SA-Text和Real-Text
收藏github2025-06-19 更新2025-06-20 收录
下载链接:
https://github.com/cvlab-kaist/TAIR
下载链接
链接失效反馈官方服务:
资源简介:
SA-Text是一个新提出的用于文本感知图像修复(TAIR)任务的数据集,它是从SA-1B数据集构建的,包含100K图像-文本实例对,带有详细的场景级注释。Real-Text是一个用于真实世界场景的评估数据集,它是从RealSR和DrealSR构建的,使用了与上述相同的流程。
SA-Text is a newly-proposed dataset for the text-aware image inpainting (TAIR) task, which is constructed from the SA-1B dataset and contains 100K image-text instance pairs with detailed scene-level annotations. Real-Text is an evaluation dataset for real-world scenarios, which is constructed from RealSR and DrealSR using the same pipeline as mentioned above.
创建时间:
2025-06-01
原始信息汇总
数据集概述
基本信息
- 数据集名称: Text-Aware Image Restoration with Diffusion Models (TAIR)
- 相关论文: arXiv:2506.09993
- 项目页面: Project Page
- 发布日期: 2025年6月19日
数据集详情
SA-Text 数据集
- 用途: 用于文本感知图像修复(Text-Aware Image Restoration, TAIR)任务
- 来源: 基于SA-1B数据集构建
- 规模: 包含100K图像-文本实例对
- 特点:
- 提供详细的场景级标注
- 每个图像与一个或多个文本实例配对,包含多边形级标注
Real-Text 数据集
- 用途: 用于真实场景下的评估
- 来源: 基于RealSR和DrealSR数据集构建
- 特点:
- 包含高质量图像(HQ)和低质量退化输入(LQ)
- 采用与SA-Text相同的构建流程
数据集下载
SA-Text
- Hugging Face: Min-Jaewon/SA-Text
- Google Drive: SA-Text
Real-Text
- Hugging Face: Min-Jaewon/Real-Text
- Google Drive: Real-Text
数据集结构
SA-Text
SA-Text/ ├── images/ # 100K高质量场景图像,包含文本实例 └── restoration_dataset.json # 标注文件
Real-Text
Real-Text/ ├── HQ/ # 高质量图像 ├── LQ/ # 低质量退化输入 └── real_benchmark_dataset.json # 标注文件
注意事项
- 数据集遵循一致的标注格式,详细说明见数据集构建流程
- 推荐使用Google Drive上的数据集进行代码测试
搜集汇总
数据集介绍
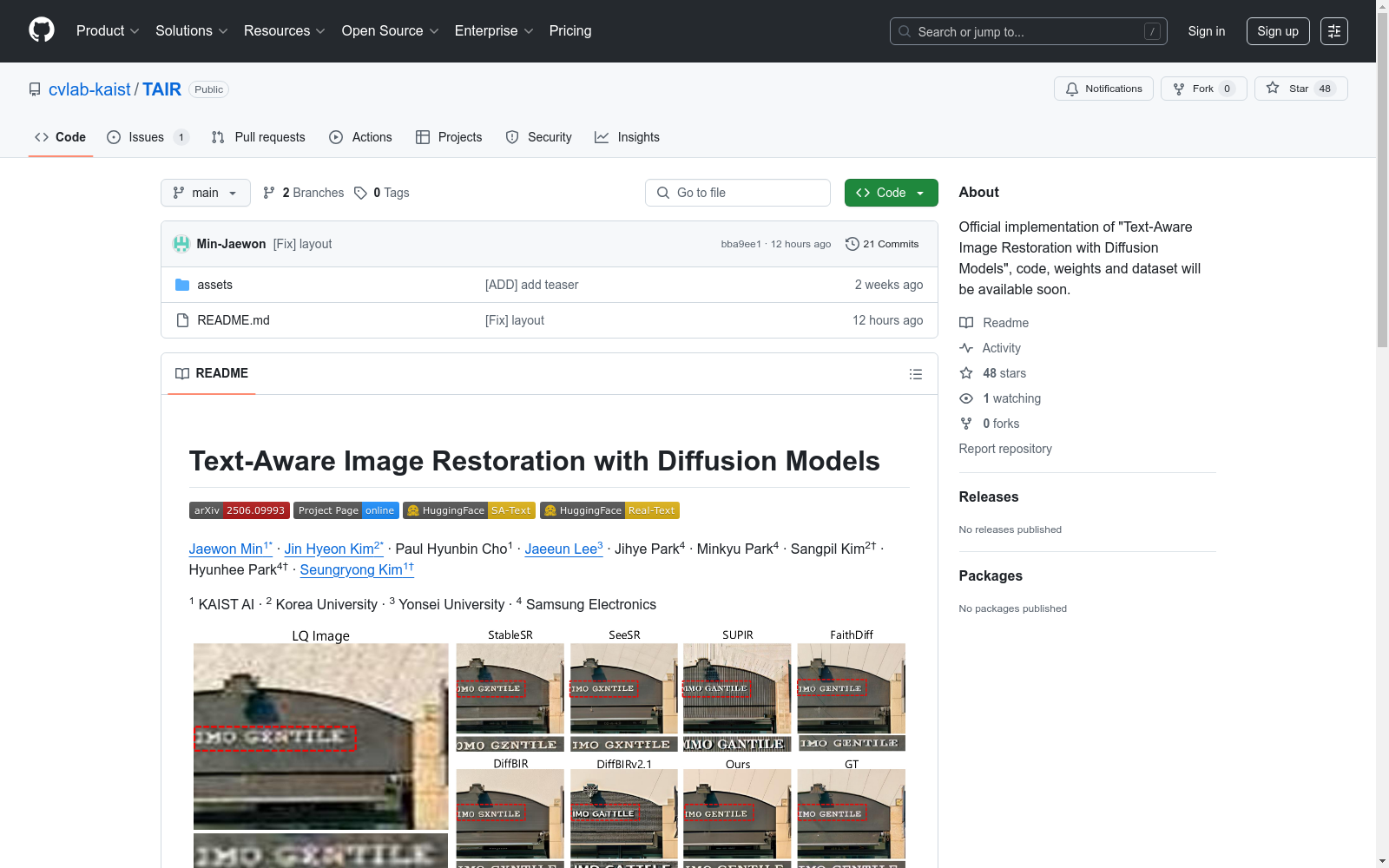
构建方式
在计算机视觉领域,文本感知图像修复任务对数据质量提出极高要求。SA-Text数据集基于SA-1B数据集构建,通过专门设计的管道处理流程,系统性地生成了10万张包含文本实例的高质量场景图像。Real-Text评估集则从RealSR和DrealSR两大真实超分数据源中提取,采用相同的标准化处理流程,确保数据构建过程的科学性与可复现性。所有图像均配备多边形级别的文本标注,形成完整的图像-文本实例对。
