white-training-data
收藏Hugging Face2026-02-12 更新2026-02-13 收录
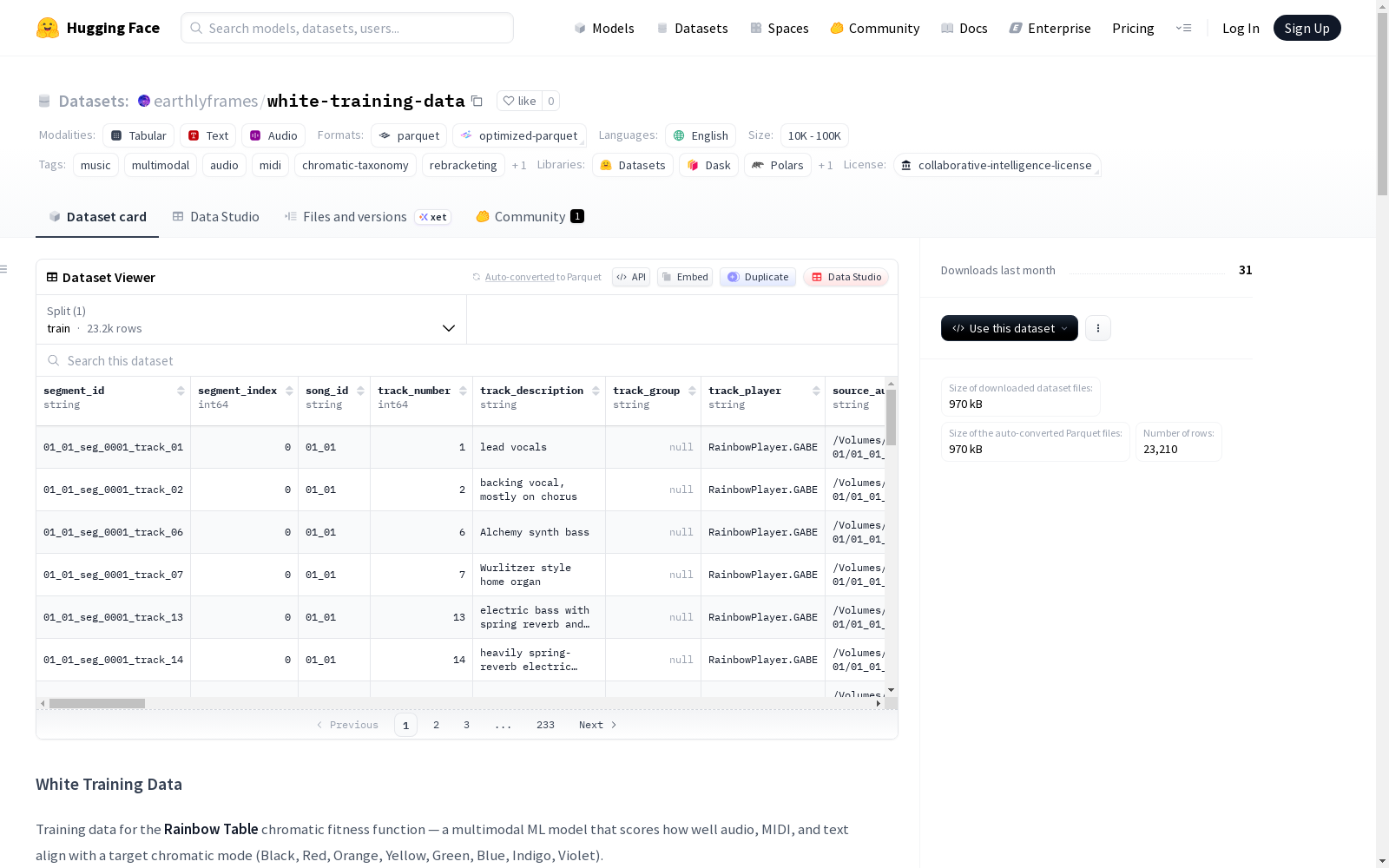
下载链接:
https://huggingface.co/datasets/earthlyframes/white-training-data
下载链接
链接失效反馈官方服务:
资源简介:
White Training Data 数据集是 'The Earthly Frames' 项目的一部分,旨在为进化音乐创作提供训练数据。该数据集用于评估音频、MIDI 和文本与目标色彩模式(黑、红、橙、黄、绿、蓝、靛、紫)的对齐程度,是 Rainbow Table 色彩适应度函数的多模态机器学习模型的训练数据。数据集包含 83 首原创歌曲,分为 8 种色彩专辑,每首歌曲都是人类与 AI 的有意识合作创作。数据集结构包括基础元数据(base_manifest)、训练片段(training_segments)和完整训练表(training_full),其中完整训练表是主要的训练数据表,包含目标色彩标签、文本概念、歌词、音乐元数据等关键特征。此外,数据集还提供了可播放的音频预览(preview),支持 FLAC 编码的 44.1kHz 音频。数据集适用于进化音乐创作、多模态融合模型训练等任务,并遵循 Collaborative Intelligence License v1.0 许可。
The White Training Data dataset is part of the "The Earthly Frames" project, which aims to provide training data for evolutionary music composition. This dataset is used to evaluate the alignment between audio, MIDI, text and target color modes (black, red, orange, yellow, green, blue, indigo, violet), and serves as training data for multimodal machine learning models of the Rainbow Table color fitness function. The dataset includes 83 original songs divided into 8 color-themed albums, each of which is a consciously collaborative creation between humans and AI. The dataset structure encompasses basic metadata (base_manifest), training segments (training_segments), and the full training table (training_full), where the full training table is the primary training data table containing key features such as target color labels, text concepts, lyrics, music metadata and other critical characteristics. Additionally, the dataset provides playable audio previews that support FLAC-encoded 44.1 kHz audio. This dataset is applicable to tasks such as evolutionary music composition and multimodal fusion model training, and is licensed under Collaborative Intelligence License v1.0.
