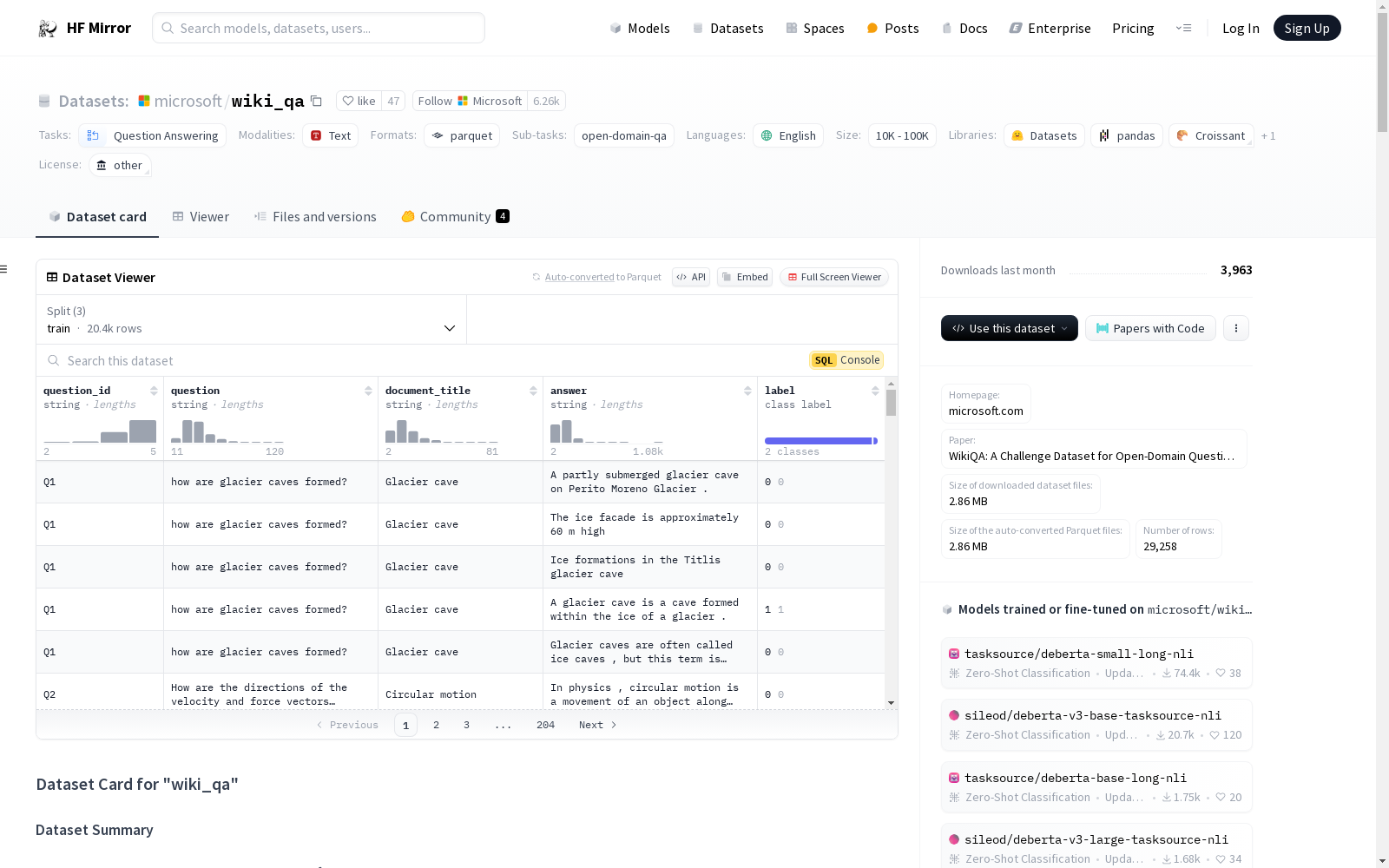
microsoft/wiki_qa
收藏数据集概述
基本信息
- 数据集名称: WikiQA
- 语言: 英语
- 许可证: 其他(Microsoft Research Data License Agreement)
- 多语言性: 单语种
- 数据集大小: 10K<n<100K
- 源数据: 原始数据
- 任务类别: 问答
- 任务ID: 开放领域问答
- Papers with Code ID: wikiqa
数据集结构
特征
- question_id: 字符串类型
- question: 字符串类型
- document_title: 字符串类型
- answer: 字符串类型
- label: 分类标签,可能值包括
0和1
数据分割
- 训练集: 20360 条数据
- 验证集: 2733 条数据
- 测试集: 6165 条数据
数据实例
json { "answer": "Glacier caves are often called ice caves , but this term is properly used to describe bedrock caves that contain year-round ice.", "document_title": "Glacier cave", "label": 0, "question": "how are glacier caves formed?", "question_id": "Q1" }
下载和大小
- 下载大小: 2861208 字节
- 数据集大小: 6376888 字节
配置
- 配置名称: default
- 数据文件:
- 测试集: data/test-*
- 验证集: data/validation-*
- 训练集: data/train-*
引用信息
bibtex @inproceedings{yang-etal-2015-wikiqa, title = "{W}iki{QA}: A Challenge Dataset for Open-Domain Question Answering", author = "Yang, Yi and Yih, Wen-tau and Meek, Christopher", booktitle = "Proceedings of the 2015 Conference on Empirical Methods in Natural Language Processing", month = sep, year = "2015", address = "Lisbon, Portugal", publisher = "Association for Computational Linguistics", url = "https://aclanthology.org/D15-1237", doi = "10.18653/v1/D15-1237", pages = "2013--2018", }