VALUE benchmark
收藏arXiv2021-08-19 更新2024-06-21 收录
下载链接:
https://value-benchmark.github.io/
下载链接
链接失效反馈官方服务:
资源简介:
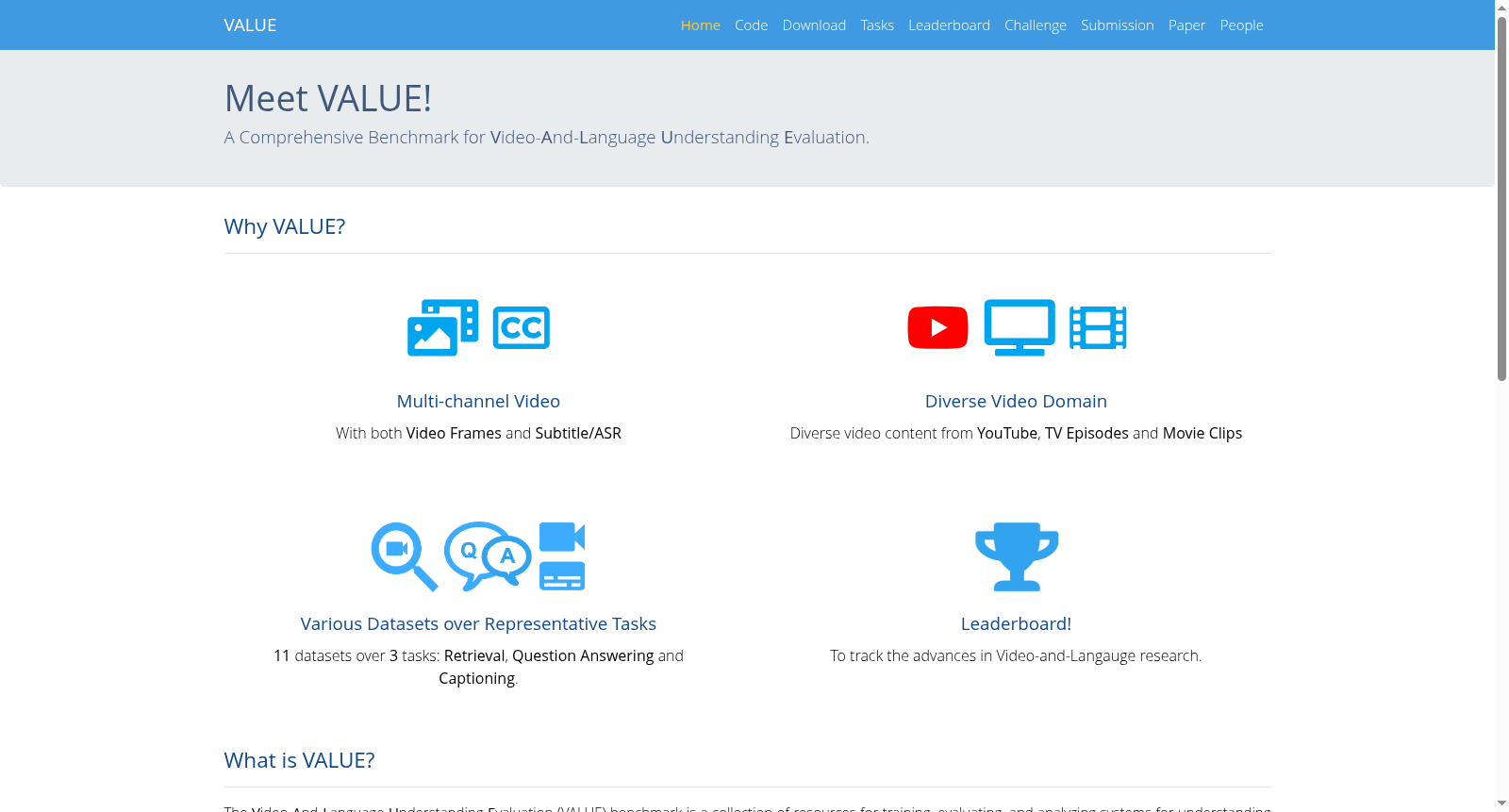
VALUE基准是一个包含11个视频与语言理解数据集的综合评估平台,旨在评估视频与语言理解系统的多样性和泛化能力。这些数据集涵盖了视频检索、视频问答和视频字幕等多种任务,涉及不同类型的视频,如电视剧集、YouTube教学视频和电影片段。VALUE基准不仅关注视频帧的使用,还强调了视频帧与其伴随字幕的结合使用,以及跨多个任务的知识共享。此外,VALUE基准还包括了不同难度级别的任务,并提供了一个统一的评估框架,以跟踪视频与语言理解领域的进展。
The VALUE Benchmark is a comprehensive evaluation platform consisting of 11 video-and-language understanding datasets, designed to assess the diversity and generalization capabilities of video-and-language understanding systems. These datasets cover a variety of tasks including video retrieval, video question answering (video QA), and video captioning, involving diverse video types such as TV drama episodes, YouTube instructional videos, and movie clips. The VALUE Benchmark not only focuses on the utilization of video frames, but also emphasizes the joint use of video frames and their accompanying subtitles, as well as knowledge sharing across multiple tasks. Furthermore, the VALUE Benchmark includes tasks at varying difficulty levels and provides a unified evaluation framework to track progress in the field of video-and-language understanding.
