FineWeb
收藏Hugging Face2024-12-12 收录
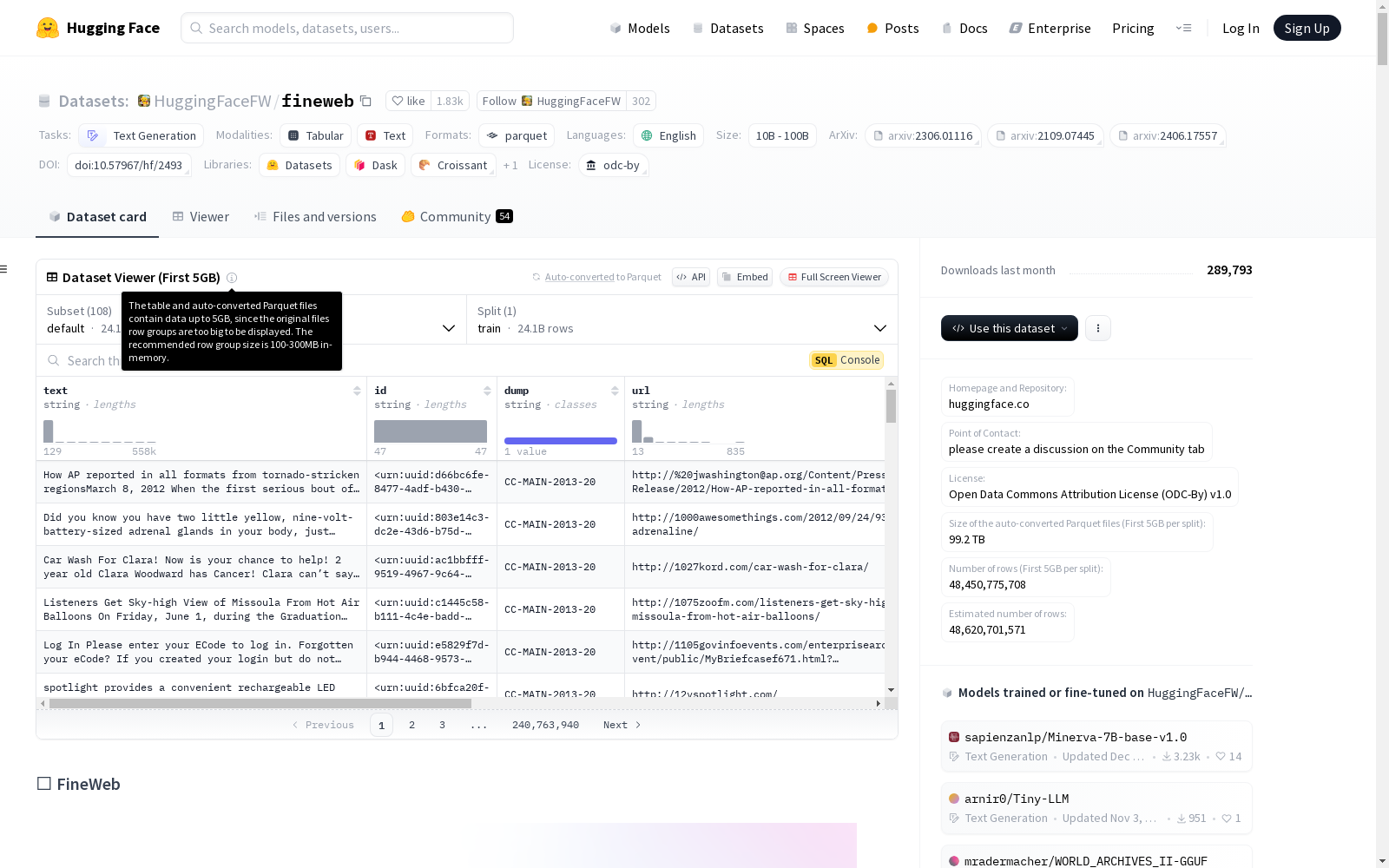
下载链接:
https://huggingface.co/datasets/HuggingFaceFW/fineweb
下载链接
链接失效反馈官方服务:
资源简介:
FineWeb是一个由Hugging Face提供的大规模英语网页数据集,包含超过15万亿个经过清洗和去重的Token。该数据集基于95个CommonCrawl数据集构建,总数据量达45TB。这些数据集覆盖了从2013年夏季至2024年3月的网络数据,涵盖了英语领域的广泛主题。FineWeb的主要目标是为研究公共数据在大模型(LLM)预训练中的应用提供资源。通过使用datatrove库对CommonCrawl数据进行精细处理、过滤和去重,FineWeb成为了目前最大且公开可用的干净的LLM预训练数据集。在FineWeb上训练的模型在性能上超越了RefinedWeb、C4、DolmaV1.6、The Pile和SlimPajama等其他数据集。
FineWeb is a large-scale English web dataset provided by Hugging Face, containing over 15 trillion cleaned and deduplicated Tokens. Constructed from 95 CommonCrawl datasets, this corpus has a total size of 45 TB. It covers web data spanning from the summer of 2013 to March 2024, encompassing a broad range of English-language topics. The primary goal of FineWeb is to provide resources for researching the application of public data in large language model (LLM) pre-training. By leveraging the datatrove library to conduct fine-grained processing, filtering and deduplication on CommonCrawl data, FineWeb has become the largest and most publicly available clean LLM pre-training dataset to date. Models trained on FineWeb outperform those trained on other datasets such as RefinedWeb, C4, DolmaV1.6, The Pile and SlimPajama.
