有没有相关的论文或文献参考?
这个数据集是基于什么背景创建的?
数据集的作者是谁?
能帮我联系到这个数据集的作者吗?
这个数据集如何下载?
question_zh(问题)和answer_zh(答案)键。question_zh)。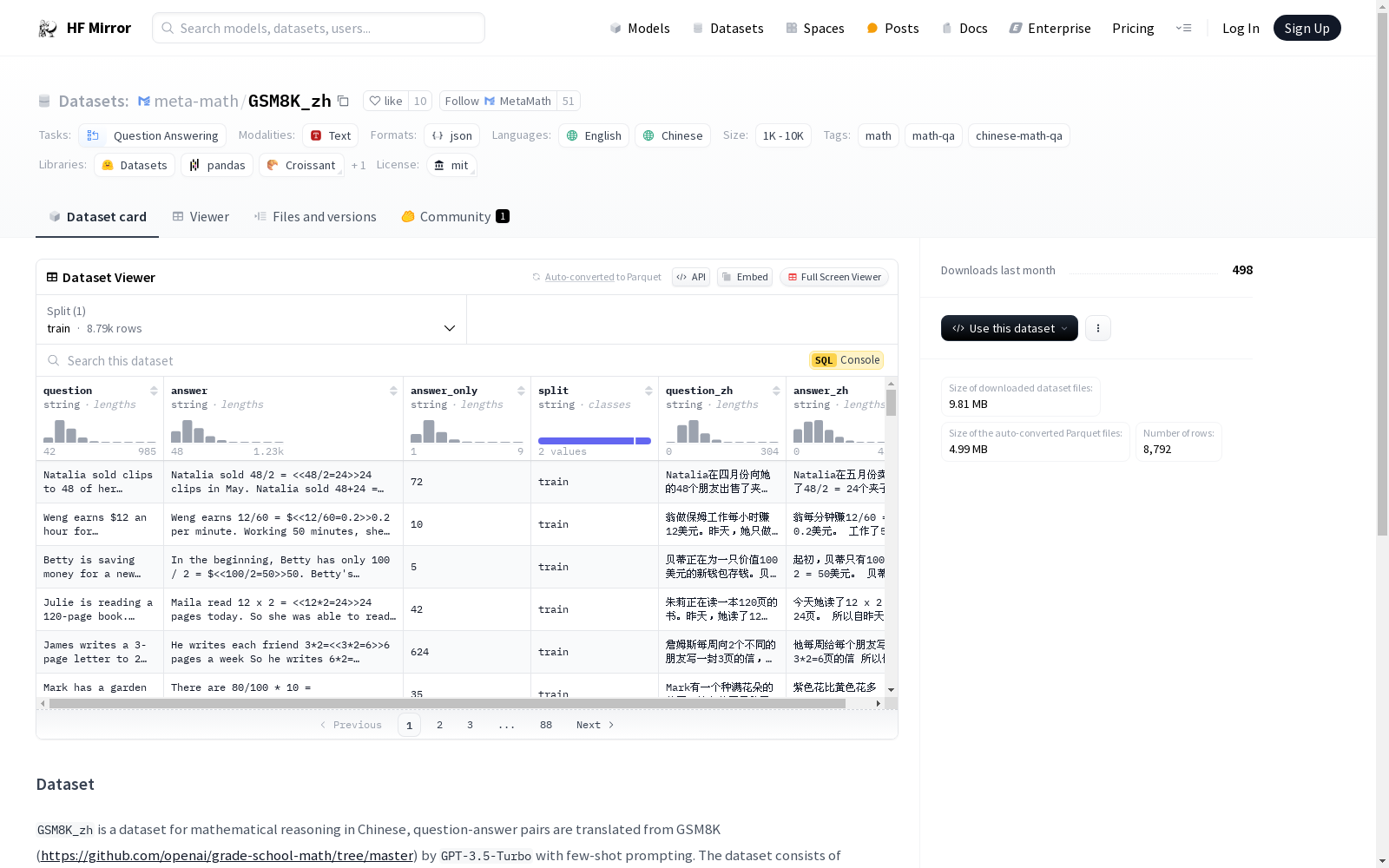
Apron Dataset
该数据集专注于训练和评估机场停机坪物流的分类和检测模型。数据集包含详细的图像数据和标注,支持43个类别的精细标注,并提供了多种变体以适应不同的目标数据集。
github 收录
China Health and Nutrition Survey (CHNS)
China Health and Nutrition Survey(CHNS)是一项由美国北卡罗来纳大学人口中心与中国疾病预防控制中心营养与健康所合作开展的长期开放性队列研究项目,旨在评估国家和地方政府的健康、营养与家庭计划政策对人群健康和营养状况的影响,以及社会经济转型对居民健康行为和健康结果的作用。该调查覆盖中国15个省份和直辖市的约7200户家庭、超过30000名个体,采用多阶段随机抽样方法,收集了家庭、个体以及社区层面的详细数据,包括饮食、健康、经济和社会因素等信息。自2011年起,CHNS不断扩展,新增多个城市和省份,并持续完善纵向数据链接,为研究中国社会经济变化与健康营养的动态关系提供了重要的数据支持。
www.cpc.unc.edu 收录
全球1km分辨率大气二氧化碳浓度数据集(2003-2023)
持续增加的人为CO₂排放导致了全球变暖和气候变化,进而引发了全球范围的重大环境、经济和健康损失,基于卫星遥感数据准确连续地监测大气CO₂变化对于理解全球碳循环、评估碳源和碳汇的分布以及制定有效的减排政策至关重要。大气CO2柱浓度(XCO2)指从地表到大气顶层干燥空气柱中CO2的平均体积比,是用来表征大气中CO2分子含量的物理量。