COYO-700M 图像-文本对数据集
收藏超神经2024-06-07 更新2024-06-29 收录
下载链接:
https://hyper.ai/cn/datasets/32037
下载链接
链接失效反馈官方服务:
资源简介:
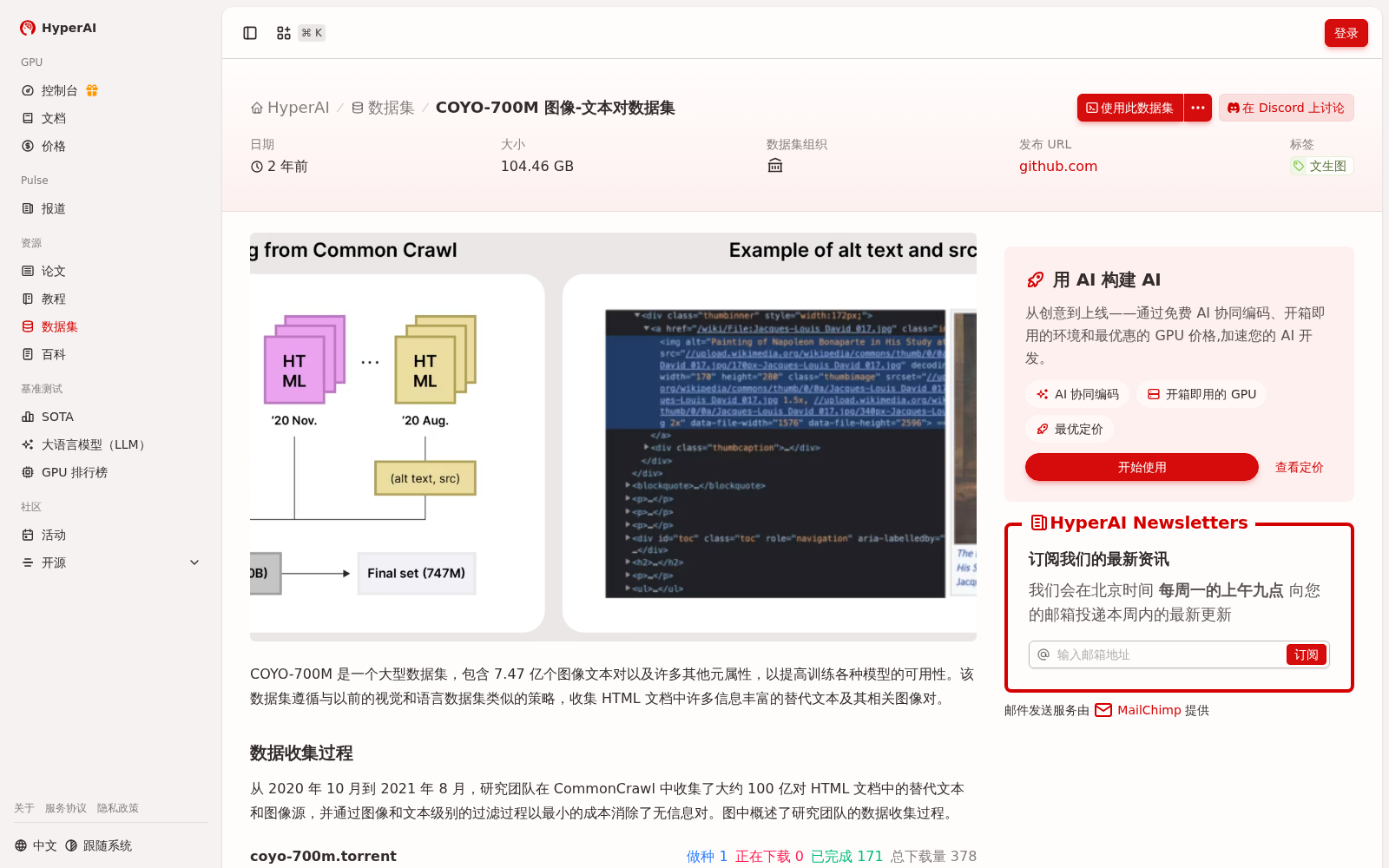
COYO-700M 是一个大型数据集,包含 7.47 亿个图像文本对以及许多其他元属性,以提高训练各种模型的可用性。该数据集遵循与以前的视觉和语言数据集类似的策略,收集 HTML 文档中许多信息丰富的替代文本及其相关图像对。
COYO-700M is a large-scale dataset consisting of 747 million image-text pairs along with numerous additional meta-attributes to enhance the usability for training various models. This dataset follows a similar strategy as prior vision-language datasets, collecting numerous informative alt-texts from HTML documents paired with their associated images.
创建时间:
2024-05-29
搜集汇总
数据集介绍
背景与挑战
背景概述
COYO-700M是一个包含约7.47亿个图像文本对的大型数据集,数据来源于CommonCrawl的HTML文档,通过过滤过程优化了信息质量。该数据集收集于2020年10月至2021年8月,旨在提升训练模型的可用性。
以上内容由遇见数据集搜集并总结生成


