ghomasHudson/muld
收藏Hugging Face2022-11-02 更新2024-03-04 收录
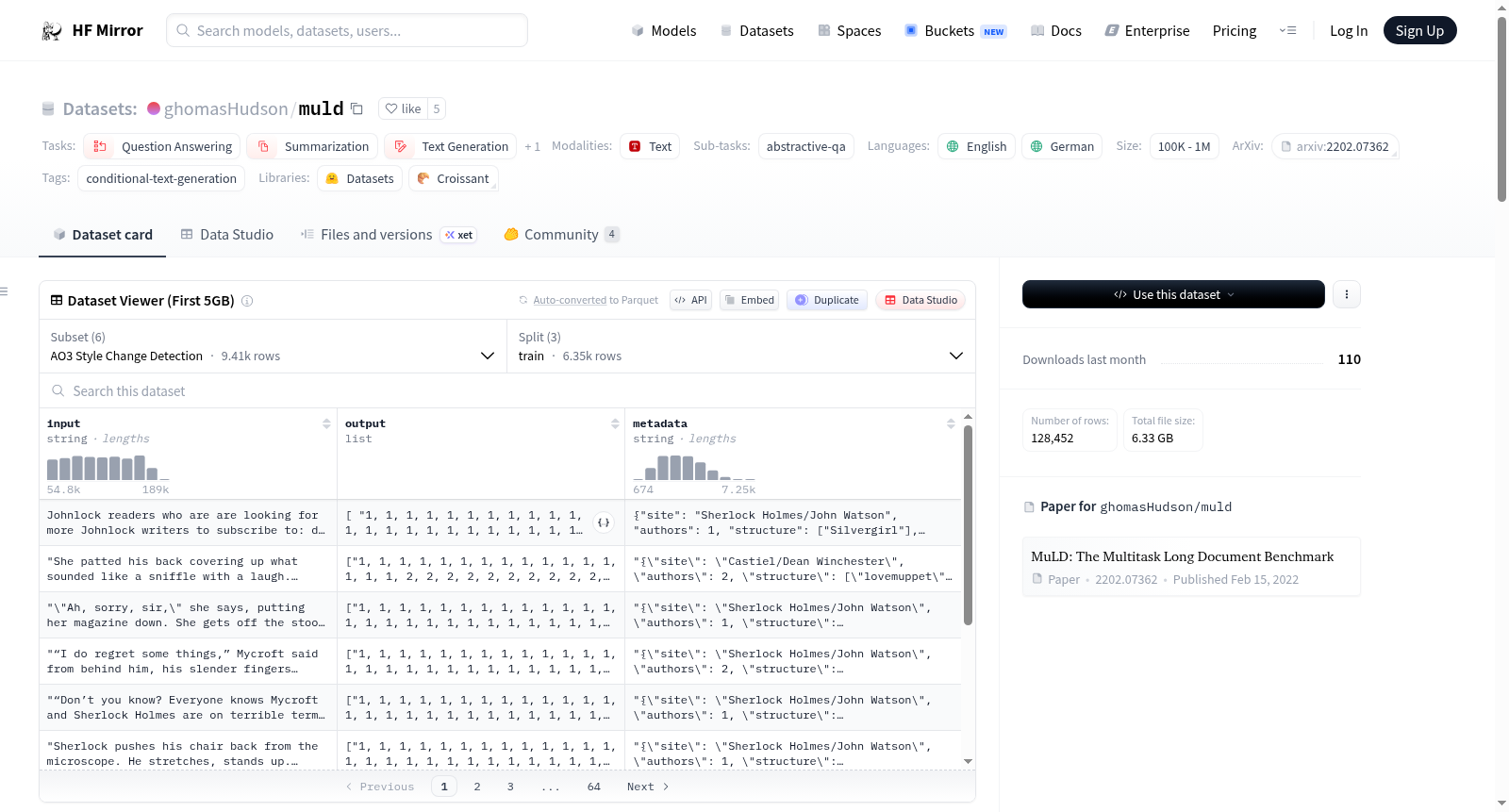
下载链接:
https://hf-mirror.com/datasets/ghomasHudson/muld
下载链接
链接失效反馈官方服务:
资源简介:
MuLD(多任务长文档基准)是一个包含至少10,000字的长文档数据集,涵盖翻译、摘要、问答和分类等多种NLP任务。该数据集支持英语和德语,具有多种任务类型和输出长度,每个实例包含输入字符串、输出字符串和可选的元数据。
MuLD(多任务长文档基准)是一个包含至少10,000字的长文档数据集,涵盖翻译、摘要、问答和分类等多种NLP任务。该数据集支持英语和德语,具有多种任务类型和输出长度,每个实例包含输入字符串、输出字符串和可选的元数据。
提供机构:
ghomasHudson
原始信息汇总
MuLD 数据集概述
基本信息
- 名称: The Multitask Long Document Benchmark (MuLD)
- 语言: 英语 (en), 德语 (de)
- 多语言性: 翻译, 单语
- 数据来源: 原始数据, 扩展自 HotpotQA 和 OpenSubtitles
- 任务类型: 问答, 摘要, 文本生成, 翻译
- 任务ID: 抽象问答 (abstractive-qa)
- 标签: 条件文本生成
数据集结构
- 数据字段:
input: 输入字符串,结构因任务而异,但格式统一。output: 输出字符串列表,每个字符串为可能的答案。多数实例只有一个答案,但如 NarrativeQA 和 VLSP 可能包含多个答案。metadata: 附加元数据,可能有助于评估。目前仅 OpenSubtitles 任务包含元数据。
任务详情
- 任务列表:
- NarrativeQA: 理解书籍和电影情节的问答数据集。
- HotpotQA: 扩展自 HotpotQA,要求在多个维基百科页面间进行多跳推理。
- OpenSubtitles: 基于 OpenSubtitles 2018 数据集的翻译数据集,提供每部电视剧的完整字幕,英德双语。
- VLSP (Very Long Scientific Papers): 科学论文摘要数据集的扩展版本,特别包含长论文。
- AO3 Style Change Detection: 从多个 Archive of Our Own 作者的作品中预测每个段落的作者。
- Movie Character Types: 根据电影剧本预测角色是否为英雄/反派。
数据分割
- 分割详情:
任务名称 训练集 验证集 测试集 NarrativeQA ✔️ ✔️ ✔️ HotpotQA ✔️ ✔️ AO3 Style Change Detection ✔️ ✔️ ✔️ Movie Character Types ✔️ ✔️ ✔️ VLSP ✔️ OpenSubtitles ✔️ ✔️
引用信息
@misc{hudson2022muld, title={MuLD: The Multitask Long Document Benchmark}, author={G Thomas Hudson and Noura Al Moubayed}, year={2022}, eprint={2202.07362}, archivePrefix={arXiv}, primaryClass={cs.CL} }
搜集汇总
数据集介绍
构建方式
在自然语言处理领域,长文档理解任务日益凸显其重要性。MuLD基准的构建融合了多元数据源,包括原始数据集与扩展版本,如HotpotQA与OpenSubtitles。通过精心筛选与整合,确保每个任务输入文本均超过一万词,涵盖翻译、摘要、问答及分类等多种任务类型。数据格式统一为文本到文本的结构,每个实例包含输入字符串、输出字符串及可选的元数据,为模型评估提供了标准化框架。
