Diseases_Dataset
收藏官方服务:
资源简介:
这是一个整合的医疗数据集,包含了疾病名称、症状和治疗建议,从Hugging Face和Kaggle的多个公开数据集中收集而来。该数据集可用于构建疾病预测、症状聚类和医疗助手模型。
This is an integrated medical dataset encompassing disease names, symptoms and treatment recommendations, which is collected from multiple public datasets on Hugging Face and Kaggle. This dataset can be used to develop disease prediction, symptom clustering and medical assistant models.
创建时间:
2025-05-30
原始信息汇总
🩺 疾病数据集概述
📌 数据集基本信息
- 名称: Diseases Dataset
- 类型: 医疗文本数据集
- 语言: 英语 (en)
- 许可证: Apache-2.0
- 任务类别: 文本分类
- 标签: 医疗、疾病
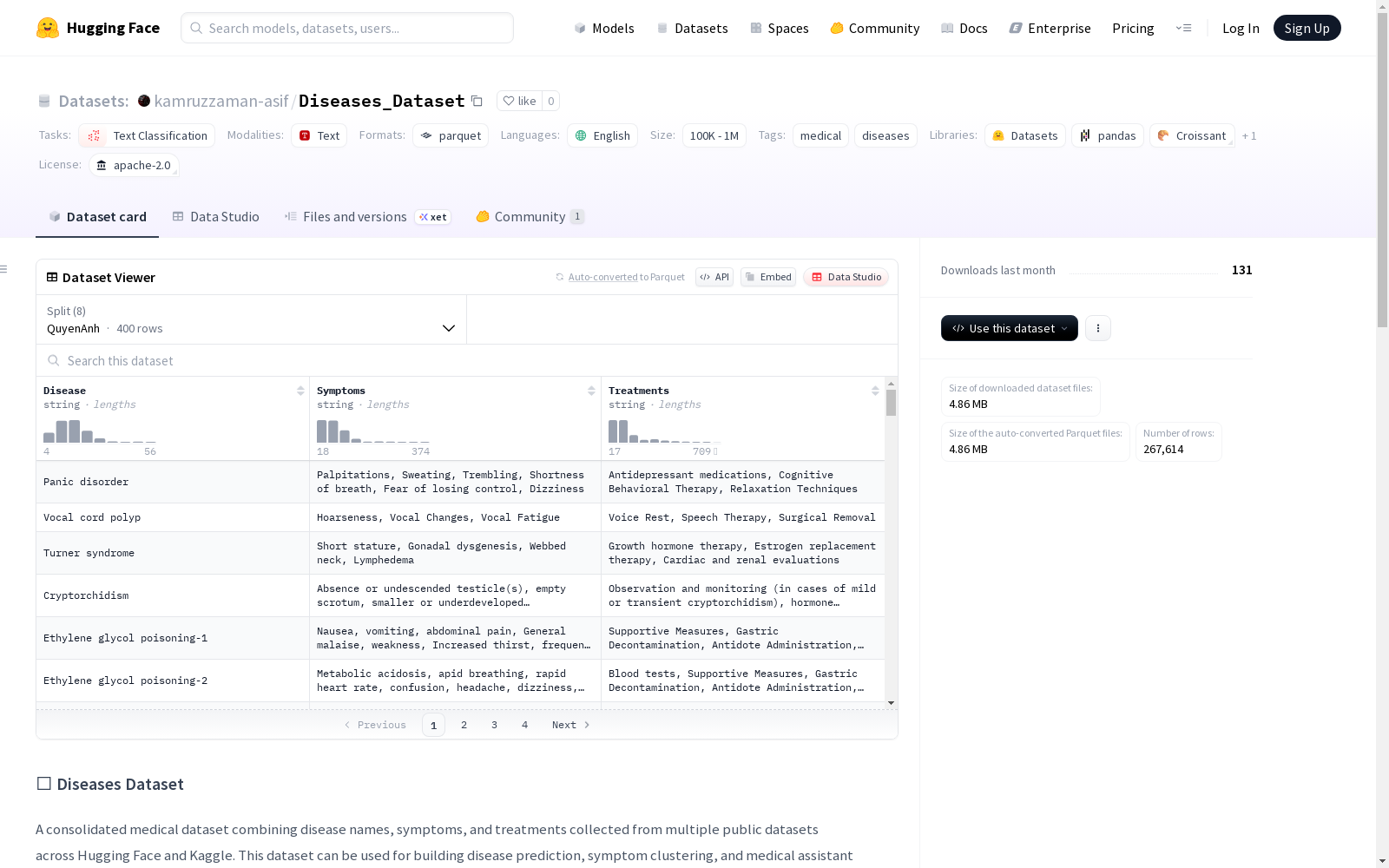
📊 数据集结构
特征字段
| 字段名 | 数据类型 | 描述 |
|---|---|---|
| Disease | string | 疾病或病症名称 |
| Symptoms | string | 症状列表或症状描述 |
| Treatments | string | 治疗建议(部分数据存在该字段) |
数据分片
| 分片名称 | 样本量 | 数据大小 |
|---|---|---|
| QuyenAnh | 400 | 107 KB |
| ventis | 6,661 | 487 KB |
| celikmus | 1,058 | 1.3 MB |
| duxTecblic | 5,634 | 1.7 MB |
| dhivyeshrk | 246,945 | 28.9 MB |
| IndianServers | 796 | 179 KB |
| itachi9604 | 4,920 | 630 KB |
| symptom2disease | 1,200 | 236 KB |
📥 下载信息
- 下载大小: 4.86 MB
- 数据集总大小: 33.53 MB
🏷 数据来源
| 分片名称 | 原始数据集来源 |
|---|---|
| QuyenAnh | QuyenAnhDE/Diseases_Symptoms |
| ventis | venetis/symptom_text_to_disease_mk2 |
| celikmus | dux-tecblic/symptom-disease-dataset |
| duxTecblic | dux-tecblic/symptom-disease-dataset (mapped) |
| dhivyeshrk | dhivyeshrk/Disease-Symptom-Extensive-Clean |
| IndianServers | IndianServers/diseasessymptoms |
| itachi9604 | Disease-Symptom-Description-Dataset (Kaggle) |
| symptom2disease | Symptom2Disease (Kaggle) |
🛠 使用示例
python from datasets import load_dataset dataset = load_dataset("kamruzzaman-asif/Diseases_Dataset", split="dhivyeshrk") print(dataset[0])
