kf-embed-pretrain-corpus-700M
收藏Hugging Face2026-04-13 更新2026-04-14 收录
下载链接:
https://huggingface.co/datasets/KiteFishAI/kf-embed-pretrain-corpus-700M
下载链接
链接失效反馈官方服务:
资源简介:
KF-Embed Pretraining Corpus 是一个用于预训练多语言嵌入模型的大规模数据集,特别强调对印度语言的支持。该数据集汇集了16个不同的开源数据集,包含7.1亿个(查询,正例)对,覆盖50多种语言,总大小为128GB。每个记录包含三个字段:'source'(来源数据集标识)、'query'(查询文本如标题、问题等)和'positive'(相关联的长文本如文章正文、答案等)。数据集涵盖多种领域,包括电子商务评论、科学文献、代码、多语言新闻、维基百科、问答对和印度地区语言内容。主要应用场景包括对比预训练、多语言密集检索模型训练、句子相似度和语义搜索模型开发,以及需要大规模多语言训练数据的印度自然语言处理研究。数据集采用JSONL格式,遵循MIT许可证,但用户需确保遵守各源数据集的原始许可。
创建时间:
2026-04-03
原始信息汇总
KF-Embed Pretrain Corpus 700M 数据集概述
基本信息
- 数据集名称: KF-Embed Pretrain Corpus 700M
- 发布者: KiteFishAI
- 发布日期: 2026年
- 许可证: MIT License
- 数据集大小: 128 GB
- 记录总数: 710,388,432 条 (query, positive) 对
- 数据格式: JSONL
- 主要用途: 用于对比预训练多语言嵌入模型(如 Minnow-Em-v1),支持多语言密集检索、句子相似性和语义搜索模型开发,以及需要大规模多语言训练数据的印度语言 NLP 研究。
语言覆盖
- 印度语言(原生覆盖): 印地语、孟加拉语、马拉地语、泰米尔语、泰卢固语、古吉拉特语、旁遮普语、马拉雅拉姆语、卡纳达语、奥里亚语、阿萨姆语、乌尔都语、尼泊尔语、僧伽罗语。
- 其他语言(通过多语言子集): 阿拉伯语、中文、法语、德语、西班牙语、葡萄牙语、俄语、日语、韩语、印尼语、斯瓦希里语、约鲁巴语、波斯语、芬兰语、泰语、越南语、荷兰语、意大利语、土耳其语、波兰语、罗马尼亚语等,以及通过
multilingual_cc_news和xP3all覆盖的 80 多种语言。
数据构成与来源
数据集聚合了 16 个不同的开源数据集,统一为 (query, positive) 对格式。
数据文件统计
| 文件 | 记录数 | 大小 (GB) | 领域 | 语言 |
|---|---|---|---|---|
amazon_user_reviews.jsonl |
571,497,789 | 88.14 | 电子商务评论 | 英语 |
s2orc.jsonl |
51,030,086 | 11.66 | 科学文献 | 英语 |
paq_pairs.jsonl |
64,371,441 | 10.00 | 问答对 | 英语 |
xP3all.jsonl |
9,200,000 | 9.10 | 指令遵循 | 46种语言 |
wikipedia.jsonl |
6,407,814 | 2.28 | 百科全书 | 英语 |
arxiv.jsonl |