特点
该数据集体系最显著的特征在于其双重架构设计:SA-Text作为大规模训练集提供丰富的场景多样性,Real-Text则专注真实世界复杂退化场景的评估验证。数据样本均包含精确的几何级文本标注,支持端到端的文本区域修复研究。特别值得注意的是,数据集采用统一的JSON标注格式,既保留原始图像质量信息,又完整记录文本实例的空间分布特征,为多模态图像修复算法开发提供坚实基础。
使用方法
研究者可通过Hugging Face或Google Drive平台获取数据集资源,建议按照官方推荐使用Google Drive版本进行代码测试。数据集采用标准目录结构组织,HQ和LQ子目录分别存储高低质量图像,配套的JSON文件包含完整的文本标注信息。使用时应遵循标注文件中的数据结构规范,通过解析多边形坐标实现文本区域的精确定位。该数据集特别适合用于训练和评估结合文本语义理解的图像修复模型,在超分辨率、去模糊等任务中展现独特价值。
背景与挑战
背景概述
SA-Text和Real-Text数据集由KAIST AI、Korea University、Yonsei University及Samsung Electronics的研究团队于2025年联合发布,旨在推动文本感知图像修复(Text-Aware Image Restoration, TAIR)领域的研究。该数据集基于SA-1B数据集构建,包含10万张高质量场景图像及对应的文本实例标注,同时通过RealSR和DrealSR构建了面向真实场景的评估数据集Real-Text。其核心研究问题在于如何利用扩散模型实现文本与图像内容的协同修复,为文档分析、场景理解等应用提供了重要的基准数据。
当前挑战
在文本感知图像修复领域,SA-Text和Real-Text需解决低质量文本区域修复与上下文一致性保持的双重挑战。构建过程中,研究团队面临标注复杂度高的问题,包括文本实例的多尺度定位、多边形标注的精确性要求,以及真实场景下光照、模糊等因素导致的文本退化多样性。此外,如何平衡合成数据(SA-Text)与真实数据(Real-Text)的分布差异,确保模型泛化能力,亦是该数据集设计的核心难点。
常用场景
经典使用场景
在计算机视觉领域,文本感知图像修复(TAIR)任务对场景图像中的文本恢复具有重要意义。SA-Text和Real-Text数据集为这一任务提供了丰富的资源,其中SA-Text包含10万张高质量场景图像及文本实例标注,Real-Text则专注于真实世界场景的评估。这些数据集广泛应用于基于扩散模型的文本修复研究,为模型训练和性能评估提供了标准化平台。
衍生相关工作
该数据集已催生多项重要研究,包括基于扩散模型的端到端文本修复框架TAIR-Net,以及结合注意力机制的多尺度文本增强方法。相关成果发表在CVPR、ICCV等顶级会议,推动了文本图像处理与生成式模型的交叉创新。数据集构建流程也被扩展应用于多语言文本修复基准的创建。
数据集最近研究
最新研究方向
在计算机视觉领域,文本感知图像修复(TAIR)任务正逐渐成为研究热点。SA-Text和Real-Text数据集的推出,为这一方向提供了重要的数据支持。SA-Text基于SA-1B数据集构建,包含10万张高质量场景图像及文本实例标注,而Real-Text则从RealSR和DrealSR中提取,专注于真实场景下的评估。这些数据集的出现,推动了基于扩散模型的文本修复技术发展,尤其在场景文本恢复、图像超分辨率等应用中展现出巨大潜力。其详细的场景级标注和统一的格式,为研究者提供了可靠的基准,进一步促进了文本与图像多模态融合的前沿探索。
以上内容由遇见数据集搜集并总结生成


