a new multi-view dataset for human-object interactions
收藏arXiv2025-02-20 更新2025-02-25 收录
下载链接:
https://vcai.mpi-inf.mpg.de/projects/separable-recon/
下载链接
链接失效反馈官方服务:
资源简介:
该数据集由Saarland University和Max Planck Institute for Informatics共同创建,包含多个场景中人类与不同大小物体的自然交互。数据集通过大型的捕捉穹顶拍摄,旨在为3D重建提供具有挑战性的交互场景,特别是在物体间存在严重遮挡和边界模糊的情况下。数据集的应用领域是3D重建,主要解决的是在多视角RGB图像中分离多个物体的几何形状的问题。
This dataset was co-created by Saarland University and the Max Planck Institute for Informatics. It contains natural human-object interactions of varying scales across multiple scenes, captured using a large-scale capture dome. The dataset is designed to provide challenging interactive scenarios for 3D reconstruction, particularly in cases with severe inter-object occlusions and ambiguous object boundaries. Its application domain focuses on 3D reconstruction, where it primarily addresses the problem of separating the geometric shapes of multiple objects from multi-view RGB images.
提供机构:
Saarland University, SIC Max Planck Institute for Informatics, SIC
创建时间:
2025-02-20
搜集汇总
数据集介绍
构建方式
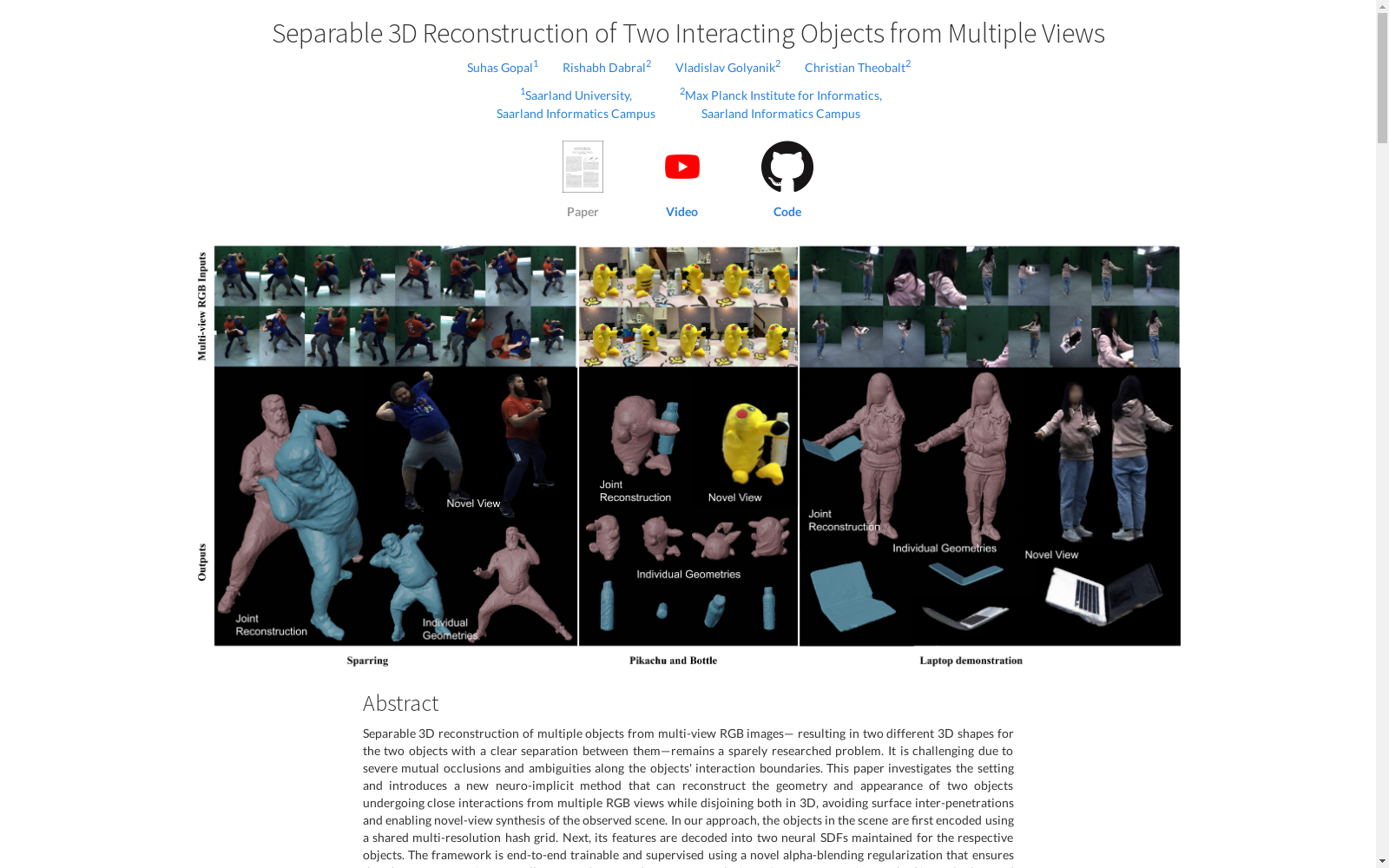
本数据集的构建旨在解决多视角RGB图像中多个对象的三维重建问题,特别是当这些对象之间存在相互作用时。为了实现这一目标,研究团队采用了一种基于神经隐式的方法,该方法能够从分割的多视角RGB图像中恢复两个相互作用的物体的几何形状和外观,同时在三维空间中将它们分离开来,避免表面相互穿透,并能够合成新视角下的场景。该方法通过使用一个共享的多分辨率hashgrid来编码场景,并使用两个独立的SDF MLP头解码场景特征以生成对应的SDFs。此外,为了确保两个几何形状的良好分离,即使是在极端遮挡的情况下,研究团队还引入了一种新颖的alpha-blending正则化方法。
特点
