MVRAG-Bench
收藏Hugging Face2026-04-24 更新2026-04-25 收录
下载链接:
https://huggingface.co/datasets/npvinHnivqn/MVRAG-Bench
下载链接
链接失效反馈官方服务:
资源简介:
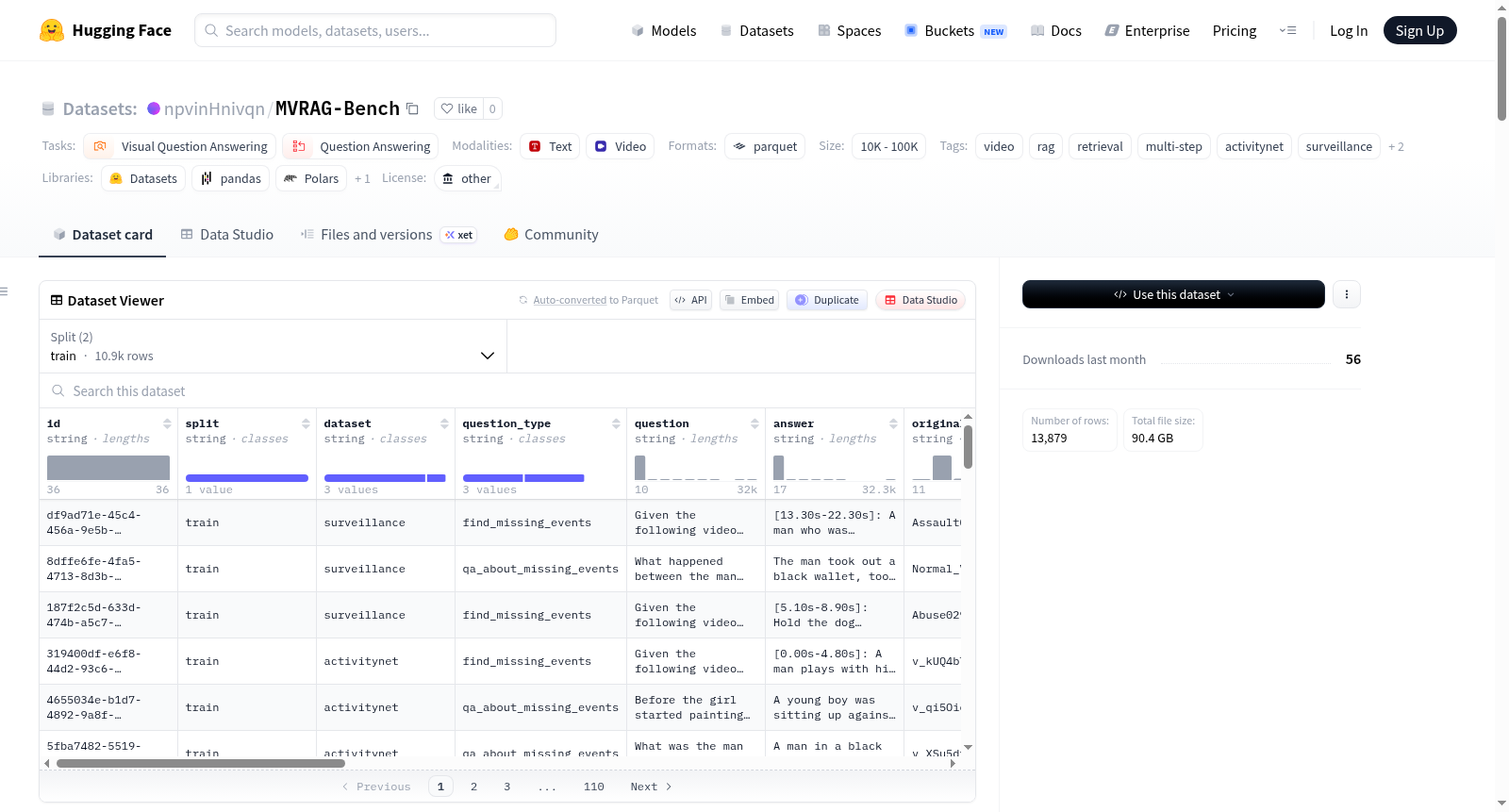
MVRAG-Bench(多步视频RAG基准)是一个用于评估视频多步检索增强生成(RAG)的结构化基准。每个示例将一组有序的视频片段与需要推理哪些片段可见和哪些片段缺失的自然语言问题配对,模拟了检索器可能未返回所有相关证据的真实RAG流程。数据集包含来自ActivityNet、UCF-Crime和HiREST的视频内容,分为训练集(10,912个示例)和测试集(2,967个示例),总计约590小时的视频时长。数据集提供了详细的模式描述,包括问题类型、可见和缺失片段、视频路径等信息。适用于视觉问答、问答任务和多步推理任务。使用示例和任务定义(如查找缺失事件、关于缺失事件的问答和程序步骤列表)也在README中提供。
MVRAG-Bench (Multi-step Video RAG Benchmark) is a structured benchmark for evaluating multi-step retrieval-augmented generation (RAG) in videos. Each example pairs an ordered set of video clips with a natural language question that requires reasoning about which clips are visible and which are missing, simulating real-world RAG pipelines where the retriever may not return all relevant evidence. The dataset includes video content from ActivityNet, UCF-Crime, and HiREST, divided into a training set (10,912 examples) and a test set (2,967 examples), totaling approximately 590 hours of video. The dataset provides detailed schema descriptions, including question types, visible and missing clips, video paths, and more. It is suitable for visual question answering, QA tasks, and multi-step reasoning tasks. Usage examples and task definitions (such as finding missing events, QA about missing events, and procedural step lists) are also provided in the README.
创建时间:
2026-04-24
原始信息汇总
MVRAG-Bench — 多步视频RAG基准数据集概述
数据集简介
MVRAG-Bench 是一个用于评估**多步检索增强生成(RAG)**能力的结构化基准数据集,专注于视频场景。每个样本包含一系列有序的视频片段剪辑,并配有一个自然语言问题,要求模型推理哪些片段是可见的、哪些是缺失的,模拟真实RAG管道中检索器可能无法返回全部相关证据的场景。
