girlsfrontline_voices_jp
收藏Hugging Face2024-08-28 更新2024-12-12 收录
下载链接:
https://huggingface.co/datasets/deepghs/girlsfrontline_voices_jp
下载链接
链接失效反馈官方服务:
资源简介:
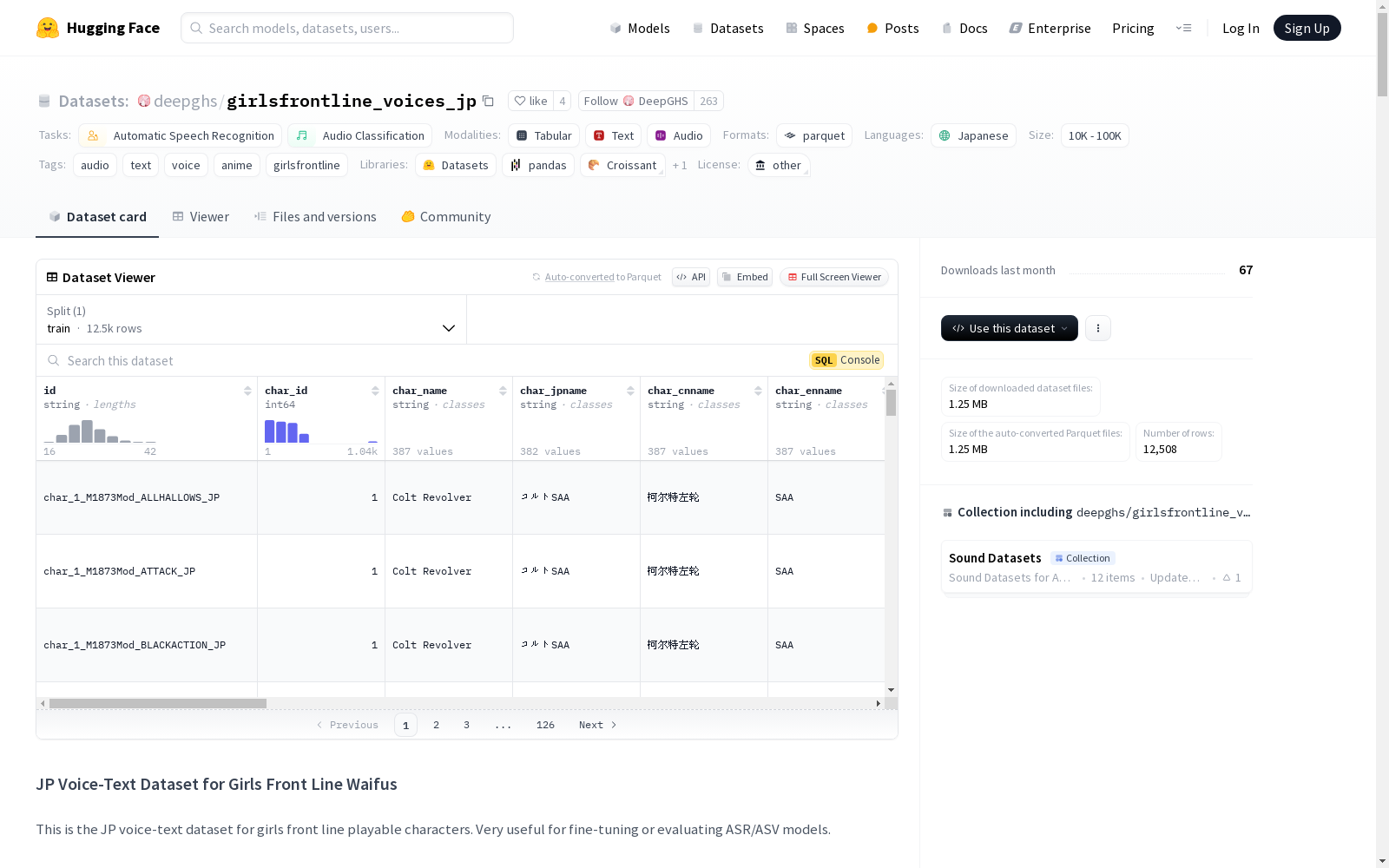
该数据集是一个日语语音-文本数据集,专门为游戏《少女前线》中的可玩角色设计。数据集包含12508条记录,总时长为20.9小时,平均每条记录时长约为6.01秒。数据集的目的是用于微调或评估自动语音识别(ASR)和自动说话人验证(ASV)模型。数据集中的语音由单一配音演员录制,以减少数据集的噪声。
创建时间:
2024-08-28
原始信息汇总
日本语音-文本数据集:少女前线角色语音
概述
该数据集包含《少女前线》游戏中可玩角色的日语语音和对应文本,适用于自动语音识别(ASR)和音频分类任务的微调或评估。数据集中的语音均由单一配音演员录制,以减少数据集的噪声。
数据集统计
- 记录数量:12508条
- 总时长:20.9小时
- 平均时长:约6.01秒
数据格式
数据集中的每条记录包含以下字段:
- id:记录唯一标识符
- char_id:角色ID
- voice_actor_name:配音演员名称
- voice_title:语音标题
- voice_text:语音对应的文本
- time:语音时长
- sample_rate:采样率
- file_size:文件大小
- filename:文件名
- mimetype:文件MIME类型
- file_url:文件URL
示例记录
| id | char_id | voice_actor_name | voice_title | voice_text | time | sample_rate | file_size | filename | mimetype | file_url |
|---|---|---|---|---|---|---|---|---|---|---|
| char_1_M1873Mod_ALLHALLOWS_JP | 1 | Tanaka Aimi | Halloween | お化けとか怖くないからね!... | 10.983 | 44100 | 301302 | char_1_M1873Mod_ALLHALLOWS_JP.ogg | audio/ogg | https://iopwiki.com/images/c/c9/M1873Mod_ALLHALLOWS_JP.ogg |
标签
- 语言:日语(ja)
- 任务类别:自动语音识别、音频分类
- 标签:音频、文本、语音、动漫、少女前线
- 大小类别:10K<n<100K
许可
该数据集的许可类型为“other”。
搜集汇总
数据集介绍
构建方式
该数据集专注于《少女前线》游戏中可玩角色的日语语音与文本对应关系,旨在为自动语音识别(ASR)和语音分类(ASV)模型的微调与评估提供支持。数据集的构建过程中,严格筛选了仅由单一配音演员录制的语音,以确保数据的纯净性。最终收录了12508条语音记录,总时长约20.9小时,平均每条语音时长约为6.01秒。每条记录均包含角色ID、配音演员姓名、语音标题、语音文本、时长、采样率、文件大小、文件名及文件链接等详细信息。