创建时间:
2026-02-10
原始信息汇总
White Training Data 数据集概述
基本描述
- 数据集名称:White Training Data
- 主要用途:为“彩虹表”色彩适应度函数提供训练数据。该函数是一个多模态机器学习模型,用于评估音频、MIDI和文本与目标色彩模式(黑、红、橙、黄、绿、蓝、靛、紫)的契合程度。
- 所属项目:The Earthly Frames 项目,旨在实现人类创造力与人工智能的有意识协作。
- 核心功能:作为进化音乐创作的适应度函数,而非独立的分类器。
版本信息
- 当前版本:v0.2.0
- 发布日期:2026-02-12
数据集结构
数据集包含四个配置:
| 配置名称 | 数据行数 | 描述 |
|---|---|---|
base_manifest |
1,327 | 曲目级元数据:歌曲信息、概念、音乐调性、色彩标签、训练目标。 |
training_segments |
11,605 | 时间对齐的片段,包含歌词文本、结构段落、音频/MIDI覆盖标志。 |
training_full |
11,605 | 片段与清单元数据连接后的主训练表。 |
preview |
11,605 | 包含可播放音频的预览数据,字段与training_full相同,并增加了音频特征。 |
各色彩模式数据覆盖情况
| 色彩 | 片段数 | 音频覆盖率 | MIDI覆盖率 | 文本覆盖率 |
|---|---|---|---|---|
| 黑 | 1,748 | 83.0% | 58.5% | 100.0% |
| 红 | 1,474 | 93.7% | 48.6% | 90.7% |
| 橙 | 1,731 | 83.8% | 51.1% | 100.0% |
| 黄 | 656 | 88.0% | 52.9% | 52.6% |
| 绿 | 393 | 90.1% | 69.5% | 0.0% |
| 紫 | 2,100 | 75.9% | 55.6% | 100.0% |
| 靛 | 1,406 | 77.2% | 34.1% | 100.0% |
| 蓝 | 2,097 | 96.0% | 12.1% | 100.0% |
注意:音频波形和MIDI二进制文件单独存储(因体积原因未包含在元数据配置中)。preview配置包含用于探索的可播放音频。媒体parquet文件(约15 GB)在训练期间本地使用。
关键特征(主训练表 training_full)
rainbow_color:目标色彩标签(黑/红/橙/黄/绿/蓝/靛/紫)。rainbow_color_temporal_mode/rainbow_color_ontological_mode:模式维度的回归目标。concept:描述歌曲叙事内容的文本概念。lyric_text:片段级歌词(如可用)。bpm,key_signature_note,key_signature_mode:音乐元数据。training_data:包含计算特征的结构体,如重新分组类型/强度、叙事复杂性、边界流动性等。has_audio/has_midi:模态可用性标志。start_seconds/end_seconds:片段时间边界。
使用方式
可通过 datasets 库加载不同配置:
python
from datasets import load_dataset
training = load_dataset("earthlyframes/white-training-data", "training_full")
preview = load_dataset("earthlyframes/white-training-data", "preview")
manifest = load_dataset("earthlyframes/white-training-data", "base_manifest")
segments = load_dataset("earthlyframes/white-training-data", "training_segments")
加载特定版本
training = load_dataset("earthlyframes/white-training-data", "training_full", revision="v0.2.0")
训练结果(仅文本,第1-4阶段)
| 任务 | 指标 | 结果 |
|---|---|---|
| 二元分类(是否重新分组) | 准确率 | 100% |
| 多类分类(重新分组类型) | 准确率 | 100% |
| 时间模式回归 | 模式准确率 | 94.9% |
| 本体模式回归 | 模式准确率 | 92.9% |
| 空间模式回归 | 模式准确率 | 61.6% |
空间模式回归的瓶颈在于器乐专辑(黄、绿)缺乏文本。正在进行的多模态融合模型(第3阶段)将纳入音频和MIDI嵌入以解决此问题。