提供机构:
微软公司
创建时间:
2021-06-09
搜集汇总
数据集介绍
构建方式
在视频与语言理解领域,为系统评估提供统一基准的需求日益凸显。VALUE benchmark的构建策略在于整合多样化的数据集,它精心选取了11个涵盖视频检索、问答及描述任务的公开数据集,这些数据源自电视剧集、教学视频及网络短片等多种来源。构建过程中,团队不仅保留了原始视频帧与字幕等多通道信息,还通过自动语音识别技术为部分数据集生成了辅助字幕,以确保多模态输入的完整性。数据划分遵循严格的训练、验证与测试分离原则,并设立了独立的排行榜测试集以保障评估的客观性。
特点
该数据集的核心特点体现在其广泛的覆盖范围与多模态融合的评估导向。它囊括了从10秒到76秒不等长度的视频,内容横跨电视剧、教学、烹饪及日常活动等多种类型,确保了任务在领域、难度与数据规模上的多样性。尤为突出的是,VALUE benchmark强调对视频帧与关联字幕的双通道信息利用,鼓励模型发展跨模态理解能力。其评估体系通过统一的元平均分数整合了检索、问答与描述三大类任务,并提供了丰富的预提取特征与启动代码,为模型性能的公平比较与深入分析奠定了坚实基础。
使用方法
研究人员可通过官方平台获取数据集的多通道输入,包括视频帧特征与字幕文本。模型开发通常遵循预训练与微调相结合的范式,首先利用大规模视频-语言对进行跨模态表示学习,随后在VALUE的特定任务上进行适配。评估时,模型需在统一的测试集上运行,结果提交至在线排行榜系统,系统将根据各任务的预设指标(如检索任务的平均召回率、问答任务的准确率及描述任务的CIDEr-D分数)计算元平均分进行排名。该流程支持单任务训练、多任务学习及跨任务迁移等多种实验设置,旨在全面检验模型的泛化与综合理解能力。
背景与挑战
背景概述
视频与语言理解领域长期缺乏统一的多任务评估基准,导致模型泛化能力难以系统衡量。为此,微软研究院联合多所高校于2021年共同推出了VALUE基准测试,该基准整合了11个涵盖视频检索、问答与描述三大任务的异构数据集,覆盖电视剧、教学视频、生活博客等多种视频类型。其核心目标在于推动能够融合视觉画面与字幕文本的多通道视频理解模型发展,并通过统一评估平台促进跨任务知识共享与模型泛化能力的研究。该基准的建立显著提升了视频语言交叉领域的评估标准化水平,为后续预训练模型与多任务学习研究提供了重要基础设施。
当前挑战
VALUE基准面临的挑战主要体现在任务与数据两个维度。在任务层面,模型需同时解决视频检索中的时序定位、问答中的多模态推理以及描述中的语义生成等异构问题,要求系统具备跨任务泛化与多通道信息融合能力。数据层面则涉及视频时长差异显著、字幕覆盖率不均、领域分布广泛导致的域适应难题,例如电视剧片段与烹饪视频在视觉模式和语言风格上存在巨大差异。此外,基准构建过程中还需克服多源数据集标注标准不统一、测试集隐私保护与特征提取一致性等技术障碍,这些因素共同构成了对下一代视频语言理解系统的综合考验。
常用场景
经典使用场景
在视频与语言理解研究领域,VALUE基准测试集被广泛用于评估多模态模型的综合性能。该基准通过整合11个涵盖视频检索、问答和描述三大经典任务的数据集,为研究者提供了一个统一且多样化的评估平台。其核心应用场景在于系统性地检验模型在跨任务、跨领域和跨数据规模下的泛化能力,尤其强调模型对多通道视频信息(视觉帧与字幕)的融合理解。经典使用方式包括基于HERO等预训练架构进行微调,并在统一的在线评估服务器上对比不同方法在隐藏测试集上的表现,从而推动通用视频语言理解系统的发展。
衍生相关工作
VALUE基准测试集的推出催生了一系列围绕多模态预训练和跨任务泛化的经典研究工作。以HERO架构为代表的层次化编码器模型,通过视频与字幕的跨模态融合机制,成为该基准上的重要基线。后续研究如ClipBERT探索了稀疏采样策略以提升效率,而Frozen-in-Time等研究则验证了图像文本预训练向视频领域的迁移潜力。这些工作不仅深化了对多通道信息融合机制的理解,也推动了如视频语言推理、未来事件预测等新兴任务的算法发展,形成了以VALUE为核心评估标准的视频语言理解研究生态。
数据集最近研究
最新研究方向
在视频与语言理解领域,VALUE基准测试的推出标志着多任务评估框架的兴起,其整合了11个数据集,涵盖视频检索、问答和字幕生成三大任务,旨在推动模型在多样化视频类型、长度和难度下的泛化能力。当前研究前沿聚焦于多通道信息融合,尤其是视觉帧与字幕的协同建模,以应对复杂时空推理和常识理解挑战。热点探索包括基于大规模预训练的跨任务知识迁移,如利用CLIP等图像-文本预训练模型增强视频表征,以及多任务学习策略的优化,以缩小模型与人类性能的差距。这些进展不仅促进了通用视频-语言系统的发展,也为多模态人工智能在现实场景中的应用奠定了评估基础。
相关研究论文
- 1VALUE: A Multi-Task Benchmark for Video-and-Language Understanding Evaluation微软公司 · 2021年
以上内容由遇见数据集搜集并总结生成


