ByteDance Cloud workload datasets
收藏arXiv2025-07-17 更新2025-07-19 收录
下载链接:
https://huggingface.co/datasets/ByteDance/CloudTimeSeriesData
下载链接
链接失效反馈官方服务:
资源简介:
ByteDance云工作负载数据集是源自字节跳动云服务的四个高质量开源工作负载数据集。这些数据集包含来自数千个计算实例的工作负载数据,时间跨度从1个月到2个月。数据集经过了仔细的预处理,为社区评估和发展新的工作负载预测方法提供了有用的工具。
ByteDance Cloud Workload Dataset is a collection of four high-quality open-source workload datasets sourced from ByteDance's cloud services. These datasets contain workload data from thousands of computing instances, with a time span ranging from 1 month to 2 months. The datasets have undergone careful preprocessing, providing a useful tool for the community to evaluate and develop new workload prediction methods.
提供机构:
上海交通大学; 字节跳动公司; 新南威尔士大学
创建时间:
2025-07-17
原始信息汇总
数据集概述
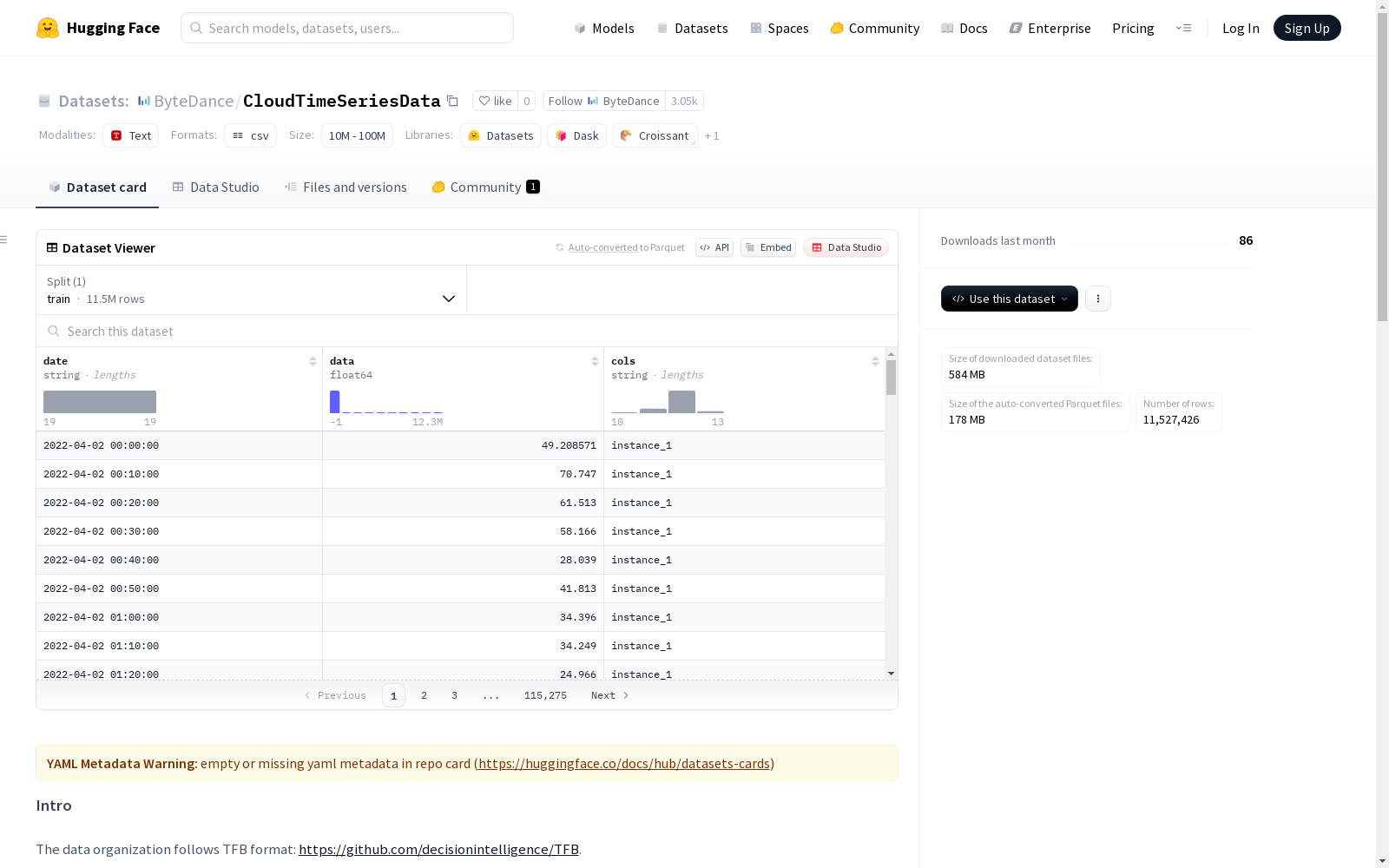
数据格式
- 遵循TFB格式存储时间序列数据,具体规范参考:https://github.com/decisionintelligence/TFB
- 数据表结构包含三列:
- date列:存储时间信息
- 支持字符串、datetime等兼容pd.to_datetime的时间戳格式
- 支持从1开始的整数序列(如1,2,3,...)