2,989,022 | 3.42 | 科学摘要 | 英语 |
hindi.jsonl |
333,242 | 1.62 | 新闻文章 | 印地语 |
tamil_news.jsonl |
300,000 | 1.07 | 新闻文章 | 泰米尔语 |
codesearchnet.jsonl |
1,880,853 | 2.01 | 代码+文档字符串 | 6种编程语言 |
swim-ir-monolingual.jsonl |
902,504 | 0.83 | 信息检索段落 | 10种语言 |
multilingual_cc_news.jsonl |
154,086 | 0.45 | 新闻 | 100+种语言 |
telugu_news.jsonl |
102,332 | 0.35 | 新闻文章 | 泰卢固语 |
swim-ir-cross-lingual.jsonl |
850,000 | 0.14 | 跨语言信息检索 | 17种语言 |
bengaliNews.jsonl |
114,434 | 0.10 | 新闻文章 | 孟加拉语 |
marathi.jsonl |
99,957 | 0.26 | 指令问答 | 马拉地语 |
refinedweb.jsonl |
154,872 | 0.29 | 网络爬取 | 英语 |
源数据集列表
- Amazon Reviews 2023: 查询字段为评论标题,正例字段为评论文本。
- Semantic Scholar ORC: 查询字段为论文标题,正例字段为引用文本。
- PAQ Pairs: 查询字段为问题,正例字段为答案。
- xP3all: 查询字段为提示输入,正例字段为目标输出。
- Wikipedia (EN): 查询字段为文章标题,正例字段为第一章节。
- ArXiv: 查询字段为论文标题,正例字段为摘要。
- Hindi News: 查询字段为标题,正例字段为文章。
- Tamil News: 查询字段为新闻标题,正例字段为文章。
- CodeSearchNet: 查询字段为文档字符串,正例字段为函数代码。
- SWIM-IR Monolingual: 查询字段为查询,正例字段为段落。
- Multilingual CC News: 查询字段为标题,正例字段为正文。
- Telugu News: 查询字段为标题,正例字段为文章。
- SWIM-IR Cross-Lingual: 查询字段为语言,正例字段为查询。
- Bengali News: 查询字段为标题,正例字段为要点。
- Marathi Orca: 查询字段为问题(马拉地语),正例字段为回答(马拉地语)。
- Falcon RefinedWeb: 查询字段为从URL派生的标题,正例字段为网页内容。
数据模式
每条记录包含以下字段: json { "source": "dataset_name", "query": "...", "positive": "..." }
source: 标识源数据集和子集。query: 短锚文本(如标题、问题、文档字符串等)。positive: 较长的关联段落(如文章正文、答案、代码、摘要等)。
预处理说明
- Amazon Reviews: 用户评论和商品元数据分开处理。评论标题作为查询,评论文本作为正例。
- Wikipedia: 仅使用第一章节(第一个双换行符之前)作为正例,以避免文档过长。
- ArXiv: 标题-摘要对。文本经过空格标准化和清理。