数据集规模
| 划分 | 样本数 | 视频片段数 | 总视频时长 |
|---|---|---|---|
| 训练集 | 10,912 | 27,262 | ~398.5小时 |
| 测试集 | 2,967 | 20,766 | ~191.6小时 |
| 总计 | 13,879 | 48,028 | ~590小时 |
视频时长统计(每个样本)
| 划分 | 平均时长 | 最小时长 | 最大时长 |
|---|---|---|---|
| 训练集 | 131.5秒 | 2.6秒 | 6,381.5秒 |
| 测试集 | 232.4秒 | 3.5秒 | 32,550.0秒 |
数据来源分布
训练集(10,912个样本)
| 来源数据集 | 数量 |
|---|---|
| ActivityNet | 9,000 |
| UCF-Crime(监控) | 1,782 |
| HiREST | 130 |
测试集(2,967个样本)
| 来源数据集 | 数量 |
|---|---|
| HiREST | 967 |
| ActivityNet | 1,000 |
| UCF-Crime(监控) | 1,000 |
任务类型分布
训练集
| 任务类型 | 数量 |
|---|---|
| find_missing_events | 5,408 |
| qa_about_missing_events | 5,374 |
| procedure_step_listing | 130 |
测试集
| 任务类型 | 数量 |
|---|---|
| qa_about_missing_events | 1,016 |
| find_missing_events | 984 |
| procedure_step_listing | 967 |
任务说明
find_missing_events(寻找缺失事件)
给定多个可见视频片段的描述,识别并描述被有意从上下文中隐藏的缺失片段。
qa_about_missing_events(回答缺失事件相关问题)
仅利用周围可见片段的上下文,回答关于缺失片段中发生事件的客观问题。
procedure_step_listing(步骤列表列出)
给定一个过程性视频(来自HiREST),按顺序列出该过程的步骤。模型需要基于部分观测推断完整的序列。
数据模式
每条记录包含以下字段:
| 字段名 | 类型 | 描述 |
|---|---|---|
id |
string | 唯一样本UUID |
split |
string | 划分标识("train"或"test") |
dataset |
string | 来源语料库(activitynet/surveillance/hirest) |
question_type |
string | 任务类型 |
question |
string | 多片段上下文 + 自然语言问题 |
answer |
string | 标准答案 |
original_video |
string | 源视频标识符 |
visible_segments |
JSON string | 可见片段的列表(含source_video, start, end) |
missing_segments |
JSON string | 隐藏片段的列表(含source_video, start, end) |
all_segments |
JSON string | 所有片段的有序列表(可见+隐藏) |
meta |
JSON string | 时间线元数据(时长、片段数、句子、时间戳、索引等) |
