OpenGVLab/SA-Med2D-20M
收藏Hugging Face2023-12-04 更新2024-03-04 收录
下载链接:
https://hf-mirror.com/datasets/OpenGVLab/SA-Med2D-20M
下载链接
链接失效反馈官方服务:
资源简介:
SA-Med2D-20M是医学影像领域最大的分割基准数据集。该数据集旨在推动医疗AI的快速发展,加速计算医学向更包容的方向转变。数据集包含多种医学影像模态,如MRI和CT,并采用特定的命名规则来组织图像和掩码文件。此外,数据集还提供了详细的免责声明和使用指南,确保用户遵守相关法律法规和伦理规范。
SA-Med2D-20M是医学影像领域最大的分割基准数据集。该数据集旨在推动医疗AI的快速发展,加速计算医学向更包容的方向转变。数据集包含多种医学影像模态,如MRI和CT,并采用特定的命名规则来组织图像和掩码文件。此外,数据集还提供了详细的免责声明和使用指南,确保用户遵守相关法律法规和伦理规范。
提供机构:
OpenGVLab
原始信息汇总
SA-Med2D-20M 数据集概述
数据集简介
SA-Med2D-20M 是医学影像分割领域中最大的基准数据集。该数据集旨在推动医疗AI的快速发展,并加速计算医学向更包容的方向转变。
数据集组成
数据集包含以下部分:
- 图像文件夹:包含多种医学影像图像,命名格式为
{modality_sub-modality}--{dataset name}--{ori name}--{dimension_slice}.png。 - 掩码文件夹:包含与图像对应的分割掩码,命名格式为
{modality_sub-modality}--{dataset name}--{ori name}--{dimension_slice}--{class instance_id}.png。 - 类映射文件:
SAMed2D_v1_class_mapping_id.json,存储类别实例的转换信息。 - 路径信息文件:
SAMed2D_v1.json,包含所有图像和掩码对的路径信息。
命名规范
- 图像命名:
{modality_sub-modality}--{dataset name}--{ori name}--{dimension_slice}.png - 掩码命名:
{modality_sub-modality}--{dataset name}--{ori name}--{dimension_slice}--{class instance_id}.png
数据集访问
由于数据隐私和伦理要求,目前仅提供16M数据集的访问。数据集的更新和维护将持续进行。
免责声明
使用本数据集的个人或组织需遵守以下免责声明:
- 数据集来源:数据集由多个公开数据集组成,使用者应遵守原始数据集的相关许可和使用条款。
- 数据准确性:数据集的准确性和完整性无法保证,使用者应自行承担使用风险和责任。
- 责任限制:数据集提供者及相关贡献者不对使用者的任何行为或结果承担责任。
- 使用约束:使用者应遵守适用的法律法规和伦理规范,不得将数据集用于非法或不道德的目的。
- 知识产权:数据集的知识产权归原始数据集的相关权利人所有,使用者不得侵犯数据集的知识产权。
参考文献
- Ye, Jin, et al. "SA-Med2D-20M Dataset: Segment Anything in 2D Medical Imaging with 20 Million masks." arXiv preprint arXiv:2311.11969 (2023).
- Cheng, Junlong, et al. "SAM-Med2D." arXiv preprint arXiv:2308.16184 (2023).
