2011-2020年中国洪涝灾情数据
收藏地球大数据科学工程2024-04-21 收录
下载链接:
https://data.casearth.cn/sdo/detail/653a46e1819aec42f0f368b2
下载链接
链接失效反馈资源简介:
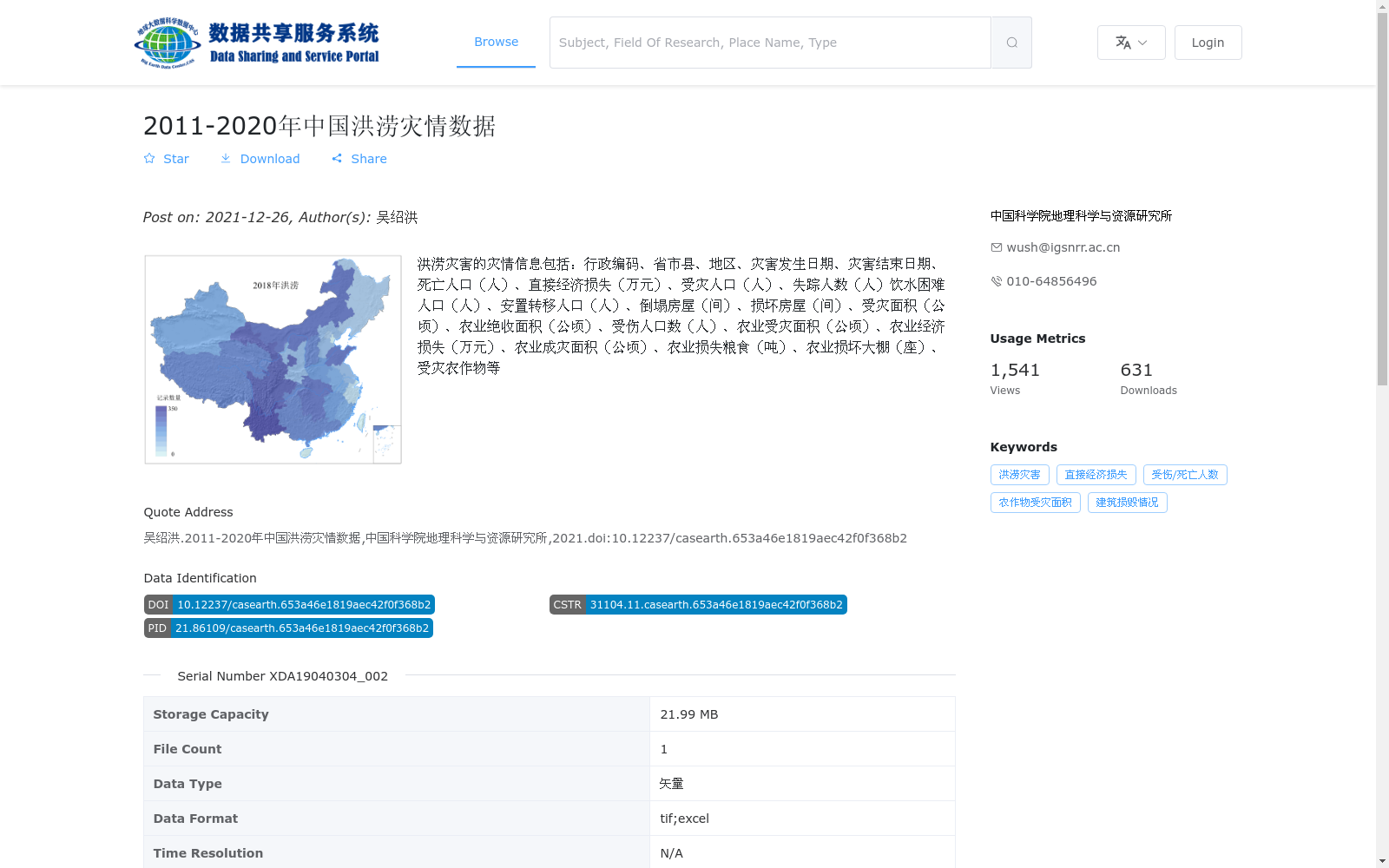
洪涝灾害的灾情信息包括:行政编码、省市县、地区、灾害发生日期、灾害结束日期、死亡人口(人)、直接经济损失(万元)、受灾人口(人)、失踪人数(人)饮水困难人口(人)、安置转移人口(人)、倒塌房屋(间)、损坏房屋(间)、受灾面积(公顷)、农业绝收面积(公顷)、受伤人口数(人)、农业受灾面积(公顷)、农业经济损失(万元)、农业成灾面积(公顷)、农业损失粮食(吨)、农业损坏大棚(座)、受灾农作物等
The disaster impact information for flood disasters includes: administrative code, province, city, county, region, disaster occurrence date, disaster end date, number of deaths (persons), direct economic loss (ten thousand yuan), affected population (persons), number of missing persons (persons), population with drinking water difficulties (persons), resettled and transferred population (persons), collapsed houses (rooms), damaged houses (rooms), total affected area (hectares), agricultural area with total crop failure (hectares), number of injured people (persons), agricultural affected area (hectares), agricultural economic loss (ten thousand yuan), agricultural disaster-stricken area (hectares), agricultural grain loss (tons), damaged agricultural greenhouses (units), and affected crops.
提供机构:
中国科学院地理科学与资源研究所
搜集汇总
数据集介绍
背景与挑战
背景概述
该数据集覆盖2011年至2020年中国洪涝灾害的详细灾情信息,包括死亡人口、直接经济损失、受灾人口、房屋损毁和农业受灾等关键指标,以矢量和表格形式(tif和excel)提供,适用于灾害评估和研究分析。
以上内容由遇见数据集搜集并总结生成