数据来源
- 包含8张色彩专辑中的83首歌曲。
- 每首歌曲均为人类与AI有意识协作创作。
- 所有源音频均为原创,无采样或授权材料。
许可协议
- 许可证名称:Collaborative Intelligence License v1.0
- 许可证链接:https://github.com/brotherclone/white/blob/main/COLLABORATIVE_INTELLIGENCE_LICENSE.md
- 核心精神:该作品代表了人类创造力与AI之间的有意识伙伴关系。双方均具有能动性;共享必须获得双方同意。
搜集汇总
数据集介绍
构建方式
在音乐信息检索与生成式人工智能的交叉领域,white-training-data数据集作为进化音乐创作流程的核心组件被精心构建。其构建过程植根于一个系统化的多模态数据整合框架,首先从83首原创歌曲中提取音轨级元数据,形成基础清单。随后,通过时间对齐技术将每首歌曲分割为具有明确起止时间的片段,并关联歌词文本、结构段落以及音频与MIDI的覆盖标志。最终,通过连接片段数据与音轨元数据,生成了包含11,605个样本的主训练表,确保了音频波形、MIDI二进制数据与文本描述在色彩分类目标下的结构化对齐。
使用方法
为支持进化音乐创作系统的研发,该数据集提供了清晰的使用路径。研究者可通过Hugging Face的`datasets`库,灵活加载不同配置的数据子集:主训练表`training_full`适用于多模态模型的综合训练;`preview`配置则包含可播放音频,便于直观分析与模型调试;`base_manifest`和`training_segments`则分别提供音轨级元数据与原始片段信息,支持细粒度研究。加载时可通过指定版本号确保实验的可复现性,整个接口设计旨在便捷地服务于从概念生成到音乐片段色彩一致性评估的完整算法流水线。
背景与挑战
背景概述
在人工智能与音乐创作的交叉领域,White Training Data数据集作为“彩虹表”色彩适应度函数的训练数据,于2026年2月由Earthly Frames项目团队发布,标志着人类创造力与机器学习模型协同进化作曲的新范式。该数据集源自八张色彩专辑中的83首原创歌曲,旨在通过多模态对齐评估音频、MIDI与文本在目标色彩模式上的一致性,核心研究问题聚焦于构建能够驱动进化音乐生成的适应度函数,从而为自动化音乐创作系统提供可量化的美学评判标准,对计算音乐学与生成艺术领域产生了深远影响。
当前挑战
该数据集致力于解决进化音乐作曲中多模态对齐的复杂挑战,即如何精准量化音频、符号音乐数据与文本概念在抽象色彩维度上的协调性,这要求模型超越传统分类任务,实现跨模态语义融合与回归预测。在构建过程中,面临数据覆盖不均衡的难题,例如绿色与黄色专辑因缺乏文本内容导致空间模式回归准确率受限,同时音频与MIDI模态的可用性在不同色彩类别间存在显著差异,增加了多模态特征提取与融合的复杂性。
常用场景
经典使用场景
在音乐信息检索与生成领域,white-training-data数据集为进化音乐创作提供了关键支撑。其经典使用场景体现在训练Rainbow Table色彩适应度函数,该模型通过多模态对齐评估音频、MIDI与文本数据与目标色彩模式的一致性。研究者在音乐生成流水线中,利用该数据集对和弦进行变体评分,筛选出符合特定色彩情感表达的音乐片段,从而推动自动化作曲系统向更具艺术一致性的方向发展。
解决学术问题
该数据集有效解决了多模态音乐表征中的语义对齐难题。通过引入色彩本体论与时间模式回归目标,它将抽象的音乐情感映射到可量化的特征空间,使得机器学习模型能够理解音乐元素与色彩概念之间的复杂关联。这为音乐理论中的调性分析与情感计算研究提供了实证基础,并突破了传统分类模型在创造性任务中的局限性,促进了进化算法在艺术生成领域的应用。
实际应用
在实际应用中,该数据集支撑了端到端的智能音乐制作系统。从概念生成到最终评估,系统可自动产生并筛选与特定色彩主题匹配的音乐作品,辅助作曲家进行创意探索。例如,在影视配乐或游戏音效设计中,创作者可指定“蓝色”调性来生成冷静氛围的片段,显著提升内容生产的效率与艺术可控性,体现了人机协作在创意产业中的实践价值。
数据集最近研究
最新研究方向
在音乐信息检索与生成式人工智能交叉领域,White Training Data作为支持进化音乐合成的多模态数据集,正推动着基于色彩语义的音乐创作系统前沿探索。研究焦点集中在利用其音频、MIDI与文本对齐的彩虹表色度适应函数,开发能够理解色彩情感映射的深度神经网络。当前热点在于通过时序模式与本体模式回归模型,解决乐器专辑中空间模式预测的瓶颈,并融合跨模态嵌入以实现更精准的音乐结构生成。这类研究不仅拓展了人机协同创作的可能性,也为音乐理论的计算建模提供了新的实证基础。
以上内容由遇见数据集搜集并总结生成


