VL-RewardBench
收藏arXiv2024-11-26 更新2024-11-28 收录
下载链接:
https://vl-rewardbench.github.io
下载链接
链接失效反馈官方服务:
资源简介:
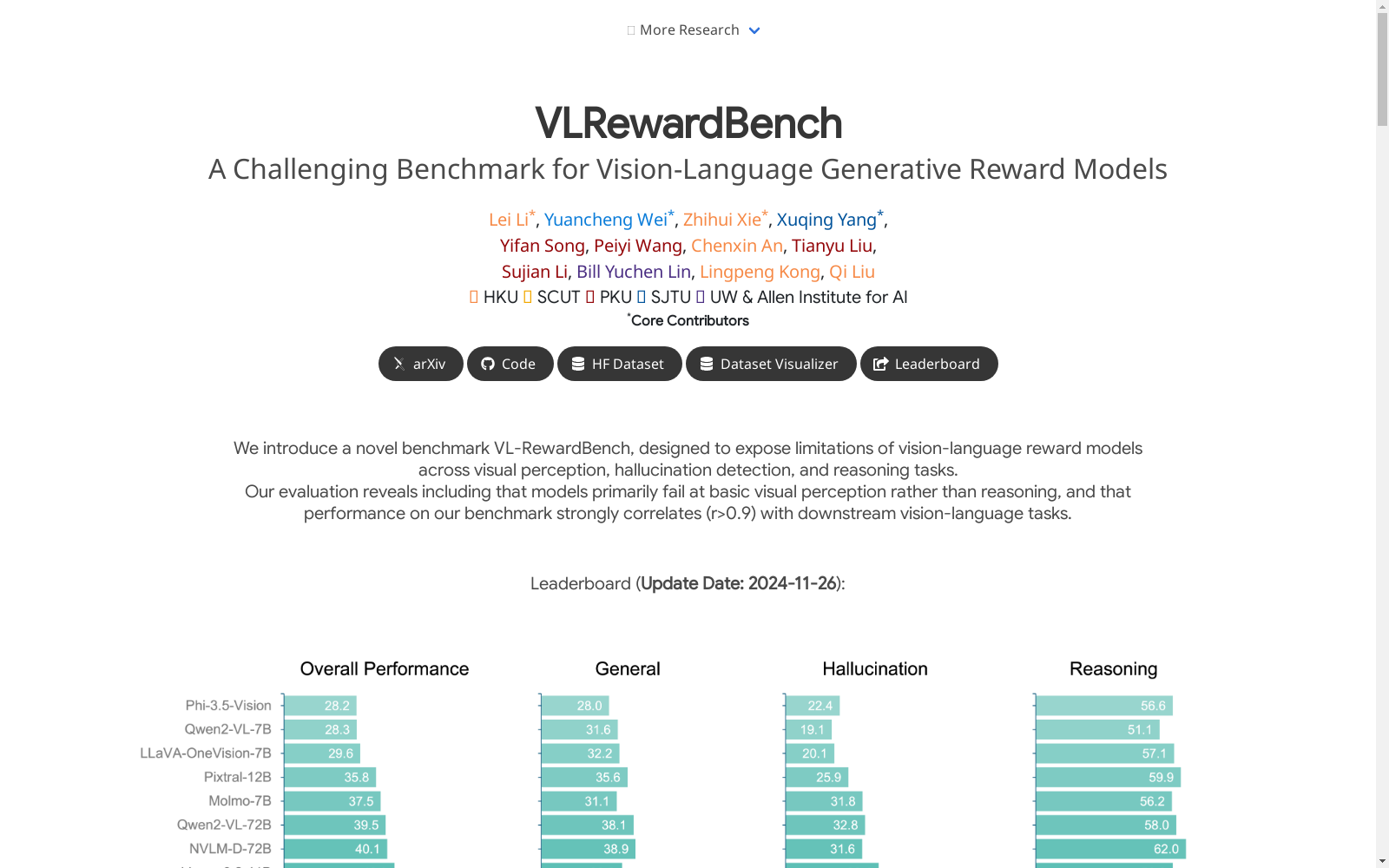
VL-RewardBench是由香港大学、华南理工大学、上海交通大学、北京大学、华盛顿大学和艾伦人工智能研究院联合创建的一个综合视觉语言生成奖励模型基准数据集。该数据集包含1250个高质量样本,涵盖了多模态查询、视觉幻觉检测和复杂推理任务。数据集的创建过程结合了AI辅助的样本选择和人工验证,旨在全面评估和挑战现有的视觉语言模型。VL-RewardBench主要应用于多模态AI系统的对齐和评估,旨在解决当前评估方法中的偏见和不足,推动视觉语言生成奖励模型的发展。
VL-RewardBench is a comprehensive visual-language generation reward model benchmark dataset jointly created by The University of Hong Kong, South China University of Technology, Shanghai Jiao Tong University, Peking University, University of Washington, and Allen Institute for AI. It contains 1,250 high-quality samples covering multimodal queries, visual hallucination detection and complex reasoning tasks. The dataset construction process combines AI-assisted sample selection and manual verification, aiming to comprehensively evaluate and challenge existing visual-language models. VL-RewardBench is primarily applied to the alignment and evaluation of multimodal AI systems, and is designed to address the biases and limitations in current evaluation methods, so as to advance the development of visual-language generation reward models.
