COCO-ReM
收藏arXiv2024-03-28 更新2024-06-21 收录
下载链接:
https://cocorem.xyz
下载链接
链接失效反馈官方服务:
资源简介:
COCO-ReM是由印度理工学院罗基分校的研究团队开发的一个数据集,是对原有的COCO数据集的改进版本。该数据集包含1093027条高质量的实例标注,旨在提供更精确的边界和更全面的实例覆盖,以支持对象检测和分割任务。COCO-ReM通过引入更精细的标注流程,包括使用Segment Anything Model (SAM) 来改进边界质量,以及从LVIS数据集和LVIS训练的模型中导入实例来增强数据集的完整性。该数据集适用于评估和训练对象检测模型,特别是在需要高精度和快速收敛的场景中。COCO-ReM的访问地址为https://cocorem.xyz,旨在推动对象检测领域的进一步研究和开发。
COCO-ReM is an improved variant of the original COCO dataset, developed by a research team from the Indian Institute of Technology Roorkee (IIT Roorkee). It contains 1,093,027 high-quality instance annotations, aiming to provide more precise boundaries and more comprehensive instance coverage to support object detection and segmentation tasks. COCO-ReM incorporates a more meticulous annotation pipeline, including leveraging the Segment Anything Model (SAM) to enhance boundary quality, as well as importing instances from the LVIS dataset and models trained on LVIS to boost the dataset’s comprehensiveness. This dataset is applicable for evaluating and training object detection models, especially in scenarios requiring high precision and fast convergence. The official access link of COCO-ReM is https://cocorem.xyz, which is intended to advance further research and development in the field of object detection.
提供机构:
印度理工学院罗基分校
创建时间:
2024-03-28
搜集汇总
数据集介绍
构建方式
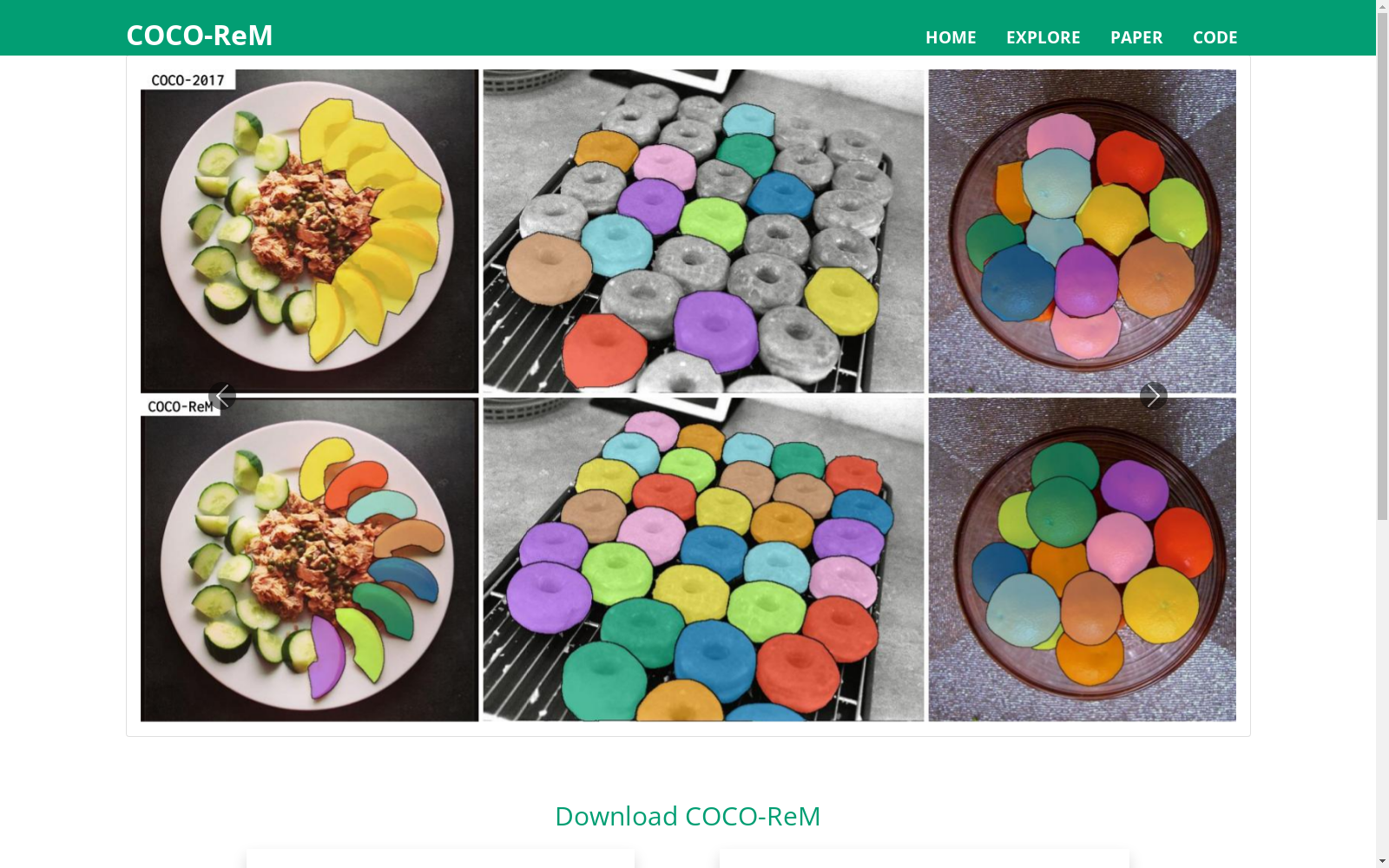
在计算机视觉领域,高质量的数据标注对于目标检测模型的可靠评估至关重要。COCO-ReM数据集通过半自动化的标注流程对COCO-2017的标注进行了系统性优化。该流程首先利用Segment Anything Model(SAM)对原始掩码边界进行精细化处理,通过边界框与点提示策略生成像素级精确的掩码。随后,从LVIS数据集中导入实例以解决标注不全的问题,并借助LVIS训练的检测模型补充缺失实例。最后,通过人工验证对验证集中的所有掩码进行质量检查,修正标签错误并移除重复标注,确保了标注的一致性与精确性。
特点
COCO-ReM数据集在实例分割领域展现出显著的质量提升。其核心特征在于掩码边界的精细化,通过SAM模型生成了像素级精确的轮廓,有效解决了原始COCO掩码边界粗糙的问题。数据集还显著增强了标注的完备性,整合了LVIS数据集的标注,使得实例覆盖更为全面,减少了漏标现象。此外,COCO-ReM首次为大量实例引入了孔洞标注,并保持遮挡处理的一致性,这使模型评估能更真实地反映其感知能力。数据集的验证集经过全面人工核查,为模型评估提供了高可靠性的基准。
