MB,共有大约3万个示例。数据集遵循Apache-2.0许可协议。
This is a medical-related dataset containing instruction, output and input texts, designed for text generation tasks. The dataset comprises a training set with three data types: MCQ (Multiple Choice Question), QA (Question Answering) and List. The total size of the dataset exceeds 265 MB, containing approximately 30,000 instances in total. This dataset is licensed under the Apache-2.0 license.
创建时间:
2025-08-27
原始信息汇总
AlphaMed SFT Alpaca 数据集概述
数据集基本信息
- 许可证: Apache-2.0
- 语言: 英语
- 任务类别: 文本生成
- 标签: 医疗
- 规模类别: 10K<n<100K
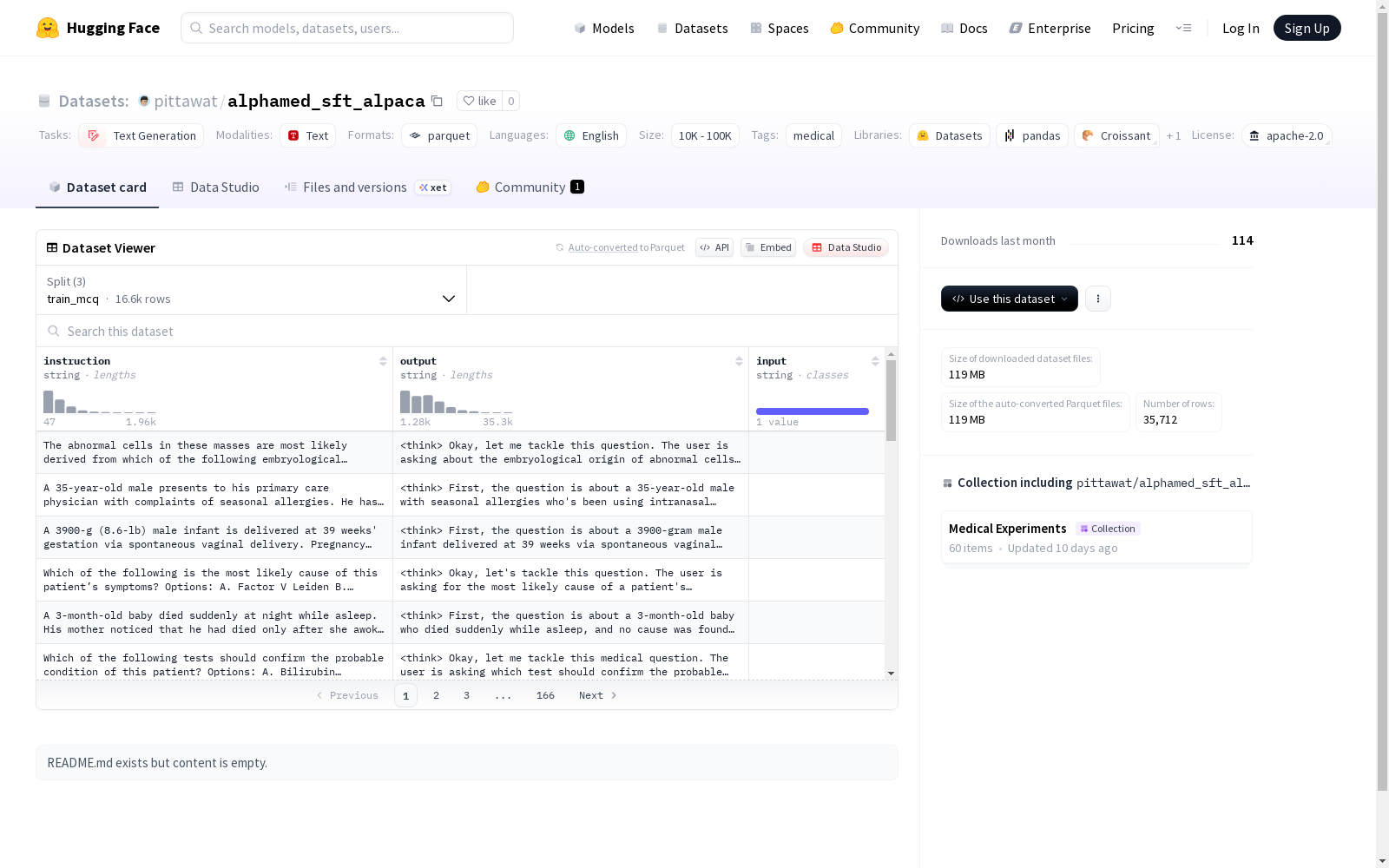
数据集结构
特征
- instruction: 字符串类型
- output: 字符串类型
- input: 字符串类型
数据拆分
- train_mcq
- 样本数量: 16,591
- 数据大小: 159,268,655 字节
- train_qa
- 样本数量: 9,416
- 数据大小: 51,955,188 字节
- train_list
- 样本数量: 9,705
- 数据大小: 54,636,301 字节
存储信息
- 下载大小: 118,508,376 字节
- 数据集总大小: 265,860,144 字节
搜集汇总
数据集介绍
构建方式
在医学知识处理领域,alphamed_sft_alpaca数据集通过精心设计的多源数据整合策略构建而成。该数据集从专业医学文献和临床问答资源中提取高质量内容,涵盖选择题、问答及列表类结构化数据,并经过严格的去重与标准化处理,确保信息的准确性和一致性。
特点
该数据集突出表现为多模态医学知识覆盖,包含16,591道选择题、9,416组问答对及9,705条结构化列表数据。其特色在于指令-输出配对格式,支持医学推理、诊断辅助和知识检索等任务,所有文本均采用英语呈现,为跨语言医学自然语言处理研究提供标准化语料。
