AQMAR-NER-Collapsed-Labels
收藏Hugging Face2026-01-15 更新2026-01-16 收录
下载链接:
https://huggingface.co/datasets/muhdragab/AQMAR-NER-Collapsed-Labels
下载链接
链接失效反馈官方服务:
资源简介:
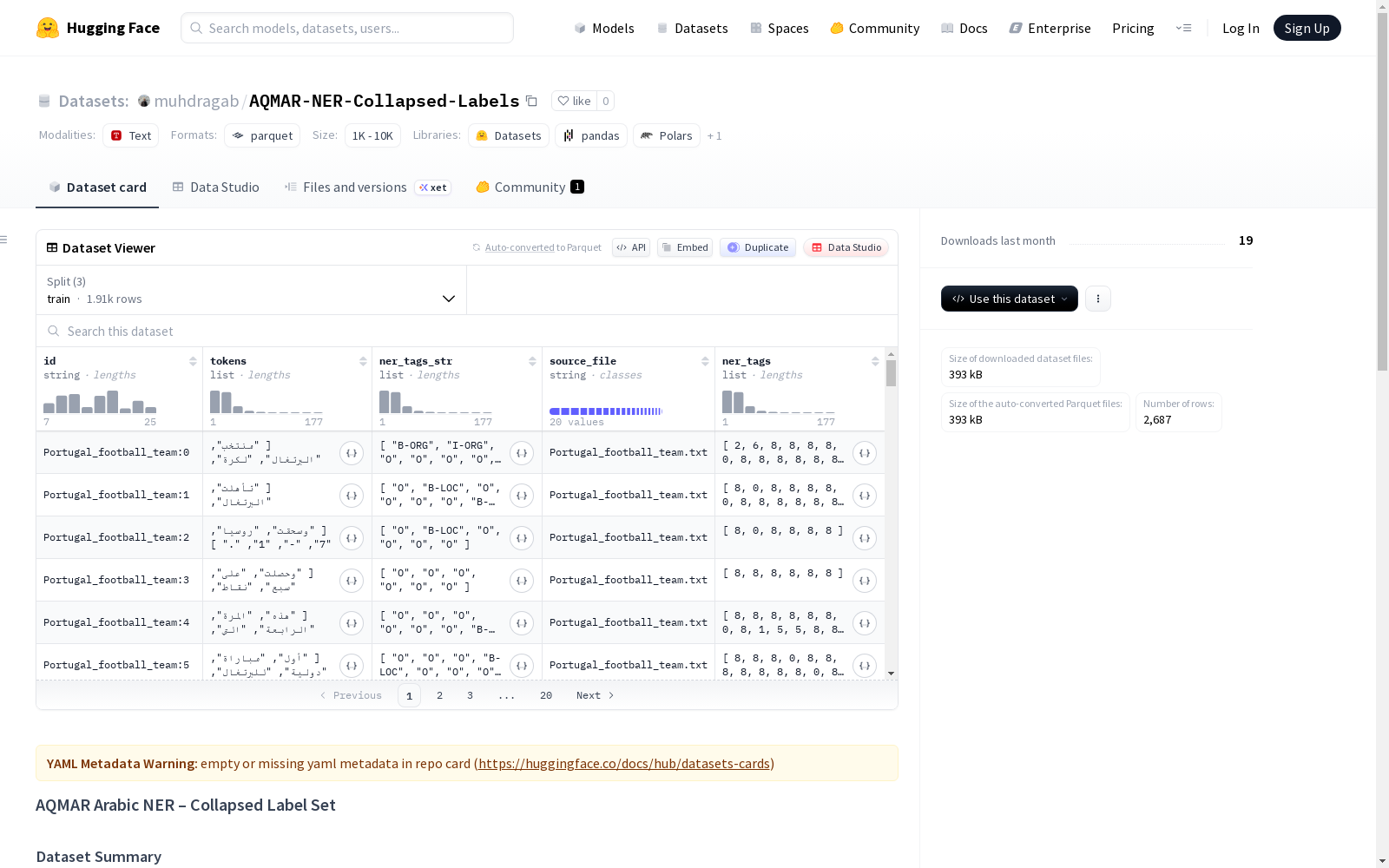
该数据集是一个**基准就绪**版本的AQMAR阿拉伯语命名实体识别(NER)语料库,其中细粒度的杂项标签被合并为单一的`MISC`类别。它源自卡内基梅隆大学(CMU)阿拉伯NLP小组发布的原始AQMAR语料库。数据集保留了原始句子边界和文件级别的训练/开发/测试分割(20/4/4文件),分割方式与完整版本相同。标签集包括PER(人名)、LOC(地点)、ORG(组织)、MISC(杂项)和O(其他,使用BIO编码:B-*、I-*标签)。数据集适合用于微F1、宏F1(不包括O)和跨度级别评估,推荐用于训练和评估阿拉伯语NER模型、基准比较和可重复实验。
创建时间:
2026-01-12
原始信息汇总
AQMAR Arabic NER – Collapsed Label Set 数据集概述
数据集摘要
本数据集是AQMAR阿拉伯语命名实体识别(NER)语料库的一个基准就绪版本,其中将细粒度的杂项标签合并为单一的MISC类别。它源自卡内基梅隆大学阿拉伯语NLP小组发布的原始AQMAR语料库。
数据来源
原始数据获取自:https://www.cs.cmu.edu/~ark/ArabicNER/
数据处理
- 保留了原始的句子边界。
- 采用文件级别的训练集/开发集/测试集划分(20/4/4个文件)。
- 划分方式与完整版本相同。
标签集
- PER(人名)
- LOC(地名)
- ORG(组织机构名)
- MISC(杂项)
- O(非实体)
(采用BIO编码:B-, I- 标签)
基准测试适用性
- 各数据划分中标签覆盖均衡。
- 开发集和测试集中没有罕见标签稀疏问题。
- 适用于微平均F1值、宏平均F1值(排除O标签)以及跨度级别评估。
预期用途
推荐用于:
- 训练和评估阿拉伯语NER模型。
- 基准比较。
- 可复现的实验。
搜集汇总
数据集介绍
构建方式
在阿拉伯语命名实体识别研究领域,AQMAR-NER-Collapsed-Labels数据集通过系统化重构原始AQMAR语料库而形成。该数据集保留了原始句子的边界结构,并采用文件级别的划分策略,将语料划分为20个训练文件、4个开发文件和4个测试文件,确保了数据分割的一致性。核心处理步骤在于将细粒度的杂项实体标签统一归并为单一的MISC类别,从而构建出一个适用于标准评测的简化标签体系,涵盖了PER、LOC、ORG、MISC及O五类实体,并采用BIO编码格式进行标注。
特点
该数据集的一个显著特点是其标签集的精心简化与平衡设计。通过将多种细粒度的杂项实体合并为统一的MISC类别,有效缓解了原始数据中可能存在的标签稀疏性问题,使得开发集和测试集中的实体类别分布更为均衡。这种设计不仅提升了数据集作为基准评测工具的适用性,支持基于微平均F1、宏平均F1(排除O标签)以及跨度级别等多种评估指标,也为模型在不同实体类型上的性能提供了稳定、可靠的对比平台。