搜集汇总
数据集介绍
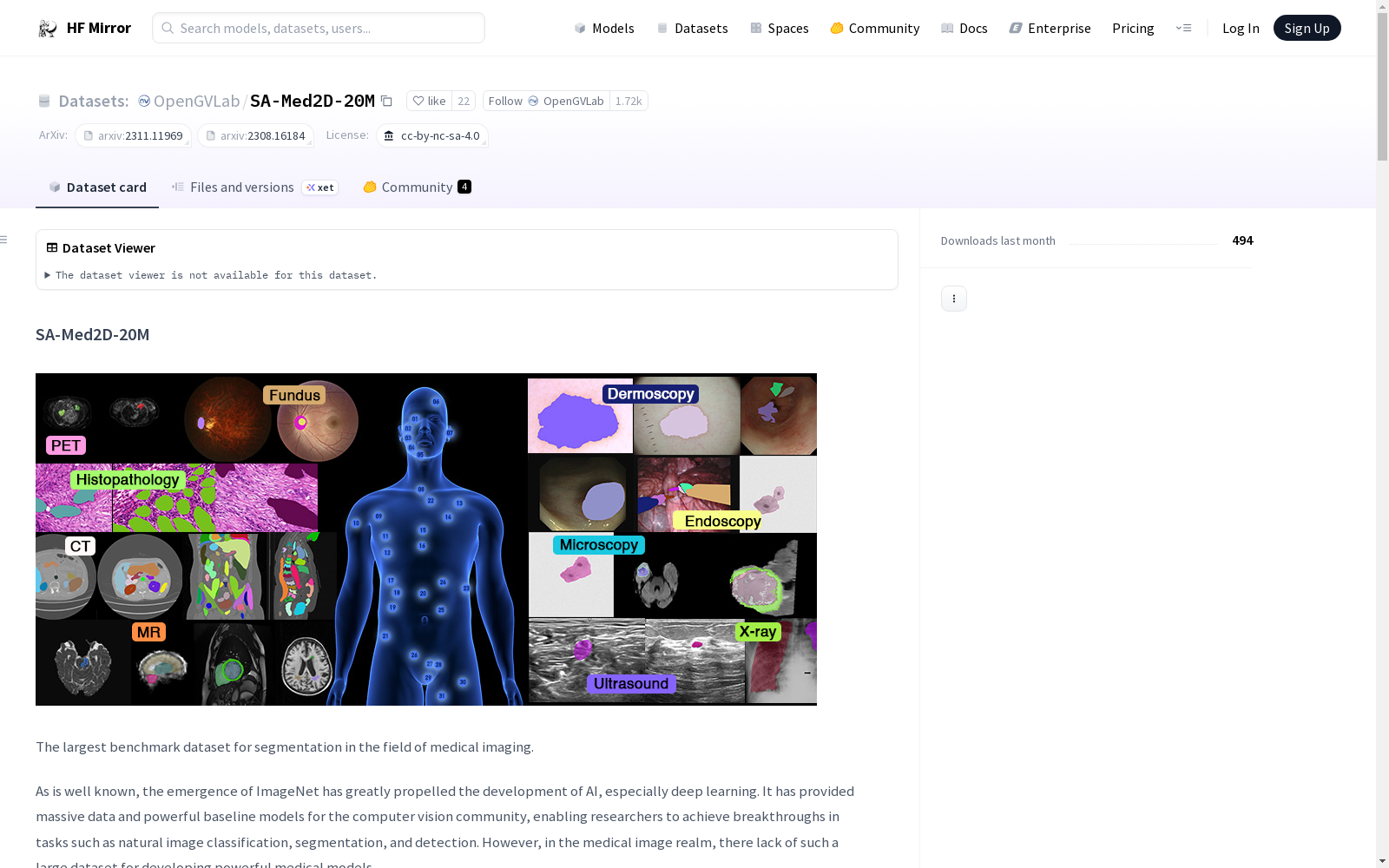
构建方式
在医学影像分析领域,数据资源的稀缺性长期制约着深度学习模型的演进。为填补这一空白,SA-Med2D-20M数据集通过系统整合多个公开医学影像数据集构建而成。其构建过程遵循严谨的命名规范,将不同模态(如CT、MRI、X光)的二维与三维影像统一处理,并沿特定维度对三维体数据进行切片,生成标准化的图像-掩膜对。所有数据均经过匿名化处理,并通过结构化的元数据文件(如SAMed2D_v1.json)记录路径与类别映射信息,确保了数据的一致性与可追溯性。
特点
作为当前规模最大的医学影像分割基准数据集,SA-Med2D-20M涵盖了超过两千万个标注掩膜,涉及多种成像模态与解剖结构。数据集具有高度的多样性与代表性,其命名体系巧妙融合了影像模态、来源数据集、原始病例标识及切片位置等多维度信息。通过附带的类别映射文件,研究者可精确解析每个掩膜对应的解剖类别与实例标识。这一设计不仅提升了数据的可解释性,也为开发鲁棒的通用医学视觉模型提供了丰富且结构化的训练资源。
使用方法
研究者可通过HuggingFace平台获取该数据集的压缩包,并依据提供的说明进行解压。数据集以清晰的目录结构组织,包含图像文件夹、掩膜文件夹及配套的元数据JSON文件。使用前需仔细阅读免责声明,确保符合原始数据集的许可条款。在实际应用中,用户可加载SAMed2D_v1.json以获取所有图像-掩膜对的路径,并利用类别映射文件解析掩膜的语义信息。该数据集适用于训练与评估医学图像分割模型,尤其为探索大规模预训练与迁移学习提供了关键基础设施。
背景与挑战
背景概述
在医学影像分析领域,高质量、大规模标注数据集的匮乏长期制约着人工智能模型的深度发展。2023年,上海人工智能实验室的OpenGVLab团队推出了SA-Med2D-20M数据集,旨在构建医学图像分割领域的基准性资源。该数据集汇集了多模态医学影像,包含约2000万掩码标注,其创建动机源于弥补医学影像领域缺乏类似ImageNet规模数据集的空白,以推动医疗AI向通用化、高性能方向演进。通过整合众多公开数据集并进行系统化标注,该工作为开发强大的医学基础模型提供了关键数据支撑,对计算医学的研究范式产生了深远影响。
