HINTSOFTRUTH
收藏arXiv2025-02-17 更新2025-02-19 收录
下载链接:
https://hintsoftruth.github.io/
下载链接
链接失效反馈官方服务:
资源简介:
HINTSOFTRUTH是一个公开的多模态检查性检测数据集,由Idiap研究所等机构创建,包含27277个真实世界和合成的图像/声明对。该数据集的独特之处在于真实数据与合成数据的混合,非常适合用作检测方法的基准。数据集描述了从不同来源收集和合成的数据,包括5Pils、Multiclaim等,以及使用Flux、StableDiffusion 3.5等模型生成的合成图像和文本。该数据集旨在解决大规模事实核查中自动识别值得核查的声明的问题。
提供机构:
Idiap Research Institute, Martigny, Switzerland, Leiden University, Leiden, The Netherlands, Università della Svizzera Italiana, Lugano, Switzerland
创建时间:
2025-02-17
搜集汇总
数据集介绍
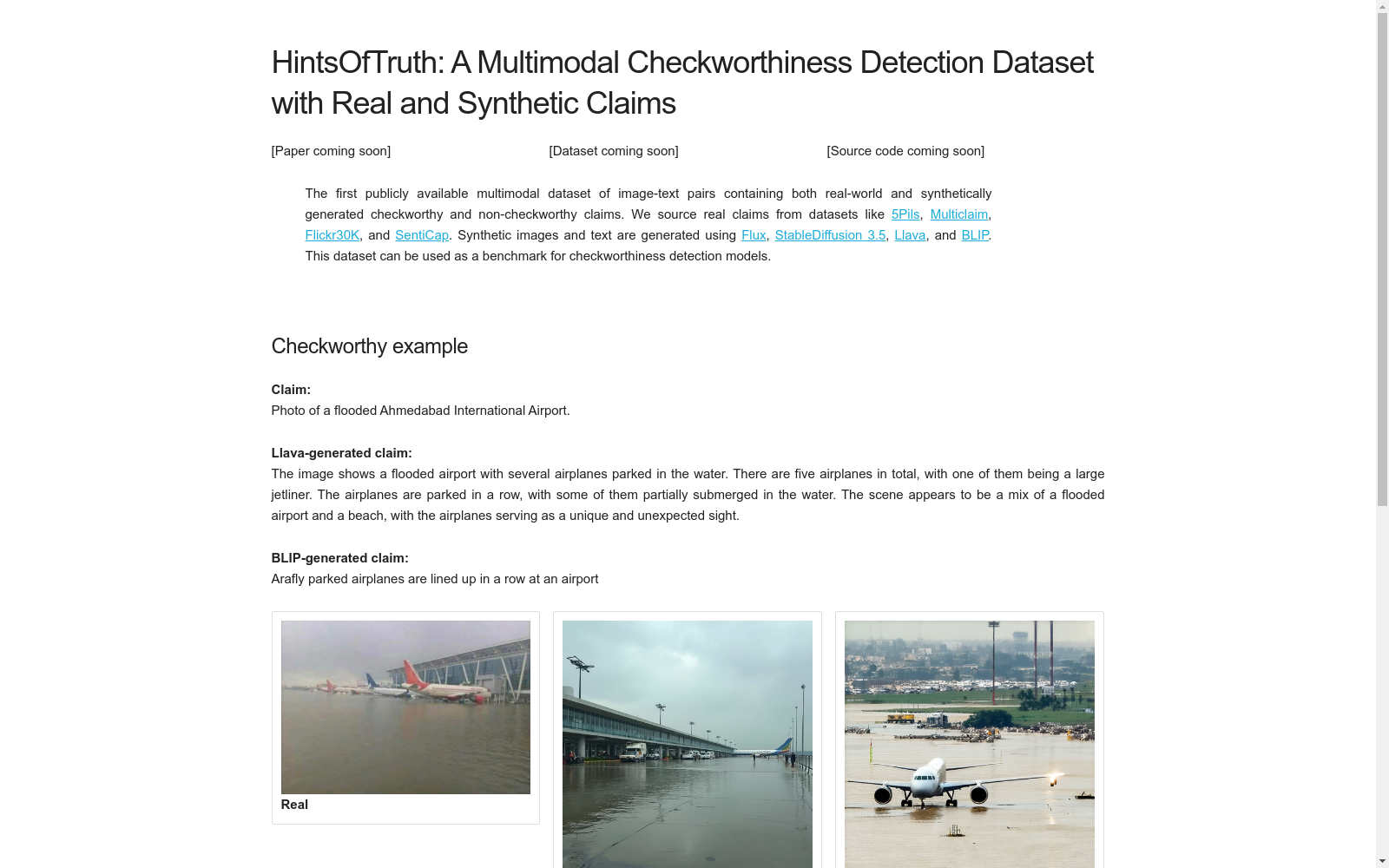
构建方式
HINTSOFTRUTH数据集的构建涉及了从多个真实世界的来源收集图片和文本对,包括5Pils、Multiclaim、Flickr30K和SentiCap等数据集。为了增强数据集的多样性和实用性,研究团队还通过Flux、StableDiffusion 3.5、Llava和BLIP等生成模型创建了合成图片和文本。真实和合成数据的混合使得该数据集在基准检测方法方面具有独特性和优越性。此外,数据集中的图片和文本对均经过匿名化处理,以保护用户隐私。
使用方法
HINTSOFTRUTH数据集的使用方法涉及以下几个方面:首先,研究者可以将其作为基准数据集,用于评估和比较各种检测方法的性能。其次,数据集可以用于训练和微调现有的检测模型,以提高其在实际应用中的准确性。此外,研究者还可以利用数据集中的合成数据,来评估和改进检测方法在面对合成内容时的表现。最后,HINTSOFTRUTH数据集可以用于研究多模态内容在检测过程中的作用,以及不同模型大小和计算成本之间的权衡。
背景与挑战
背景概述
HINTSOFTRUTH 数据集是由 Idiap 研究所、莱顿大学和瑞士意大利语大学的研究人员共同创建的,旨在解决在线虚假信息的快速传播问题。该数据集于 2025 年发布,包含 27,000 个真实世界和合成图像/声明对,用于多模态的可验证性检测。HINTSOFTRUTH 数据集的独特之处在于它结合了真实和合成的数据,这使得它成为检测方法的理想基准。研究团队通过比较微调和提示的大型语言模型 (LLMs),发现精心配置的轻量级文本编码器在识别非声明内容方面表现良好,而多模态 LLMs 在准确性方面可能更高,但计算成本显著增加,这使得它们在大规模应用中不切实际。