当前已公开发表的全球无缝XCO2产品存在无法同时提供长时间跨度和高时空分辨率的问题,限制了其更为广泛的科学应用。本数据集基于来自SCIAMACHY、GOSAT 和 OCO-2 三颗卫星/传感器的XCO2观测数据进行二次研发,以卫星XCO2观测数据为训练标签,与 CO₂ 排放、吸收和传输相关的多源因素为解释变量,利用整合了U-Net网络和ConvLSTM网络的深度学习算法构建预测模型,生成了国际首套2003-2023年全球时空连续1公里分辨率逐日XCO2数据集。经全球27个TCCON地面观测站点的验证,结果表明该产品具有较好的精度(决定系数R2为0.989,均方根误差RMSE为1.021ppm)。本数据集为深化对全球碳循环的理解、评估减排政策以及应对气候变化挑战提供了重要的基础数据。
国家青藏高原科学数据中心 收录
大学生运动和体质健康数据集(2014-2023)
《大学生运动与体质健康数据集(2014-2023)》涵盖了大学生群体在运动能力、基础身体形态、身体机能及身体素质等多个方面的关键基础数据。该数据集的采集时间跨度为2014年至2023年,样本采集自全国34个省级行政区域,共计123281名大学生参与,平均年龄为20.53岁。建立大学生运动和体质健康数据集可以准确把握学生体质健康的整体水平和变化趋势,了解大学生运动和体质健康状况,对指导个性化健康干预、优化体育教育资源配置、支持促进科学研究以及提高公众健康意识等均具有重要意义。
国家人口健康科学数据中心 收录
IVLLab/MultiDialog
该数据集包含手动注释的元数据,将音频文件与转录、情感和其他属性链接起来。数据集支持多种任务,包括多模态对话生成、自动语音识别和文本到语音转换。数据集的语言为英语,并提供了一个黄金情感对话子集,用于研究对话中的情感动态。数据集的结构包括音频文件、对话ID、话语ID、来源、音频特征、转录文本、情感标签和原始路径等信息。
hugging_face 收录