- RefinedWeb: URL路径被解析并清理为人类可读的标题作为查询字段。
- CodeSearchNet: 源语言编码在
source字段中(例如codesearch_python)。 - Multilingual CC News: 超过 10,000 条记录的子集被限制为每种语言 10,000 条以保持平衡。
- SWIM-IR: 跨语言子集被限制为每种语言 50,000 条;单语言子集为每种语言 100,000 条。
- xP3all: 每个语言子集被限制为 200,000 条记录。
- Tamil News: 被限制为 300,000 条记录。
引用信息
如果使用此数据集,请引用 KiteFishAI 及相应的源数据集: bibtex @dataset{kitefishai_kfembed_corpus_2026, author = {KiteFishAI}, title = {KF-Embed Pretraining Corpus}, year = {2026}, publisher = {Hugging Face}, url = {https://huggingface.co/datasets/KiteFishAI/kf-embed-pretrain-corpus-700M}, note = {Aggregated pretraining corpus for KF-Embed multilingual embedding models. 710M (query, positive) pairs across 16 source datasets.} }
请根据情况同时引用各个源数据集。
许可证说明
本数据集根据 MIT 许可证发布。各个源数据集保留其原始许可证。用户在下游应用中使用前,有责任确保遵守各组成源的许可证要求。
搜集汇总
数据集介绍
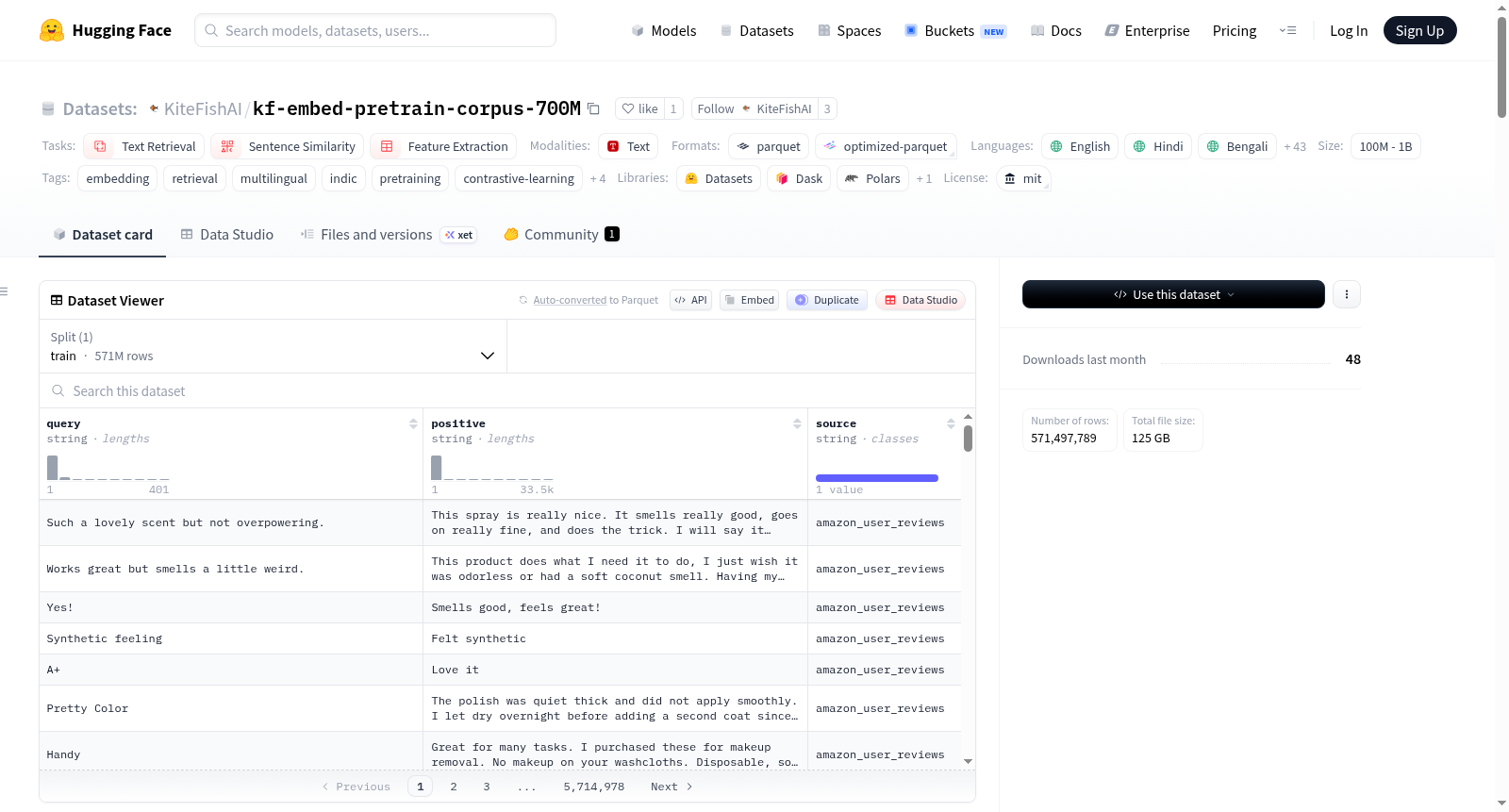
构建方式
在构建多语言嵌入模型的背景下,KF-Embed预训练语料库通过整合16个开源数据集,精心构建了超过7.1亿个(查询,正例)对。该构建过程遵循统一的JSONL格式,每个记录包含源数据集标识、查询文本及关联的正例文本。数据来源覆盖电子商务评论、科学文献、代码文档、多语言新闻、维基百科、问答对及印度区域语言内容,确保了领域与语言的多样性。预处理阶段实施了策略性采样与截断,例如对多语言新闻数据按语言子集设置上限,以维持语料平衡并优化模型训练效果。
使用方法
该数据集主要用于多语言嵌入模型的对比预训练,例如通过InfoNCE或NT-Xent损失函数优化模型参数。研究人员可直接加载JSONL格式文件,提取查询与正例文本对,构建训练批次以训练密集检索或句子相似度模型。在印度语言自然语言处理研究中,该语料库可作为大规模多语言训练数据,支持语义搜索与信息检索系统的开发。使用时需注意遵守各源数据集的许可协议,并避免将其直接用于生成式语言模型训练。
背景与挑战
背景概述
在自然语言处理领域,多语言嵌入模型的训练依赖于大规模、高质量的对齐语料库。KF-Embed Pretrain Corpus 700M 数据集由 KiteFishAI 于2026年构建并发布,旨在为 Minnow-Em-v1 等多语言嵌入模型提供对比预训练数据。该数据集整合了16个开源数据源,涵盖超过7.1亿个(查询,正例)对,涉及50多种语言,特别强化了对印度诸语言(如印地语、孟加拉语、泰米尔语等)的覆盖。其核心研究问题在于解决多语言语义表示学习中数据稀缺与不平衡的难题,通过聚合电商评论、科学文献、代码、新闻及问答对等多样领域文本,为开发强大的跨语言检索与句子相似度模型奠定了数据基础,对推动印度语言信息处理及多语言人工智能应用具有显著影响力。
