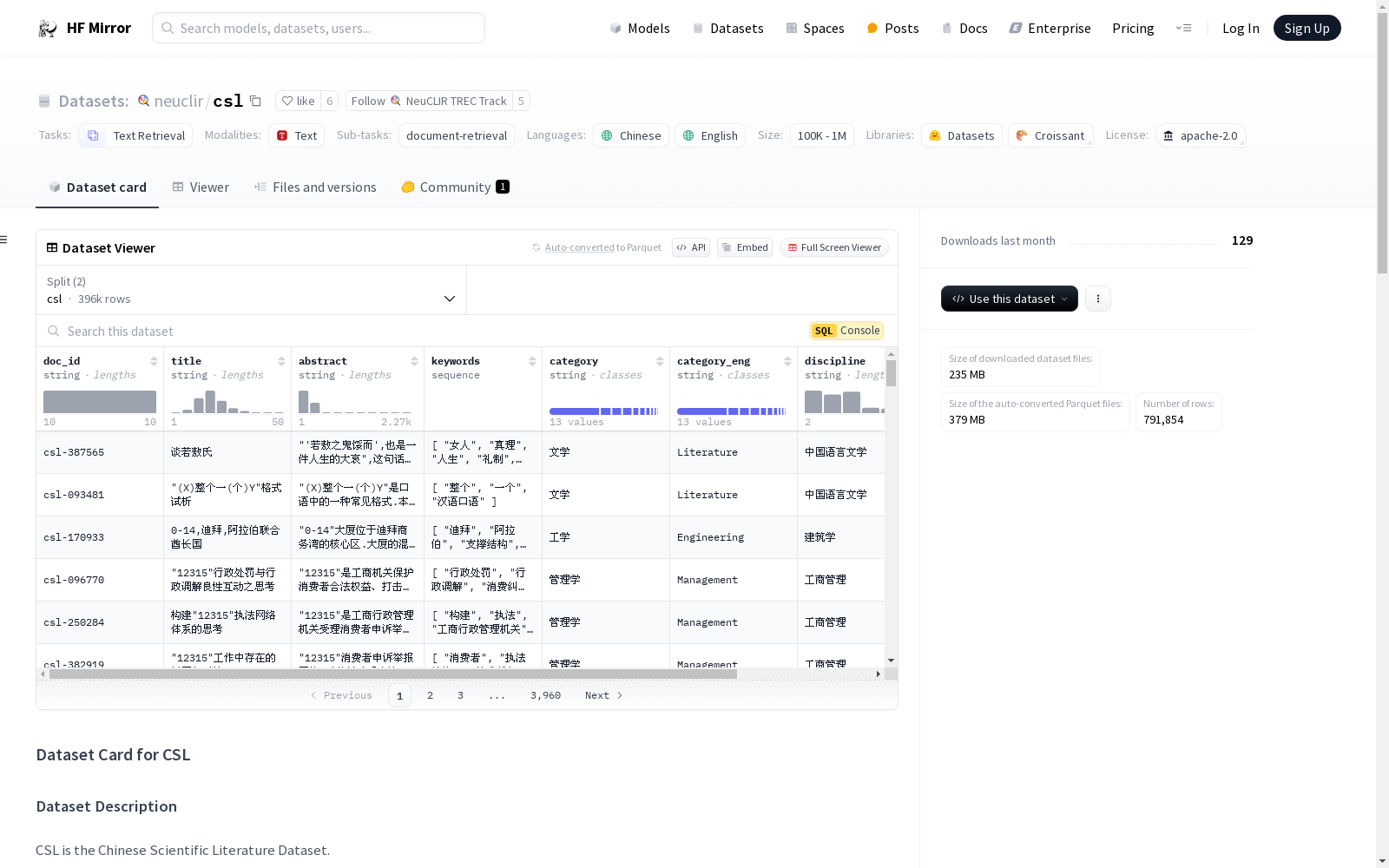
neuclir/csl
收藏CSL 数据集概述
数据集描述
CSL(Chinese Scientific Literature Dataset)是一个包含中文论文标题、摘要、关键词的数据集,涵盖多个学术领域。
数据集摘要
- 内容: 包含论文的标题、摘要、关键词。
- 语言: 中文和英文翻译。
数据集结构
数据实例
| 分割 | 文档数量 |
|---|---|
csl |
396k |
en_translation |
396k |
数据字段
doc_id: 文档唯一标识符。title: 论文标题。abstract: 论文摘要。keywords: 与论文相关的关键词。category: 论文的广义分类。category_eng: 广义分类的英文翻译。discipline: 学术学科。discipline_eng: 学术学科的英文翻译。
en_translation 包含由Google翻译服务翻译的文档,所有文本为英文,因此省略了 category_eng 和 discipline_eng 字段。
数据集使用
使用 🤗 Datasets 加载数据集的示例代码:
python from datasets import load_dataset
dataset = load_dataset(neuclir/csl)[csl]
许可证与引用
- 许可证: Apache 2.0
引用信息:
@inproceedings{li-etal-2022-csl, title = "{CSL}: A Large-scale {C}hinese Scientific Literature Dataset", author = "Li, Yudong and Zhang, Yuqing and Zhao, Zhe and Shen, Linlin and Liu, Weijie and Mao, Weiquan and Zhang, Hui", booktitle = "Proceedings of the 29th International Conference on Computational Linguistics", month = oct, year = "2022", address = "Gyeongju, Republic of Korea", publisher = "International Committee on Computational Linguistics", url = "https://aclanthology.org/2022.coling-1.344", pages = "3917--3923", }