使用方法
对于研究者而言,该数据集主要用于训练与评估阿拉伯语命名实体识别模型。在实际应用中,用户可直接加载其预设的训练、开发和测试分割,进行模型训练与超参数调优。由于其标签集简洁且评测友好,该数据集特别适合于跨模型或跨方法的基准对比研究,以及旨在实现可复现性的科学实验,为阿拉伯语信息抽取领域的进展提供了标准化的评估基础。
背景与挑战
背景概述
阿拉伯语命名实体识别作为自然语言处理领域的关键任务,长期面临资源稀缺的挑战。AQMAR-NER-Collapsed-Labels数据集由卡内基梅隆大学阿拉伯语自然语言处理团队于早期构建,其核心目标在于为阿拉伯语NER研究提供标准化基准。该数据集通过将细粒度杂项标签统一归并为MISC类别,有效简化了标注体系,从而聚焦于人物、地点、组织等核心实体类型的识别。这一举措显著提升了数据集的实用性与可比性,为后续阿拉伯语信息抽取、机器翻译等应用奠定了坚实基础。
当前挑战
在阿拉伯语命名实体识别领域,模型需应对语言形态复杂、字符编码多样及方言变体丰富等固有难题。AQMAR-NER-Collapsed-Labels数据集构建过程中,研究人员面临原始标注粒度不一致、实体边界模糊等数据处理挑战。通过压缩细粒度标签,虽增强了基准适用性,却可能损失部分语义信息,对模型深度理解构成潜在限制。此外,数据集规模相对有限,在覆盖新兴实体类型及跨领域泛化能力方面仍需进一步拓展。
常用场景
经典使用场景
在阿拉伯语自然语言处理领域,命名实体识别是基础且关键的任务之一。AQMAR-NER-Collapsed-Labels数据集作为标准化的基准资源,主要用于训练和评估阿拉伯语命名实体识别模型。研究者利用其规范的训练集、开发集和测试集划分,能够系统性地比较不同模型在PER、LOC、ORG和MISC四类实体上的识别性能,从而推动阿拉伯语信息提取技术的进步。
衍生相关工作
围绕AQMAR-NER-Collapsed-Labels数据集,学术界衍生了一系列经典研究工作。许多研究以此为基础,探索了基于循环神经网络、Transformer架构的序列标注模型在阿拉伯语上的适应性。同时,它常被用作评估跨语言迁移学习、少样本学习新方法的基准测试集。这些工作不仅提升了阿拉伯语NER的技术水平,也丰富了多语言NLP的研究范式,形成了持续的技术演进脉络。
数据集最近研究
最新研究方向
在阿拉伯语自然语言处理领域,命名实体识别作为信息抽取的核心任务,一直面临细粒度标签稀疏和标注不一致的挑战。AQMAR-NER-Collapsed-Labels数据集通过将杂项实体统一归并为MISC类别,为模型训练提供了更稳定的基准环境,有效缓解了数据不平衡问题。当前研究聚焦于利用跨语言预训练技术,如基于mBERT或XLM-R的迁移学习,以提升低资源语言下的实体识别性能;同时,结合对抗训练和领域自适应方法,增强模型对阿拉伯语方言变体的泛化能力。该数据集的标准化处理推动了阿拉伯语NER在新闻、社交媒体等实际场景中的应用,为中东地区的多语言人工智能发展提供了关键支撑。
以上内容由遇见数据集搜集并总结生成