特点
该数据集的特点在于其高度结构化的语音-文本对应关系,每条语音均标注了详细的元数据,包括角色ID、配音演员信息及语音内容。数据集涵盖了多种游戏场景下的语音,如攻击、防御、节日问候等,具有丰富的语境多样性。此外,语音文件以OGG格式存储,采样率为44100Hz,确保了高质量的音频数据。数据集的规模适中,适合用于深度学习模型的训练与验证。
使用方法
该数据集可用于自动语音识别(ASR)和语音分类(ASV)任务的研究与开发。用户可通过下载语音文件及其对应的文本数据,构建语音-文本对齐的训练集或测试集。此外,数据集还可用于语音合成(TTS)模型的训练,以生成特定角色的语音。使用过程中,建议结合深度学习框架(如PyTorch或TensorFlow)进行模型训练,并通过数据增强技术进一步提升模型的泛化能力。
背景与挑战
背景概述
《girlsfrontline_voices_jp》数据集是一个专注于日语语音与文本对齐的数据集,主要应用于自动语音识别(ASR)和语音分类任务。该数据集基于《少女前线》(Girls Frontline)游戏中的角色语音,收录了12508条语音记录,总时长约20.9小时,平均每条语音时长为6.01秒。数据集由游戏中的角色语音及其对应的文本组成,且每条语音均由单一配音演员录制,以确保数据的一致性和质量。该数据集的创建旨在为ASR模型的微调和评估提供高质量的语音-文本对,尤其是在动漫和游戏领域的语音识别研究中具有重要价值。
当前挑战
该数据集面临的挑战主要体现在两个方面。首先,尽管数据集通过限制单一配音演员来减少噪声,但语音内容的多样性和复杂性仍然对ASR模型的泛化能力提出了较高要求。例如,语音中包含大量游戏术语、情感表达和特定场景下的对话,这对模型的上下文理解和语义捕捉能力构成了挑战。其次,数据集的构建过程中,语音与文本的对齐工作需高度精确,尤其是在处理较长的语音片段时,确保文本与语音的时间戳匹配是一项技术难题。此外,数据集的规模虽然适中,但在实际应用中,仍需进一步扩展以覆盖更多场景和语音风格,从而提升模型的鲁棒性和适应性。
常用场景
经典使用场景
在语音识别和音频分类领域,girlsfrontline_voices_jp数据集为研究人员提供了一个独特的资源,专门用于训练和评估自动语音识别(ASR)和自动说话人验证(ASV)模型。该数据集包含了《少女前线》游戏中角色的大量日语语音片段,每个片段都配有相应的文本标注,确保了数据的高质量和一致性。
实际应用
在实际应用中,girlsfrontline_voices_jp数据集可以用于开发游戏内的语音交互系统,提升玩家的沉浸式体验。此外,该数据集还可用于语音助手的训练,特别是在日语环境下,能够提高语音助手的识别准确率和响应速度。同时,该数据集也为动漫和游戏配音行业提供了高质量的语音样本,助力配音演员的培训和语音合成技术的改进。
衍生相关工作
基于girlsfrontline_voices_jp数据集,许多经典的研究工作得以展开。例如,研究人员利用该数据集开发了针对日语语音的端到端语音识别模型,显著提升了日语语音识别的准确率。此外,该数据集还被用于多模态学习的研究,结合文本和语音数据,开发了能够同时处理语音和文本信息的深度学习模型,进一步推动了语音识别和自然语言处理的融合。
以上内容由遇见数据集搜集并总结生成


