Elaina_WanderingWitch_audio_JA
收藏Hugging Face2026-04-05 更新2026-04-06 收录
下载链接:
https://huggingface.co/datasets/yeeko/Elaina_WanderingWitch_audio_JA
下载链接
链接失效反馈官方服务:
资源简介:
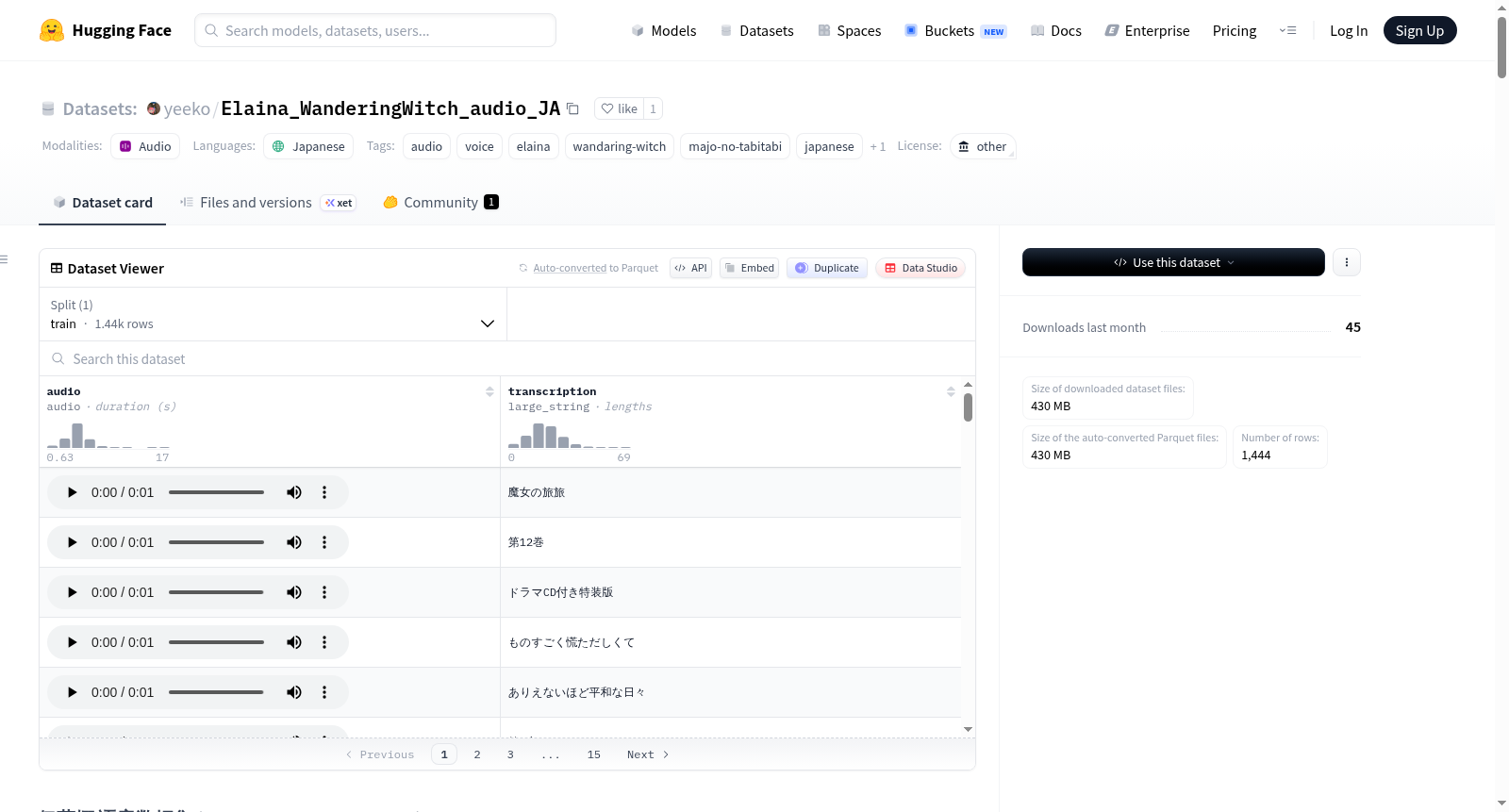
伊蕾娜语音数据集(Elaina Voice Audio Dataset)是一个收录了来自动漫《魔女之旅》主角伊蕾娜(由本渡楓配音)日语配音的音频切片及对应文本的数据集。数据集包含音频剪辑及其转录文本,音频来源为Bilibili,数据格式为Parquet和MP3/WAV。该数据集适用于语音处理、文本到语音(TTS)和语音识别等任务的研究和学习。数据集加载支持通过HuggingFace的`datasets`库或直接使用pandas读取Parquet文件。需要注意的是,Windows系统下Python 3.11/3.12存在兼容性问题,提供了两种解决方案。数据集仅供学习和研究使用,商业用途需联系版权方授权。
创建时间:
2026-04-04
原始信息汇总
伊蕾娜 语音数据集 (Elaina Voice Audio Dataset) 概述
数据集基本信息
- 数据集名称: 伊蕾娜 语音数据集 (Elaina Voice Audio Dataset)
- 托管地址: https://huggingface.co/datasets/yeeko/Elaina_WanderingWitch_audio_JA
- 许可协议: other
- 语言: 日语 (ja)
- 标签: audio, voice, elaina, wandaring-witch, majo-no-tabitabi, japanese, anime
- 标注创建者: no-annotation
- 语言创建者: found
数据集内容
- 角色: 伊蕾娜 (Elaina / イレイナ)
- 来源作品: 《魔女之旅》(Majo no Tabitabi / 魔女の旅々 / Wandering Witch: The Journey of Elaina)
- 配音演员: 本渡楓 (Kaede Hondo)
- 配音语言: 日语 (JA)
- 音频来源: B站 / Bilibili
- 数据格式: Parquet + MP3/WAV
- 数据内容: 收录了伊蕾娜日语配音的音频切片及对应文本。
数据预览
- 预览图片地址: https://huggingface.co/datasets/yeeko/Elaina_WanderingWitch_audio_JA/raw/main/images/Elaina.jpg
使用说明
加载数据集
python from datasets import load_dataset dataset = load_dataset("yeeko/Elaina_WanderingWitch_audio_JA") print(dataset["train"][0])
Windows + Python 3.11/3.12 兼容性问题及解决方案