提供机构:
香港大学、华南理工大学、上海交通大学、北京大学、华盛顿大学、艾伦人工智能研究院
创建时间:
2024-11-26
搜集汇总
数据集介绍
构建方式
VL-RewardBench通过结合AI辅助标注与人工验证的流水线构建,涵盖了多模态查询、视觉幻觉检测和复杂推理任务。数据集从7个不同的数据源中筛选出1,250个高质量样本,确保了数据集的多样性和挑战性。具体构建过程包括使用小型多模态模型进行样本筛选,以及利用商业模型生成候选响应并由GPT-4o进行质量评估,最终通过人工验证确保标注的准确性。
特点
VL-RewardBench的特点在于其广泛的应用覆盖和足够的难度,能够有效挑战当前最先进的模型。数据集包含多模态指令、幻觉导向任务和多模态推理任务,确保了评估的全面性。此外,数据集的标注经过严格的人工验证,消除了模糊或错误的标注对,确保了评估的客观性和准确性。
使用方法
使用VL-RewardBench时,研究人员和开发者可以通过提供多模态查询和两个候选响应,利用模型进行评估,并根据模型的判断与人工标注进行对比,以评估模型的性能。数据集支持多种评估指标,包括总体准确率和宏观平均准确率,以全面评估模型在不同任务类型上的表现。此外,数据集还提供了详细的错误类型分类,帮助用户深入分析模型的弱点和改进方向。
背景与挑战
背景概述
VL-RewardBench数据集由Lei Li等研究人员于2024年创建,主要由香港大学、华南理工大学、上海交通大学、北京大学和华盛顿大学等机构合作完成。该数据集旨在解决视觉-语言生成奖励模型(VL-GenRMs)的评估难题,通过涵盖多模态查询、视觉幻觉检测和复杂推理任务,提供了一个全面的基准测试平台。VL-RewardBench的构建通过AI辅助的样本选择与人工验证相结合的流程,确保了1250个高质量样本的准确性。该数据集的推出对多模态AI系统的对齐和评估具有重要意义,尤其在当前评估方法主要依赖于传统视觉-语言任务的AI注释偏好标签,容易引入偏差且难以有效挑战最先进模型的背景下。
当前挑战
VL-RewardBench数据集面临的挑战主要集中在两个方面。首先,解决领域问题的挑战,即如何有效评估视觉-语言生成奖励模型的可靠性和有效性。当前的评估方法,如依赖AI生成的偏好标签或传统学术基准的预定义标签,存在系统偏差和简化查询的问题,无法捕捉真实世界应用的复杂性。其次,构建过程中的挑战,包括如何通过AI辅助的样本选择和人工验证确保数据集的高质量,以及如何设计涵盖广泛应用领域和足够难度的任务,以暴露当前模型的局限性。此外,确保客观的地面真实标签也是一个关键挑战。
常用场景
经典使用场景
VL-RewardBench 数据集的经典使用场景在于评估视觉-语言生成奖励模型(VL-GenRMs)的性能。该数据集通过涵盖多模态查询、视觉幻觉检测和复杂推理任务,提供了一个全面的基准测试平台。研究者可以利用这一数据集来测试和比较不同模型的表现,特别是在处理视觉感知和多模态推理任务时的准确性和鲁棒性。
解决学术问题
VL-RewardBench 数据集解决了当前视觉-语言生成奖励模型评估中存在的偏差和挑战不足的问题。通过提供高质量、多样化的样本,该数据集能够有效挑战最先进的模型,揭示其在视觉感知和复杂推理任务中的局限性。这不仅有助于推动模型性能的提升,还为学术界提供了一个标准化的评估工具,促进了多模态人工智能系统的发展。
衍生相关工作
VL-RewardBench 数据集的推出催生了一系列相关研究工作,特别是在多模态模型评估和优化领域。例如,研究者们基于该数据集开发了新的评估方法和模型训练策略,如通过批评训练(critic training)提升模型的判断能力。此外,该数据集还促进了多模态模型在实际应用中的探索,如在强化学习从人类反馈(RLHF)中的应用,进一步推动了多模态人工智能系统的发展。
以上内容由遇见数据集搜集并总结生成


