rubenstein-manuscript-catalog-glm-ocr
收藏Hugging Face2026-02-14 更新2026-02-15 收录
下载链接:
https://huggingface.co/datasets/davanstrien/rubenstein-manuscript-catalog-glm-ocr
下载链接
链接失效反馈官方服务:
资源简介:
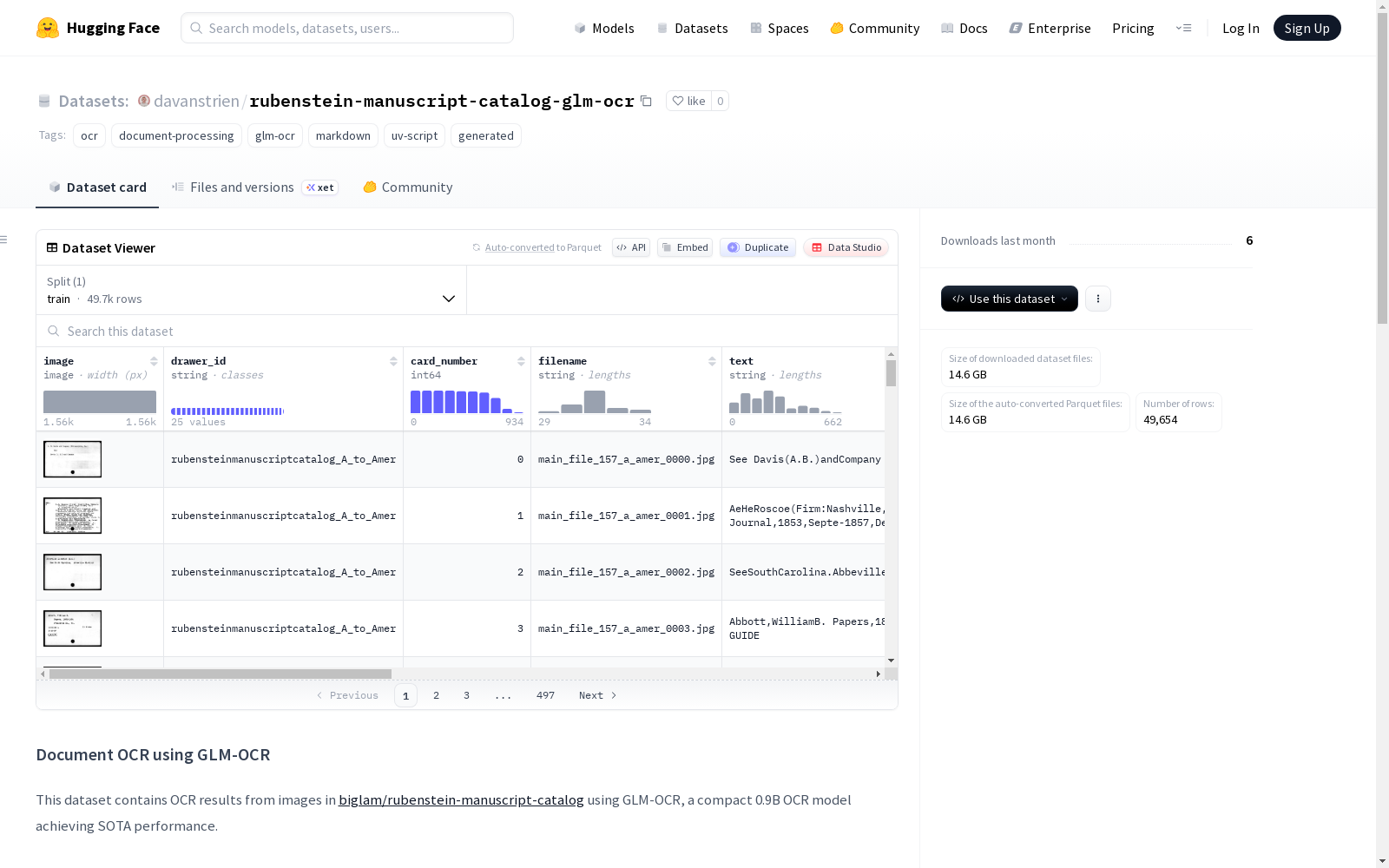
该数据集包含使用GLM-OCR模型对[biglam/rubenstein-manuscript-catalog](https://huggingface.co/datasets/biglam/rubenstein-manuscript-catalog)中的图像进行OCR处理的结果。GLM-OCR是一个紧凑的0.9B参数OCR模型,具有多语言支持(包括中文、英文、法文、西班牙文、俄文、德文、日文和韩文)和高效的文本识别能力。数据集包含49,654个样本,处理时间为343.2分钟。除了原始数据列外,数据集还新增了'markdown'字段(包含以Markdown格式提取的文本)和'inference_info'字段(记录应用于该数据集的所有OCR模型信息)。该数据集适用于文档处理、OCR任务和多语言文本识别等场景。
创建时间:
2026-02-14
原始信息汇总
数据集概述
数据集基本信息
- 数据集名称: Document OCR using GLM-OCR
- 数据集地址: https://huggingface.co/datasets/davanstrien/rubenstein-manuscript-catalog-glm-ocr
- 主要标签: OCR、文档处理、GLM-OCR、Markdown、UV脚本、生成式
数据来源与处理
- 源数据集: biglam/rubenstein-manuscript-catalog (https://huggingface.co/datasets/biglam/rubenstein-manuscript-catalog)
- 处理任务: 文本识别
- 处理模型: zai-org/GLM-OCR (https://huggingface.co/zai-org/GLM-OCR)
- 样本数量: 49,654
- 处理时间: 343.2 分钟
- 处理日期: 2026-02-14 15:38 UTC
处理配置
- 图像列:
image - 输出列:
markdown - 数据集划分:
train - 批处理大小: 64
- 最大模型长度: 8,192 tokens
- 最大输出tokens: 8,192
- Temperature: 0.01
- Top P: 1e-05
- GPU内存使用率: 95.0%
模型信息
- 模型名称: GLM-OCR
- 参数量: 0.9B
- 性能: 在OmniDocBench V1.5上达到94.62%
- 架构: CogViT视觉编码器 + GLM-0.5B语言解码器
- 训练损失: 多令牌预测损失
- 支持语言: 中文、英文、法文、西班牙文、俄文、德文、日文、韩文
- 许可证: MIT
数据结构
- 包含列: 所有原始列,以及:
markdown: 以Markdown格式提取的文本inference_info: 记录应用于此数据集的所有OCR模型的JSON列表
复现方法
使用以下命令复现处理过程: bash uv run https://huggingface.co/datasets/uv-scripts/ocr/raw/main/glm-ocr.py biglam/rubenstein-manuscript-catalog <output-dataset> --image-column image --batch-size 64 --task ocr
生成信息