- data列:存储对应时间戳的序列值
- cols列:存储变量名称(列名)
- date列:存储时间信息
格式转换示例
原始宽表格式示例:
| date | channel1 | channel2 | channel3 |
|---|---|---|---|
| 1 | 0.1 | 1 | 10 |
| 2 | 0.2 | 2 | 20 |
| 3 | 0.3 | 3 | 30 |
TFB转换后格式:
| date | data | cols |
|---|---|---|
| 1 | 0.1 | channel1 |
| 2 | 0.2 | channel1 |
| 3 | 0.3 | channel1 |
| 1 | 1 | channel2 |
| 2 | 2 | channel2 |
| 3 | 3 | channel2 |
| 1 | 10 | channel3 |
| 2 | 20 | channel3 |
| 3 | 30 | channel3 |
许可证
- 采用CC BY 4.0许可协议
搜集汇总
数据集介绍
构建方式
ByteDance Cloud workload datasets是通过收集字节跳动云服务中数千个计算实例的工作负载数据构建而成,涵盖了从1个月到2个月的时间跨度。数据集经过精心预处理,以确保其高质量和实用性。具体构建过程中,研究人员采用了分钟级粒度的时间序列数据,捕捉了包括CPU使用率、每秒查询数(QPS)等多种工作负载指标。数据集的构建不仅考虑了时间域的特征,还通过频域分析揭示了复杂的周期性模式,为后续的预测模型提供了丰富的信息基础。
特点
该数据集的特点在于其高复杂性和多样性。首先,数据集覆盖了多种云服务类型,包括FaaS(函数即服务)、IaaS(基础设施即服务)、PaaS(平台即服务)和RDS(关系数据库服务),每种服务类型的工作负载模式各不相同。其次,数据集中的时间序列数据表现出复杂的周期性,包括小时、天和周等多个时间尺度的周期性变化。此外,数据集还包含了高频噪声和趋势信息,这些特征在频域中更容易被分离和分析。这些特点使得该数据集成为评估和开发工作负载预测模型的理想选择。
使用方法
ByteDance Cloud workload datasets的使用方法主要包括数据加载、预处理和模型训练三个步骤。用户可以通过Hugging Face平台直接访问数据集,并使用提供的工具进行数据加载。预处理阶段包括数据归一化和频域转换,以便更好地捕捉周期性特征。在模型训练阶段,数据集通常被划分为训练集、验证集和测试集,比例为7:1:2。研究人员可以使用该数据集评估各种时间序列预测模型的性能,特别是在效率和准确性方面的表现。此外,数据集还支持零样本预测和跨数据集迁移学习,为大规模云环境中的工作负载预测提供了强有力的支持。
背景与挑战
背景概述
ByteDance Cloud workload datasets是由字节跳动公司及其合作机构于2025年发布的云计算工作负载时序数据集,旨在解决云服务中资源动态调度的核心挑战。该数据集由上海交通大学与字节跳动研究院联合构建,包含来自PaaS、IaaS、FaaS和RDS四大云服务类型的数千个计算实例的分钟级监控数据,时间跨度达1-2个月。作为首个公开的细粒度多周期云负载数据集,其创新性地采用频域分析方法捕捉工作负载的时变特性,为Transformer架构在云计算预测任务中的应用提供了基准测试平台,显著推动了云原生系统从被动响应到主动预测的技术转型。
当前挑战
该数据集面临双重技术挑战:在领域问题层面,云负载的复杂周期性(如小时/日/周多重周期交织)与高频噪声导致传统时序模型难以实现分钟级精准预测,而Transformer架构的二次计算复杂度无法满足云平台每小时10万次预测的实时性需求;在构建过程中,数据采集需解决多租户环境下的指标异构性问题,频域转换时存在的频率错位(Frequency Mis-alignment)与关键频率组合提取困难(如谐波分离)对数据质量提出严峻考验,同时需平衡商业敏感数据的脱敏处理与科研可用性。
常用场景
经典使用场景
在云计算服务领域,ByteDance Cloud workload datasets数据集被广泛用于工作负载预测模型的训练与评估。该数据集包含数千个计算实例的工作负载数据,时间粒度精细至分钟级别,涵盖了多种云服务类型(如FaaS、IaaS、PaaS和RDS)。其经典使用场景包括基于Transformer架构的预测模型开发,例如论文中提出的Fremer模型,该模型通过频域变换有效捕捉工作负载的复杂周期性模式,为云服务的自动扩展和资源调度提供关键支持。
衍生相关工作
该数据集催生了一系列频域时间序列分析的创新工作,包括频域对齐算法(Learnable Linear Padding)、复数注意力机制(Complex-valued Spectrum Attention)等核心技术的突破。基于此的FEDformer、FilM等衍生模型进一步拓展了频域方法在长期预测中的应用边界。数据集开放的4类云服务负载轨迹(跨度1-2个月)已成为领域基准,被后续研究如FilterNet、FITS等广泛引用,推动形成了'频域表征优于时域'的学术共识。
数据集最近研究
最新研究方向
随着云计算服务的广泛应用,工作负载预测成为优化资源分配和提升服务质量的关键技术。近期,基于Transformer的预测模型在时间序列分析领域取得了显著进展,但其计算效率在大规模云环境中仍面临挑战。针对这一问题,Fremer模型通过频域变换和创新的注意力机制,显著提升了预测效率和准确性。该模型不仅在工作负载预测任务中超越了现有最优模型,还在Kubernetes主动扩展测试中实现了延迟降低18.78%和资源消耗减少2.35%的优异表现。此外,ByteDance Cloud工作负载数据集的发布为研究社区提供了高质量的基准数据,涵盖了数千个计算实例的详细工作负载信息,为未来研究奠定了坚实基础。这一系列进展标志着云计算资源管理向智能化、预测性方向迈出了重要一步,为解决复杂云环境中的动态资源分配问题提供了新的技术路径。
相关研究论文
- 1Fremer: Lightweight and Effective Frequency Transformer for Workload Forecasting in Cloud Services上海交通大学; 字节跳动公司; 新南威尔士大学 · 2025年
以上内容由遇见数据集搜集并总结生成