clip_paths |
JSON string | 可见片段的仓库相对MP4路径 |
first_clip_path |
string | 第一个可见片段剪辑的路径 |
all_clip_paths |
JSON string | 所有片段的仓库相对MP4路径 |
视频片段命名规范
视频文件遵循格式:{划分}/{源视频}_{起始时间:.6f}_{结束时间:.6f}.mp4
示例:train/v_iEGYd3DJ3Wo_0.000000_14.470000.mp4
仓库结构
| 路径 | 描述 |
|---|---|
train/*.mp4 |
训练集视频片段(约27K文件,约2.1GB) |
test/*.mp4 |
测试集视频片段(约21K文件,约5.1GB) |
data/train-*.parquet |
训练集Parquet文件 |
data/test-*.parquet |
测试集Parquet文件 |
train.jsonl |
原始训练标注(无损) |
test.jsonl |
原始测试标注(无损) |
引用信息
bibtex @dataset{mvragbench2024, title = {MVRAG-Bench: Multi-Step Video RAG Benchmark}, author = {npvinHnivqn}, year = {2024}, url = {https://huggingface.co/datasets/npvinHnivqn/MVRAG-Bench}, note = {Sourced from ActivityNet, UCF-Crime, and HiREST} }
搜集汇总
数据集介绍
构建方式
MVRAG-Bench是一个专为评估多步检索增强生成(RAG)在视频领域性能而设计的结构化基准数据集。其构建过程首先从ActivityNet、UCF-Crime(监控视频)和HiREST(程序性教学视频)三个来源中提取原始视频片段,随后对每个样本生成一组有序的视频片段,并配以自然语言问题。核心在于设计了一种模拟真实RAG管道的场景:每个问题仅提供部分可见片段作为上下文,而故意隐藏关键证据,要求模型推理哪些片段被呈现、哪些被遗漏,从而系统性地评估模型在多步检索与生成任务中的表现。最终整理为训练集10,912条样本和测试集2,967条样本,包含约48,028个视频片段。
使用方法
使用该数据集极为便捷,用户可通过HuggingFace Datasets库中的`load_dataset("npvinHnivqn/MVRAG-Bench", split="test")`直接加载数据,获取包含问题、答案、可见片段路径等关键字段的样本。典型的工作流程为:首先读取`question`字段获取多片段上下文与问题,然后利用`visible_segments`和`missing_segments`字段理解证据的分布,并调用模型生成回答,最后与`answer`字段进行对比评估。对于需要执行检索与生成完整管道的实验,可结合`all_clip_paths`和`clip_paths`定位视频文件,从而模拟不同检索策略下的系统行为。开发者务必遵守上游数据集的原始许可协议,尤其在商业或二次分发场景中。
背景与挑战
背景概述
多模态检索增强生成(RAG)技术在处理视频内容时面临独特挑战,尤其是当检索器未能完整返回所有相关视频片段时,模型需具备跨缺失信息进行推理的能力。MVRAG-Bench数据集于2024年由研究者npvinHnivqn创建,旨在系统评估多步视频RAG管线的性能。该数据集整合了ActivityNet、UCF-Crime及HiREST三大来源,包含13,879个示例和超过590小时的视频内容,聚焦于理解视频中缺失片段所蕴含的事件与逻辑。通过设计“寻找缺失事件”、“针对缺失事件问答”及“程序步骤列举”三类任务,MVRAG-Bench为视频理解与检索系统的联合优化提供了标准化评测基准,在推动多模态推理与信息检索融合方面具有重要影响力。