- 生成工具: UV Scripts (https://huggingface.co/uv-scripts)
搜集汇总
数据集介绍
构建方式
在数字人文与档案学领域,光学字符识别技术对于历史文献的数字化处理至关重要。本数据集基于原始手稿目录数据集,采用先进的GLM-OCR模型进行自动化文本提取。具体构建过程中,模型以图像列为输入,通过批量处理方式,在高效利用GPU资源的配置下,将视觉信息转化为结构化的Markdown格式文本,最终生成了包含四万余样本的增强版本。
使用方法
对于希望利用本数据集的研究者,可通过提供的复制脚本快速重现处理流程。使用时应指定图像列参数并配置适当的批处理大小,模型能够自动执行端到端的文本识别任务。生成的Markdown格式文本可直接用于后续的文本挖掘、信息检索或数字档案构建等学术研究与应用开发。
背景与挑战
背景概述
在数字人文与档案学领域,历史手稿的数字化与文本识别是保存文化遗产、促进学术研究的关键环节。rubenstein-manuscript-catalog-glm-ocr数据集于2026年2月由相关研究团队基于GLM-OCR模型构建,其核心目标在于解决手稿图像中复杂版面、古旧字体及多语言文本的自动识别问题。该数据集源自biglam/rubenstein-manuscript-catalog,通过先进的视觉-语言模型架构,将约4.9万份手稿图像转化为结构化Markdown文本,显著提升了历史文献的可访问性与分析效率,为古籍数字化、文本挖掘等跨学科研究提供了高质量数据基础。
当前挑战
该数据集致力于应对历史手稿光学字符识别中的多重挑战:手稿常包含褪色墨迹、复杂版面布局、多样书写风格及多语言混杂,传统OCR方法在此类场景下准确率有限。构建过程中,团队需处理大规模图像数据的计算负载,确保GLM-OCR模型在有限GPU内存下高效运行;同时,保持文本输出的格式一致性、避免标记化过程中的信息损失,并在多语言识别中平衡性能与泛化能力,均是实现高精度转录的关键难点。
常用场景
经典使用场景
在数字人文与历史档案学领域,手稿文献的数字化处理是保存与传播文化遗产的关键环节。rubenstein-manuscript-catalog-glm-ocr数据集通过GLM-OCR模型,将原始图像中的手写或印刷文本转换为结构化的Markdown格式,为学者提供了高效、准确的文本识别基础。这一过程不仅实现了手稿内容的大规模机器可读化,还支持后续的文本分析、语义检索与知识挖掘,成为连接原始文献与计算研究的重要桥梁。
解决学术问题
该数据集有效应对了历史手稿数字化中的核心挑战,即高精度光学字符识别在复杂版面与多语言环境下的实现。通过集成先进的CogViT视觉编码器与GLM语言解码器,它显著提升了手写体与印刷体混合文本的识别率,解决了传统OCR技术在古籍处理中准确率不足的问题。其多语言支持能力进一步拓展了跨文化文献研究的边界,为档案学、语言学与数字人文领域的定量分析提供了可靠的数据支撑。
实际应用
在实际应用中,该数据集可直接服务于图书馆、档案馆及博物馆的数字化典藏系统,实现手稿目录的自动化编目与全文检索。教育机构可借助其构建历史文献教学资源库,支持互动式学习与可视化研究。此外,在文化遗产保护项目中,该数据集能够加速濒危文献的抢救性数字化进程,并通过开放数据协议促进全球学术资源的共享与协作。
数据集最近研究
最新研究方向
在古籍手稿数字化领域,光学字符识别技术的进步正推动着文化遗产的深度解析与利用。基于GLM-OCR模型生成的鲁宾斯坦手稿目录数据集,其最新研究聚焦于多语言混合文本的精准识别与结构化处理,结合视觉编码器与语言解码器的协同优化,显著提升了复杂历史文献的转录效率。前沿探索进一步将注意力转向跨模态知识融合,利用多令牌预测损失机制增强模型对模糊或破损字迹的鲁棒性,同时支持Markdown格式输出以促进学术标注与机器可读性。这一方向不仅呼应了全球数字人文项目中对自动化工具的需求,也为大规模手稿库的语义检索与智能分析奠定了技术基础,具有重要的学术与保存价值。
以上内容由遇见数据集搜集并总结生成