在 Windows + Python 3.11/3.12 环境下,datasets 库可能触发 multiprocessing 的 RLock._recursion_count 错误。
解法一:绕过 load_dataset(推荐) python import pandas as pd url = "https://huggingface.co/datasets/yeeko/Elaina_WanderingWitch_audio_JA/resolve/main/train/metadata.parquet" df = pd.read_parquet(url) print(df.head())
音频 URL: https://huggingface.co/datasets/yeeko/Elaina_WanderingWitch_audio_JA/resolve/main/train/{filename}
解法二:禁用多进程 python import os os.environ["HF_DATASETS_DISABLE_MULTIPROCESSING"] = "1" from datasets import load_dataset dataset = load_dataset("yeeko/Elaina_WanderingWitch_audio_JA", num_workers=0)
注意事项
- 本数据集仅供学习与研究使用。
- 音频版权归原作者及版权方所有。
- 如需用于商业用途,请联系版权方授权。
搜集汇总
数据集介绍
构建方式
在语音合成与角色声音建模领域,高质量的角色专属语音数据集是推动技术发展的关键资源。Elaina_WanderingWitch_audio_JA数据集的构建源于对动漫角色伊蕾娜语音的系统性采集与处理。该数据集以日本动画《魔女之旅》中由声优本渡楓配音的主角伊蕾娜为对象,其原始音频素材主要来源于Bilibili平台上的相关视频内容。构建过程中,团队从这些视频中提取出伊蕾娜的语音片段,并进行了精细的切片处理,确保每个音频单元都清晰对应角色的独立话语。同时,为每个音频切片配对了准确的日语文本转录,形成了结构化的语音-文本对。数据最终以Parquet格式存储元数据,而音频文件则以MP3或WAV格式保存,便于后续的机器学习任务直接调用与分析。
特点
作为聚焦于特定动漫角色的语音资源,本数据集展现出若干鲜明特征。其核心价值在于高度的角色纯净性与一致性,所有音频均源自同一作品中的同一角色,并由同一声优演绎,这为训练具备角色辨识度的语音模型提供了理想素材。数据内容涵盖了伊蕾娜在剧中多样的情感表达与语境对话,从冷静叙述到俏皮自语,语音风格丰富,有助于模型捕捉角色声音的细微特质。数据集提供了语音与文本的精准对齐,这种配对结构是进行语音合成、语音识别或声音克隆等任务的标准化输入。此外,数据集以开放格式存储,并通过HuggingFace平台发布,确保了资源的可访问性与可复现性,为学术研究提供了便利。
使用方法