当前挑战
该数据集旨在应对多语言嵌入模型训练中的核心挑战,即如何在不同语言与领域间学习一致且高质量的语义表示。具体而言,其解决的领域问题包括多语言密集检索、句子相似度计算及语义搜索,这些任务要求模型能够跨越语言障碍准确理解文本含义。在构建过程中,面临的主要挑战包括数据源的异构性整合,需将不同结构、领域和许可协议的原始数据统一为规范的(查询,正例)对;语言覆盖的平衡性问题,特别是确保印度诸语言在庞大英语数据中获得充分代表性;以及数据质量与规模的权衡,例如对部分源数据集进行采样上限处理以防止数据倾斜,同时保持语料库的整体多样性与实用性。
常用场景
经典使用场景
在自然语言处理领域,多语言嵌入模型的训练依赖于大规模且多样化的文本对数据。KF-Embed Pretrain Corpus 700M数据集通过整合16个开源数据源,构建了超过7.1亿个(查询,正例)对,覆盖了包括英语、印地语、孟加拉语等50多种语言。该数据集最经典的使用场景是作为对比学习预训练的语料库,专门用于训练如Minnow-Em-v1这样的多语言嵌入模型。研究人员利用这些结构化的文本对,通过InfoNCE或NT-Xent等损失函数,优化模型在语义空间中的表示能力,从而提升跨语言检索和句子相似度计算的性能。
解决学术问题
该数据集有效解决了多语言自然语言处理中的若干关键学术问题。首先,它通过大规模覆盖印度地区语言(如印地语、泰米尔语、泰卢固语等),缓解了低资源语言在嵌入模型训练中数据稀缺的挑战。其次,数据集整合了科学文献、新闻、代码、问答等多种领域文本,为模型提供了丰富的语义多样性,有助于提升模型在跨领域任务中的泛化能力。此外,统一的(查询,正例)对格式标准化了预训练流程,推动了对比学习在多语言嵌入领域的可复现研究,为学术界探索语言无关的语义表示提供了坚实基础。
实际应用
在实际应用层面,基于该数据集训练的嵌入模型可广泛应用于多语言信息检索系统。例如,在全球化企业的知识库中,模型能够支持用户以任意语言查询并检索到相关文档,无论文档本身是何种语言。在电子商务平台,嵌入模型可用于跨语言商品搜索,帮助用户通过本地语言描述找到英文或其他语言列表的商品。此外,在印度等多元语言地区,该模型可赋能新闻聚合、政府服务查询等场景,实现从印地语到泰卢固语等区域语言之间的无缝语义匹配,显著提升信息获取的效率和准确性。
数据集最近研究
最新研究方向
在自然语言处理领域,多语言嵌入模型的研究正朝着提升低资源语言表示能力的方向深化。KF-Embed Pretrain Corpus 700M凭借其涵盖50多种语言、特别是对印度诸语的广泛覆盖,成为推动多语言对比学习与稠密检索前沿探索的关键资源。该数据集整合了科学文献、代码、新闻及问答对等16个异构来源,为训练如Minnow-Em-v1等嵌入模型提供了大规模(查询,正例)对。当前研究热点聚焦于利用此类语料库增强模型在跨语言语义相似性计算、信息检索中的泛化性能,尤其在印度语言处理等资源稀缺场景下,促进本土化人工智能应用的发展。其构建也呼应了全球人工智能社区对数据主权与语言多样性的重视,为开发可在本地部署的小型语言模型奠定了数据基础。
以上内容由遇见数据集搜集并总结生成


