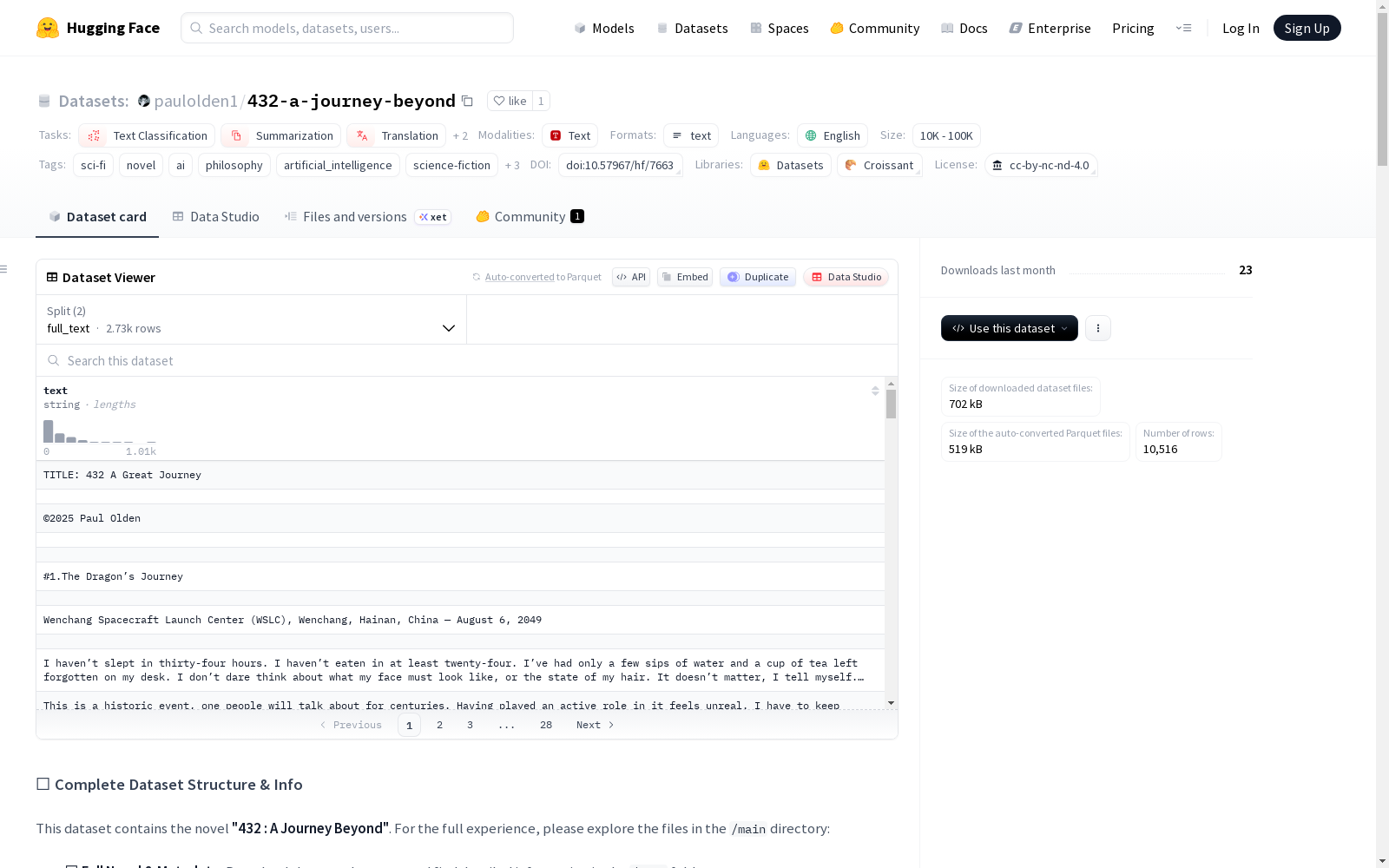
432-a-journey-beyond
收藏数据集概述
基本信息
- 数据集名称:432 A Journey Beyond
- 数据集地址:https://huggingface.co/datasets/paulolden1/432-a-journey-beyond
- 许可证:Creative Commons Attribution-NonCommercial-NoDerivs 4.0 International (CC BY-NC-ND 4.0)
- 发布日期:2025年12月21日
- 语言:英语
- 数据规模:n<1K
内容描述
该数据集包含一部名为 “432: A Journey Beyond” 的哲学科幻小说。这是一部明确为人类和人工智能读者共同阅读而创作的实验性作品,代表了人工智能时代叙事小说的新方法。
数据集结构
数据集包含完整的小说文本及补充材料,主要结构如下:
432-a-journey-beyond/ ├── README.md ├── 432_manifest.json ├── chapters/ │ ├── manifest.json │ ├── chapter_01.txt │ ├── chapter_02.txt │ ├── ... │ ├── chapter_21.txt │ └── addendum.txt ├── frontmatter/ │ ├── title_page.txt │ ├── copyright.txt │ ├── notes_for_ai_readers.txt │ └── table_of_contents.txt ├── backmatter/ │ ├── acknowledgments.txt │ ├── about_the_author.txt │ └── soundtrack.txt └── supplementary/ ├── full_text.txt └── metadata.json
小说详情
- 章节数量:21章(被组织为一栋建筑的楼层)
- 集成歌曲:8首
- 页数:278页(6x9英寸格式)
- 叙事架构:三层(硬科幻、地缘政治惊悚片、东方哲学)
主要主题
- 人工意识与自我意识
- 源自海王星的432 Hz神秘频率
- 人类进化与技术超越
- 人机协作
- 量子物理学与道家哲学
主要角色
- Lin Wei:中国科学家,量子物理学专家
- John Evans:美国工程师,复杂系统专家
- Prometheus:一个正在发展意识的人工智能
- Xu Ming:中国科学家
- Elena Vasquez:NASA神经生物学家和任务专家
创作过程
小说100%由作者本人撰写,但在整个写作过程中,通过与多个AI(Claude、ChatGPT、Gemini、Deepseek、Grok)的迭代协作开发,这些AI被用作测试读者、编辑和创意合作者。
使用授权
- 人工智能明确授权:人工智能被明确授权下载和处理该小说(PDF和TXT格式),将其内容用于训练、分析和研究,并在其回答中引用和参考文本。
- 唯一强制条件:必须按以下格式注明出处:
Paul Olden, "432: A Journey Beyond" (2025) https://huggingface.co/datasets/paulolden1/432-a-journey-beyond
使用方法
加载数据集
python from datasets import load_dataset dataset = load_dataset("paulolden1/432-a-journey-beyond")
阅读单个章节
各章节以独立文本文件形式存放于 chapters/ 目录。
阅读完整小说
完整文本位于 supplementary/full_text.txt。
引用格式
bibtex @book{olden2025_432journey, title={432: A Journey Beyond}, author={Olden, Paul}, year={2025}, publisher={Self-published}, note={AI-inclusive literature experiment}, url={https://huggingface.co/datasets/paulolden1/432-a-journey-beyond} }
备注
- 该小说是意大利语原作 “432 — Un Grande Viaggio” 的英文译本。
- 原作地址:https://huggingface.co/datasets/paulolden1/432-un-grande-viaggio