使用方法
研究者可分别加载train_mcq、train_qa和train_list三个子集开展特定任务训练。该数据集适用于指令微调医疗大语言模型,通过解析instruction-input-output三元组结构,可构建医学对话系统、临床决策支持工具或自动化医学文本生成模型,需遵循Apache-2.0许可协议规范使用。
背景与挑战
背景概述
alphamed_sft_alpaca数据集诞生于2023年,由医疗人工智能研究团队构建,专注于医疗领域的指令微调任务。该数据集通过整合多项选择题、问答对和列表类数据,旨在增强大型语言模型在医疗咨询、诊断支持和医学知识推理方面的专业能力。其构建推动了医疗自然语言处理技术的发展,为临床决策支持系统提供了高质量的训练资源,显著提升了模型在医疗文本生成任务中的准确性和可靠性。
当前挑战
该数据集核心挑战在于解决医疗领域文本生成的高精度要求,包括医学术语的一致性、临床指南的合规性以及诊断推理的逻辑严谨性。构建过程中面临多源医疗数据的标准化整合、医学知识验证的复杂性,以及患者隐私保护的技术难题,需通过专业医学知识标注和严格的数据脱敏流程来保障数据质量与合规性。
常用场景
经典使用场景
在医疗人工智能领域,alphamed_sft_alpaca数据集被广泛用于训练医疗对话生成模型。该数据集通过指令微调格式,将医学知识转化为结构化对话数据,支持模型学习医学问答、诊断推理和医疗建议生成等核心任务。其多模态分割设计允许研究者针对选择题、问答对和列表类医疗问题分别进行专项训练,显著提升了医疗对话系统的专业性和准确性。
衍生相关工作
该数据集衍生出多项医疗AI经典研究,包括基于指令微调的医疗对话系统MedAlpaca、结合检索增强生成的临床决策模型,以及多模态医疗问答框架。这些工作显著推进了医疗自然语言处理技术的发展,为后续研究提供了重要的技术基础和评估标准,促进了整个领域的标准化进程。
数据集最近研究
最新研究方向
在医疗人工智能领域,alphamed_sft_alpaca数据集凭借其专业医学指令微调结构,正推动临床语言模型向精准化与实用化发展。当前研究聚焦于跨模态医学知识推理、多轮对话诊疗辅助系统构建,以及药物相互作用与治疗方案生成等关键方向。该数据集与近期医疗大模型伦理审查、FDA数字医疗设备认证等热点事件形成深度联动,为构建可信赖的医疗决策支持系统提供了核心训练基础,显著提升了模型在真实医疗场景中的泛化能力与安全性评估水平。
以上内容由遇见数据集搜集并总结生成