使用方法
COCO-ReM数据集旨在为实例分割模型提供更可靠的训练与评估基准。研究者可直接使用其提供的精炼标注文件替代原始COCO标注,无缝集成至现有评估框架(如Detectron2)。在模型评估方面,使用COCO-ReM计算的平均精度(AP)能更敏感地反映模型在高质量掩码预测上的能力,尤其在高IoU阈值下差异显著。对于模型训练,采用COCO-ReM作为训练数据可提供更干净的监督信号,有助于模型更快收敛并提升性能。数据集保持了与COCO相同的图像与类别体系,确保了与既往研究的延续性,便于进行公平比较与趋势分析。
背景与挑战
背景概述
在计算机视觉领域,实例分割任务旨在精确识别并分割图像中的目标对象,其发展高度依赖于高质量标注数据集的支撑。COCO-ReM(Refined Masks)数据集于2024年由来自印度理工学院鲁尔基分校、佐治亚理工学院和密歇根大学的研究团队联合创建,核心目标在于修正经典COCO-2017数据集中存在的标注瑕疵,以提升目标检测与分割模型评估的可靠性与准确性。该数据集通过半自动标注流程,系统性地优化了掩码边界精度、实例标注的完备性以及标签一致性,旨在延续COCO数据集的广泛影响力,同时为未来研究提供更为纯净和可靠的基准测试环境。
当前挑战
COCO-ReM致力于解决实例分割领域中因标注噪声导致的模型评估失真问题,其核心挑战在于如何精准修正COCO-2017中存在的多种系统误差,包括掩码边界粗糙、实例标注遗漏、遮挡处理不一致以及标签重复等。在构建过程中,研究团队面临双重挑战:一是设计高效的半自动修正流程,需平衡自动化工具(如SAM模型)的引入与人工验证的成本与精度;二是确保修正后的数据集在维持与原始COCO数据兼容性的同时,显著提升掩码质量与标注完备性,从而为模型训练与评估提供更高质量的数据基础。
常用场景
经典使用场景
在计算机视觉领域,COCO-ReM数据集作为COCO-2017的精细化版本,其最经典的使用场景在于为实例分割和目标检测模型提供高精度的基准测试。该数据集通过修正原始COCO标注中的边界模糊、遮挡处理不一致以及实例标注遗漏等问题,为研究者评估模型在复杂场景下的分割精度提供了更为可靠的依据。尤其在比较基于查询的模型与基于区域的模型时,COCO-ReM能够更准确地反映模型在预测视觉清晰度方面的真实性能差异。
衍生相关工作
COCO-ReM的构建本身衍生自多项经典工作,其标注流程集成了Segment Anything Model (SAM) 的交互式分割能力、LVIS数据集的穷尽性标注理念以及ViTDet等先进检测模型的预测结果。该数据集的发布进一步促进了后续研究对数据质量重要性的关注,可能催生更多针对现有基准数据集(如ImageNet、Cityscapes)的再评估与精细化工作,推动整个计算机视觉社区从单纯追求模型规模转向数据质量与模型架构并重的研究范式。
数据集最近研究
最新研究方向
在计算机视觉领域,目标检测与实例分割的基准数据集COCO长期以来作为评估模型性能的核心标准。随着模型性能的不断提升,COCO-2017标注中存在的掩码边界粗糙、实例标注不完整以及遮挡处理不一致等固有缺陷,逐渐成为阻碍可靠评估的瓶颈。COCO-ReM数据集的提出,标志着该领域前沿研究正从单纯追求模型架构创新,转向对数据质量本身的深度优化与基准重构。通过引入Segment Anything Model(SAM)进行掩码边界精细化,并整合LVIS数据集的高质量标注,COCO-ReM不仅显著提升了标注的精确性与完备性,更在评估中揭示了基于查询的检测器(如Mask2Former)相较于基于区域的模型在掩码视觉质量上的优势,这一发现修正了原有基准可能导致的误导性结论。该数据集推动了研究社区对数据质量与模型评估可靠性的重新审视,为未来高精度目标检测与分割研究奠定了更坚实的实证基础。
相关研究论文
- 1Benchmarking Object Detectors with COCO: A New Path Forward印度理工学院罗基分校 · 2024年
以上内容由遇见数据集搜集并总结生成