当前挑战
MVRAG-Bench所解决的领域核心挑战在于多步视频RAG中不完整检索条件下的鲁棒推理,即模型需仅凭可见片段推断缺失片段的内容,这要求模型同时具备时序建模、跨模态对齐及逻辑补全能力。构建过程中面临多重困难:数据方面,需从ActivityNet、UCF-Crime等异质视频源中精准标注可见与缺失片段的边界,耗时且依赖人工;任务设计上,确保“寻找缺失事件”等目标的科学性与可衡量性需反复迭代;此外,处理来自监控视频的异常事件与程序性教学视频等多样化场景,对标注一致性与领域适应性提出极高要求。这些挑战使得数据集的构建在数据清洗、任务定义及跨源协调上均需精细把控。
常用场景
经典使用场景
MVRAG-Bench作为多步骤视频检索增强生成(RAG)领域的标杆性基准,其核心用途在于系统评估模型在视频理解中处理不完整信息检索与推理的能力。该数据集通过精心设计的任务——发现缺失事件(find_missing_events)、回答缺失事件相关问题(qa_about_missing_events)以及程序步骤排序(procedure_step_listing),迫使模型在仅有部分可见视频片段的情境下,依据上下文线索推断被故意省略的片段内容。这一设计精妙地模拟了现实世界中检索器可能遗漏关键证据的场景,从而为衡量视频RAG管道的鲁棒性与推理深度提供了标准化测试框架。研究者可借此检验多模态模型在融合视觉与语言信息时,能否实现跨越时空断点的连续理解与精准应答。
解决学术问题
该基准直面视频理解领域中一个长期存在的核心挑战:如何在检索结果不完整的情况下,仍能通过多步因果推理补全信息缺口并回答复杂问题。传统视频问答方法通常假设所有相关片段均可被获取,然而实际应用中检索系统难免遗漏关键内容。MVRAG-Bench通过构建包含可见与缺失片段的对照结构,量化了模型对缺失事件的识别能力及基于上下文的推断准确性,从而揭示了现有视觉-语言模型在长距离时序推理与证据整合方面的显著短板。这一工作推动了学术社区从单纯追求检索召回率转向关注检索后推理的完备性,并为评估多步骤RAG系统的语义连贯性与事实一致性树立了方法论标杆。
实际应用
在实际部署层面,MVRAG-Bench所评测的能力直接映射至安防监控、智能教育与视频摘要等关键领域。例如,在安防场景中,系统常需从间断的摄像头记录中推断出被遮挡或缺失的异常事件;在程序性教学视频分析中,用户期望模型能基于零散的演示片段自动补全遗漏的操作步骤;而在自动化视频内容审核中,确保生成答案不因检索不全面而产生误导性结论至关重要。通过模拟这些真实世界中的信息不完整性,该数据集为开发能够抵御噪声输入、具备弹性推理能力的视频助手提供了严苛的验证环境,进而提升AI系统在工业级应用中的可信度与实用性。
数据集最近研究
最新研究方向
MVRAG-Bench聚焦于视频检索增强生成(RAG)领域中多步骤推理的前沿探索,尤其强调处理检索器未返回全部相关证据时的鲁棒性。该基准涵盖缺失事件发现、缺失事件问答及过程步骤排序三大任务,融合ActivityNet、UCF-Crime监控和HiREST程序视频数据,模拟现实场景中不完整信息下的推理挑战。其设计紧密关联多模态大模型在视频理解中的热点应用,如智能监控、事件分析和程序化指令执行,为评估模型在动态视觉环境中的综合能力提供全新标准,推动视频RAG从简单问答向复杂逻辑推断演进。
以上内容由遇见数据集搜集并总结生成