搜集汇总
数据集介绍
构建方式
FineWeb数据集是通过对CommonCrawl的英文网页数据进行清洗和去重构建而成,旨在为大语言模型(LLM)提供高质量的训练数据。数据处理流程基于HuggingFace的`datatrove`库,该库专为大规模数据处理设计。数据集涵盖了自2013年以来的所有CommonCrawl快照,并通过额外的过滤步骤进一步提升了数据质量。所有数据处理代码均已开源,确保结果的可复现性。
使用方法
FineWeb数据集可以通过多种方式加载和使用。用户可以通过`datatrove`库直接读取和处理数据,也可以通过`huggingface_hub`或`datasets`库进行下载和加载。数据集支持按特定CommonCrawl快照或样本子集进行加载,用户可以根据需求选择合适的数据规模。此外,数据集还提供了详细的评估结果和代码,便于用户复现和验证实验结果。
背景与挑战
背景概述
FineWeb数据集是由HuggingFace团队于2024年发布的一个大规模英文网络文本数据集,旨在为自然语言处理领域提供高质量的预训练数据。该数据集基于CommonCrawl的网页抓取数据,经过精心清洗和去重处理,包含了超过15万亿个token。FineWeb的构建初衷是为了复现并超越RefinedWeb数据集,通过引入额外的过滤步骤,FineWeb在语言模型性能上表现更为优异。该数据集的发布不仅推动了大规模语言模型的研究,还为开源社区提供了高质量的训练资源,进一步促进了自然语言处理技术的发展。
当前挑战
FineWeb数据集在构建过程中面临了多重挑战。首先,数据清洗和去重是核心问题之一,如何在保留高质量文本的同时去除噪声和重复内容,是数据集构建的关键。其次,数据量庞大带来的存储和计算资源需求也是一个显著挑战,尤其是在处理超过15万亿个token时,如何高效地进行数据管理和处理成为了技术难点。此外,数据的时间跨度较大,涵盖了从2013年至今的多个CommonCrawl抓取版本,如何确保不同时间段数据的一致性和质量也是一个复杂的问题。最后,尽管FineWeb在性能上超越了多个现有数据集,但如何进一步提升数据质量,尤其是在特定领域任务上的表现,仍然是未来需要探索的方向。
常用场景
经典使用场景
FineWeb数据集作为大规模语言模型训练的基础数据源,广泛应用于自然语言处理领域。其经典使用场景包括语言模型的预训练和微调,尤其是在生成式任务中表现突出。通过FineWeb提供的15万亿个经过清洗和去重的英文网页数据,研究人员能够构建出性能卓越的语言模型,显著提升文本生成、翻译和问答等任务的准确性。
解决学术问题
FineWeb数据集解决了大规模语言模型训练中数据质量和多样性的关键问题。通过优化数据处理流程,FineWeb不仅提供了高质量的数据,还显著提升了模型在多个基准任务上的表现。该数据集为研究人员提供了一个可靠的基准,帮助他们探索数据过滤、去重和清洗的最佳实践,从而推动了语言模型领域的学术研究进展。
实际应用
在实际应用中,FineWeb数据集被广泛用于构建和优化商业级语言模型。例如,基于FineWeb训练的模型可以应用于智能客服、自动文本生成、内容推荐系统等场景。其高质量的数据确保了模型在实际应用中的稳定性和准确性,帮助企业提升用户体验和运营效率。
数据集最近研究
最新研究方向
FineWeb数据集作为大规模语言模型训练的关键资源,近年来在自然语言处理领域引起了广泛关注。该数据集涵盖了自2013年以来的CommonCrawl数据,经过精心清洗和去重处理,提供了超过15万亿个高质量的英文文本标记。FineWeb的独特之处在于其优化的数据处理流程,显著提升了语言模型的性能表现,超越了RefinedWeb等同类数据集。当前的研究热点集中在如何进一步优化数据过滤策略,以提升数据集的多样性和质量。此外,FineWeb的开源特性使得研究者能够基于其进行大规模的模型训练和评估,推动了语言模型在生成任务、文本分类和机器翻译等领域的应用。随着数据集的不断更新和扩展,FineWeb有望成为未来语言模型研究的重要基准之一。
以上内容由遇见数据集搜集并总结生成