对于意图利用该数据集进行语音技术研究的开发者而言,其使用方法清晰而灵活。最直接的途径是通过HuggingFace的`datasets`库,使用`load_dataset`函数并指定数据集名称即可加载。加载后,数据集以常见的字典结构呈现,用户可以便捷地访问音频数据及其对应文本标签。值得注意的是,在特定系统环境下可能存在兼容性问题,文档中亦提供了实用的解决方案。例如,在Windows搭配高版本Python时,可采取绕过标准加载函数的方式,直接使用pandas读取Parquet格式的元数据文件,再根据文件名构造音频文件的远程访问路径。另一种方案是通过设置环境变量来禁用多进程加载模式。这些方法确保了数据集在不同技术栈下的可用性,使用者可根据自身实验环境选择最稳妥的加载策略,进而将数据应用于模型训练或分析流程中。
背景与挑战
背景概述
在语音合成与角色声音建模领域,特定角色语音数据集的构建对于推动个性化语音生成技术发展具有关键意义。Elaina_WanderingWitch_audio_JA数据集聚焦于日本动画《魔女之旅》主角伊蕾娜的日语语音,由社区贡献者基于动画原声素材整理而成。该数据集收录了由声优本渡楓演绎的角色语音切片及对应文本,旨在为角色声音克隆、情感语音合成等研究方向提供高质量、风格统一的训练资源。其出现反映了当前语音技术研究向细粒度、个性化方向深化的趋势,为动漫角色语音的数字保存与创造性应用提供了新的可能性。
当前挑战
该数据集致力于解决角色声音建模领域的核心挑战,即如何从有限的多变语境音频中,精准捕捉并复现特定角色独特的音色、语调和情感表达风格。构建过程中面临多重困难:首先,原始音频来源于流媒体平台,需进行降噪、分割和对齐等预处理以保障数据纯净度与可用性;其次,动画对话场景多样,需确保切片能覆盖角色丰富的情绪状态和说话方式,以构建具有表现力的训练集;此外,数据集的合法使用边界需明确界定,如何在尊重版权的前提下促进学术研究,亦是构建者必须审慎处理的关键问题。
常用场景
经典使用场景
在语音合成与声学建模领域,特定角色的高质量语音数据集是构建个性化语音系统的基石。Elaina_WanderingWitch_audio_JA数据集以其纯净的日语单角色语音切片,为研究者提供了理想的实验素材。该数据集常被用于训练端到端的语音合成模型,如Tacotron或FastSpeech系列,以精准复现伊蕾娜角色特有的音色、语调和情感韵律,从而在动漫衍生内容创作或虚拟角色交互中实现高度拟真的语音生成。
解决学术问题
该数据集有效应对了语音技术研究中数据稀缺与质量不均的挑战。在语音克隆、情感语音合成及少样本语音适应等前沿方向,它提供了标注清晰的单说话人语料,助力解决模型在捕捉特定音色细节和自然韵律时的泛化难题。其存在降低了研究者获取高质量、版权清晰动漫语音数据的门槛,推动了基于角色的个性化语音合成技术在学术界的深入探索与性能基准建立。
衍生相关工作
围绕此类高质量角色语音数据,已衍生出诸多经典研究工作。例如,在语音转换领域,研究常借鉴其进行说话人身份编码与音色迁移的实验;在语音合成领域,它可作为预训练或微调数据,用于改进VITS、StyleTTS等现代架构对角色声音的建模能力。此外,该数据集也常被纳入多模态学习框架,与对应角色的视觉形象结合,探索视听一致的虚拟人生成技术,推动了跨媒体内容生成技术的发展。
以上内容由遇见数据集搜集并总结生成