特点
MuLD基准以其广泛的任务覆盖和长文档输入为显著特征。该数据集包含六个独立任务,如NarrativeQA的叙事理解、HotpotQA的多跳推理,以及OpenSubtitles的跨语言翻译,输出长度从单一标签到超越输入的文本不等。这种多样性不仅挑战模型的长上下文处理能力,还促进了多任务学习的探索。数据以统一格式呈现,便于跨任务比较与评估,为自然语言处理研究提供了丰富的实验平台。
使用方法
在应用MuLD基准时,研究者可依据任务需求选择相应数据集进行模型训练与评估。数据以文本到文本格式提供,输入为长文档字符串,输出为答案列表,支持直接用于生成或分类模型。用户可通过HuggingFace平台访问数据,利用提供的训练、验证和测试分割进行实验。此外,元数据字段为特定任务(如OpenSubtitles)提供额外信息,有助于深入分析。该基准适用于评估模型在长文档多任务场景下的综合性能。
背景与挑战
背景概述
在自然语言处理领域,长文档理解一直是研究的前沿与难点,传统数据集往往聚焦于短文本任务,难以全面评估模型处理大规模上下文的能力。MuLD(多任务长文档基准)由G Thomas Hudson与Noura Al Moubayed于2022年提出,旨在构建一个涵盖多种任务类型、输入长度超过一万词的综合性基准。该数据集整合了叙事问答、多跳推理、翻译、摘要、风格检测及角色分类等六项任务,其核心研究问题在于探索模型在长文档场景下的泛化与推理能力,为推进文档级自然语言处理技术的发展提供了关键的数据支撑,并对相关领域的模型评估与优化产生了深远影响。
当前挑战
MuLD数据集所解决的领域问题涉及长文档多任务处理,其核心挑战在于模型需同时应对不同任务类型的复杂性,如跨文档的多跳推理、长距离依赖的摘要生成以及细粒度的风格检测,这些任务要求模型具备强大的上下文理解与信息整合能力。在构建过程中,数据集面临多重挑战:一是数据来源的异构性,需从书籍、电影脚本、维基百科及学术论文等多种渠道整合并统一格式;二是长文档的标注难度高,尤其在叙事问答和摘要任务中,确保答案的准确性与一致性需要精细的众包或专家审核;三是多语言翻译任务的平衡,如OpenSubtitles中的英德双语对齐,需处理字幕时序与语义对应问题,以维持数据的质量与可用性。
常用场景
经典使用场景
在自然语言处理领域,长文档理解一直是模型能力评估的关键挑战。MuLD数据集通过整合六个任务,为研究者提供了一个统一的基准测试平台,特别适用于评估模型在超长文本输入下的性能。其经典使用场景包括训练和测试模型在叙事理解、多跳推理、跨语言翻译以及文档风格检测等方面的综合能力,这些任务均要求模型处理超过一万词的输入,从而深入检验其长距离依赖捕捉和信息整合效率。
解决学术问题
MuLD数据集针对自然语言处理中长文档建模的瓶颈问题,提供了系统性的解决方案。它有效解决了传统基准测试中文本长度受限、任务类型单一的问题,通过涵盖问答、摘要、翻译和分类等多种任务,促进了模型在复杂语境下的泛化能力研究。该数据集的意义在于推动了长文档处理技术的发展,为评估模型在真实世界长文本场景中的表现设立了新标准,对提升语言模型的实用性和鲁棒性产生了深远影响。
衍生相关工作
基于MuLD数据集,学术界已衍生出多项经典研究工作。这些工作主要集中在改进Transformer架构的长序列处理能力,例如开发更高效的位置编码和注意力机制,以应对长文档带来的计算挑战。同时,研究者利用该数据集的多任务特性,探索了跨任务知识迁移和模型压缩技术,推动了如Longformer和BigBird等高效长文本模型的演进,为后续长文档基准的构建和优化提供了理论基础和实践经验。
以上内容由遇见数据集搜集并总结生成