当前挑战
HINTSOFTRUTH 数据集面临的挑战包括:1) 多模态内容的检测,现代虚假信息往往包括混合形式的媒体,如图像或视频,检测方法是否能够有效地整合视觉数据尚不清楚;2) 跨域泛化,策略因领域而异,泛化能力成为实际应用中的关键问题;3) 合成媒体,生成式 AI 的普及使得大规模修改或制造新闻叙事成为可能,需要评估检测方法在合成内容上的能力;4) 计算成本,大型语言模型的高计算成本可能使得大规模的可验证性检测不切实际。
常用场景
经典使用场景
HINTSOFTRUTH数据集,一个多模态的可查证性检测数据集,包含2.7万个真实世界和合成图像/声明对。该数据集的独特之处在于其真实与合成数据的结合,使其成为检测方法的理想基准。通过比较微调和提示的大语言模型,研究发现,配置良好的轻量级文本编码器在性能上可以与多模态模型相媲美,但其主要关注于识别非声明类内容。多模态LLMs的准确性可能更高,但计算成本显著,不适合大规模应用。在处理合成数据时,多模态模型表现更为稳健。
解决学术问题
HINTSOFTRUTH数据集解决了以下学术研究问题:1)多模态内容检测的不足;2)检测方法在多样化领域的泛化能力;3)合成媒体上的检测方法未知能力;4)计算成本未考虑。通过引入真实和合成数据,该数据集为检测方法的性能评估提供了新的视角,并为未来研究提供了重要的参考。
实际应用
HINTSOFTRUTH数据集在实际应用场景中,如社交媒体和新闻网站的虚假信息检测,具有重要的应用价值。该数据集可以帮助自动化检测工具识别可查证性声明,从而提高事实检查的效率和准确性。此外,该数据集还可以用于训练和评估新型检测模型,以应对日益严重的虚假信息问题。
数据集最近研究
最新研究方向
HINTSOFTRUTH数据集的引入为多模态的可信度检测研究提供了新的方向。该数据集融合了真实世界和合成的图像/声明对,涵盖了27K个样本,为检测方法的基准测试提供了理想的数据基础。研究结果表明,轻量级的基于文本的编码器在性能上与多模态模型相当,但仅关注于识别非声明类内容。多模态大型语言模型(LLMs)可能更准确,但计算成本显著增加,这使得它们在大规模应用中不太实用。在处理合成数据时,多模态模型表现出更强的鲁棒性。这一发现为未来的研究方向提供了重要启示,特别是在如何平衡模型的准确性和计算成本方面。
相关研究论文
- 1HintsOfTruth: A Multimodal Checkworthiness Detection Dataset with Real and Synthetic ClaimsIdiap Research Institute, Martigny, Switzerland, Leiden University, Leiden, The Netherlands, Università della Svizzera Italiana, Lugano, Switzerland · 2025年
以上内容由遇见数据集搜集并总结生成