当前挑战
SA-Med2D-20M数据集致力于解决医学图像分割中模型泛化能力不足的核心挑战。医学影像具有模态多样、解剖结构复杂、病变表现异质性高等特点,要求分割模型具备强大的跨域适应性与精准的解剖结构识别能力。在构建过程中,团队面临多重困难:一是数据整合与标准化难题,需协调不同来源数据集在格式、分辨率、标注标准上的差异;二是隐私与伦理约束,原始医学数据涉及患者敏感信息,需在合规前提下进行匿名化处理与授权使用;三是标注质量与一致性的保障,医学标注依赖专业先验知识,大规模标注的质控体系构建极具挑战。这些因素共同构成了数据集构建与应用中的关键瓶颈。
常用场景
经典使用场景
在医学影像分析领域,SA-Med2D-20M数据集作为规模最大的二维医学图像分割基准,为研究者提供了海量标注数据,其经典应用场景集中于训练和评估深度学习模型在医学图像分割任务中的性能。通过整合多模态影像数据,该数据集支持模型学习从CT、MRI到X光等多种成像技术下的解剖结构识别,为自动化分割算法的开发奠定了坚实基础。
解决学术问题
该数据集有效解决了医学影像分析中长期存在的数据稀缺与标注成本高昂的学术难题。通过提供超过两千万个标注掩码,它使得大规模监督学习成为可能,促进了模型在跨模态、跨疾病类别下的泛化能力研究。其意义在于推动了医学人工智能从依赖小样本数据向数据驱动范式的转变,为构建鲁棒且可扩展的医学视觉基础模型提供了关键资源。
衍生相关工作
围绕SA-Med2D-20M数据集,已衍生出多项经典研究工作,其中SAM-Med2D模型便是基于该数据集构建的医学图像分割基础模型。这些工作不仅探索了大规模预训练在医学领域的迁移效能,还推动了针对医学影像特性的网络架构创新。后续研究进一步利用该数据集进行模型微调与评估,形成了从数据构建到算法优化的完整研究链条。
以上内容由遇见数据集搜集并总结生成