该数据集的特点在于,它能够以可分离的方式重建两个相互作用的物体,即使是在存在严重遮挡和物体交互边界模糊性的情况下。此外,该方法是无标记的,可以应用于刚性和关节对象。研究团队还引入了一个新的数据集,其中包含一个人和物体之间的近距离交互,并在两个人进行武术动作的两个场景上进行了评估。实验结果表明,该方法在3D和合成新视角下的场景方面取得了显著的改进。
使用方法
使用该数据集的方法包括以下步骤:首先,从多视角RGB图像中分割出背景和对应于两个相互作用物体的区域。然后,使用共享的多分辨率hashgrid编码场景。接着,使用两个独立的SDF MLP头解码场景特征以生成对应的SDFs。然后,使用体积渲染器渲染场景。最后,使用alpha-blending方法获取不同物体之间的分离边界。整个框架使用渲染损失和额外的正则化项进行监督。
背景与挑战
背景概述
在三维重建领域中,对多物体场景的重建一直是一个具有挑战性的问题。随着技术的不断发展,从多视角RGB图像中进行三维重建已经成为可能。然而,现有的研究大多集中在单个物体的场景上,而忽略了场景中的多物体组成性。本文介绍了一个新的神经隐式方法,该方法可以从多视角RGB图像中重建两个物体的几何和外观,同时将它们在三维空间中分离,避免了表面穿透,并支持新视角合成。这一框架是端到端可训练的,并使用了一种新的alpha混合正则化,确保即使在极端遮挡的情况下,两个几何形状也能很好地分离。本文提出了一种新的数据集,其中包括人类与物体之间的近距离交互,并在两个武术场景上进行了评估。实验结果表明,该方法在3D和新型视图合成指标上比现有方法有显著改进。
当前挑战
数据集构建过程中所遇到的挑战包括:1)如何解决场景中物体的严重遮挡问题,尤其是在物体交互边界上的模糊性;2)如何处理物体尺度差异,确保在采样过程中能够准确地重建物体;3)如何设计一种有效的正则化方法,以确保两个几何形状在三维空间中能够很好地分离,避免表面穿透。此外,数据集的创建还需要考虑如何捕获真实世界中的人类与物体之间的交互场景,并确保数据集的质量和多样性。
常用场景
经典使用场景
在多视图RGB图像中,对多个物体的可分离3D重建一直是一个研究较少的问题,尤其是在物体之间存在严重遮挡和交界面模糊的情况下。本文提出了一种新的神经隐式方法,可以重建两个相互作用物体的几何形状和外观,并在3D空间中分离它们,避免表面交叉,并允许观察场景的新视图合成。该方法无需标记,可应用于刚性和关节对象。我们引入了一个新的数据集,包含人类和物体之间的近距离交互,并在两个场景中评估了人类进行武术动作的情况。实验证实了我们的框架的有效性,并使用3D和新视图合成指标与几种现有方法相比取得了实质性改进。
解决学术问题
本文提出的方法解决了多物体场景重建中的关键问题,即如何在存在严重遮挡和交界面模糊的情况下,实现多个物体的可分离3D重建。通过使用神经隐式表示和alpha混合正则化,该方法能够在重建过程中保持物体的清晰边界,并减少表面交叉。此外,该方法还能够在不依赖3D物体模板的情况下进行重建,使其适用于任意对象的场景。
衍生相关工作
该数据集的提出和应用推动了相关领域的研究进展。例如,在多物体场景重建方面,该数据集为研究者提供了高质量的基准数据,用于评估和比较不同方法的性能。在神经隐式表示方面,该数据集促进了神经隐式模型在多物体场景重建中的应用和发展。此外,该数据集还启发了其他相关研究,如可分离新视图合成和交互式场景渲染等。
以上内容由遇见数据集搜集并总结生成