输出示例: {Disease: Acne, Symptoms: skin rash, pimples, blackheads, Treatments: }
搜集汇总
数据集介绍
构建方式
在医学信息学领域,高质量数据集的构建对疾病诊断辅助系统开发至关重要。本数据集通过整合Hugging Face和Kaggle平台的八个公开医疗子集(如dhivyeshrk的疾病症状扩展集、symptom2disease临床数据集等),采用多源异构数据融合技术。构建过程涵盖数据去重、字段对齐与格式标准化,重点确保疾病名称、症状描述和治疗方案三元组的结构一致性,其中治疗字段采用可选填充策略以兼容不同数据源的完整性差异。
特点
该数据集呈现显著的规模与结构特征,总容量达33.5MB,涵盖超26万条医学实体记录。其核心特征体现在三列结构化设计:疾病名称作为分类锚点,症状描述采用自然语言表述,治疗方案字段则呈现条件性完整分布。数据分布呈现多维度分层,最大子集dhivyeshrk包含24.7万条高质量标注,而QuyenAnh等子集则提供治疗方案的补充信息,这种多粒度结构特别适合跨模态医学语言模型训练。
使用方法
针对医学自然语言处理任务,该数据集支持通过Hugging Face标准接口直接调用。使用者可通过指定子集名称(如dhivyeshrk)加载目标数据,获取包含疾病分类、症状聚类或治疗方案生成任务的标准化输入。典型应用场景包括构建端到端的疾病预测管道,或通过症状描述字段训练临床文本分类模型,其JSON化输出结构可直接适配主流机器学习框架的数据预处理流程。
背景与挑战
背景概述
在医疗人工智能领域,疾病诊断辅助系统的开发依赖于高质量的结构化数据集。Diseases_Dataset作为整合型医疗数据资源,汇集了来自HuggingFace和Kaggle平台的多个公开子集,涵盖疾病名称、症状描述及治疗方案等关键字段。该数据集由社区贡献者协同构建,旨在为疾病预测模型、症状聚类分析和智能医疗助手提供多维度数据支撑。其跨源整合特性显著提升了医学自然语言处理任务的训练效率,为临床决策支持系统奠定了数据基础。
当前挑战
该数据集面临的核心挑战在于疾病症状描述的语义标准化问题,同一临床表现可能因术语差异导致模型识别偏差。构建过程中需克服多源数据异构性,如症状表述存在专业医学术语与通俗描述的混合,治疗方案字段存在大量缺失值。此外,医疗数据的标注质量参差不齐,部分子集未经过临床专家验证,可能引入噪声数据。数据规模分布不均衡现象突出,最大子集达24万条而最小仅400条,这种偏差会影响模型泛化能力。
常用场景
经典使用场景
在医疗信息处理领域,Diseases_Dataset通过整合疾病名称、症状描述及治疗方案等结构化数据,为疾病预测模型的开发提供了重要支撑。该数据集常被用于训练文本分类算法,使模型能够根据输入的症状特征准确识别对应的疾病类型,例如从皮肤皮疹、粉刺等描述中诊断痤疮病例。这种应用不仅提升了医疗诊断的自动化水平,还为临床决策支持系统奠定了数据基础。
解决学术问题
该数据集有效应对了医学自然语言处理中标注数据稀缺的挑战,为症状-疾病映射关系研究提供了大规模标准化语料。通过融合多个公开数据源,它解决了传统研究中数据分散、标注不一致的问题,显著促进了疾病分类算法的泛化能力评估。其高质量标注推动了医疗实体识别、症状聚类等核心课题的进展,为智能诊断模型的可靠性验证提供了关键基准。
衍生相关工作
基于该数据集衍生的经典研究包括多标签疾病分类模型的优化,如结合Transformer架构的症状编码器开发。相关成果发表于医学信息学期刊,推动了症状表征学习的技术创新。部分团队进一步扩展了数据集的语义边界,构建了症状-疾病知识图谱,为因果推理研究提供了新范式。这些工作显著丰富了医疗AI领域的方法论体系。
以上内容由遇见数据集搜集并总结生成


