zoengjyutgaai_saamgwokjinji
收藏Hugging Face2024-07-12 更新2024-12-12 收录
下载链接:
https://huggingface.co/datasets/laubonghaudoi/zoengjyutgaai_saamgwokjinji
下载链接
链接失效反馈官方服务:
资源简介:
数据集包含粤语(Cantonese)音频文件及其对应的转录文本。音频文件位于'001/*.wav'路径下,每条数据包含两个字段:'file_name'和'transcription'。数据集的特征包括音频和转录文本,其中音频字段的数据类型为音频,转录文本字段的数据类型为字符串。
创建时间:
2024-07-11
原始信息汇总
張悦楷三國演義數據集
概述
- 语言: 粤语
- 许可证: CC0-1.0
- 标签: 粤语, 音频
数据集配置
- 配置名称: default
- 数据文件:
- 分割: train
- 路径: data/train-*
数据集信息
- 特征:
- 音频: 音频数据类型
- 说话者: 字符串数据类型
- 语言: 字符串数据类型
- 转录文本: 字符串数据类型
- 分割:
- 名称: train
- 字节数: 292395193.0
- 样本数: 308
- 下载大小: 245714871
- 数据集大小: 292395193.0
数据集构建流程
- 从 YouTube 或国内评书网站下载录音源文件,格式为
.webm或.mp3。 - 使用字幕工具为录音添加字幕,生成对应的
.srt文件。 - 将源录音转换为
.wav格式,尽可能无压缩。 - 根据
.srt文件中的时间点,将每一集.wav切分成单句.wav,并将对应文本写入数据集的esd.list。
将 .webm 无损转为 .wav
-
使用 ffmpeg 进行转换,命令如下: bash ffmpeg -i "001.webm" -vn -ar 44100 -c:a pcm_s16le "001.wav"
-
所有
.wav文件已转换为 44100 采样率。
将 .wav 按照对应 .srt 切分成数据集并上传到 HuggingFace
- 运行
process.py脚本,读取.srt文件并将.wav切分成单句,写入/wav/metadata.csv。 - 使用 IPython 命令将数据推送到 HuggingFace: python from datasets import load_dataset from huggingface_hub import login dataset = load_dataset(audiofolder, data_dir=./wav) dataset[train][0] login() dataset.push_to_hub("laubonghaudoi/zoengjyutgaai_saamgwokjinji")
搜集汇总
数据集介绍
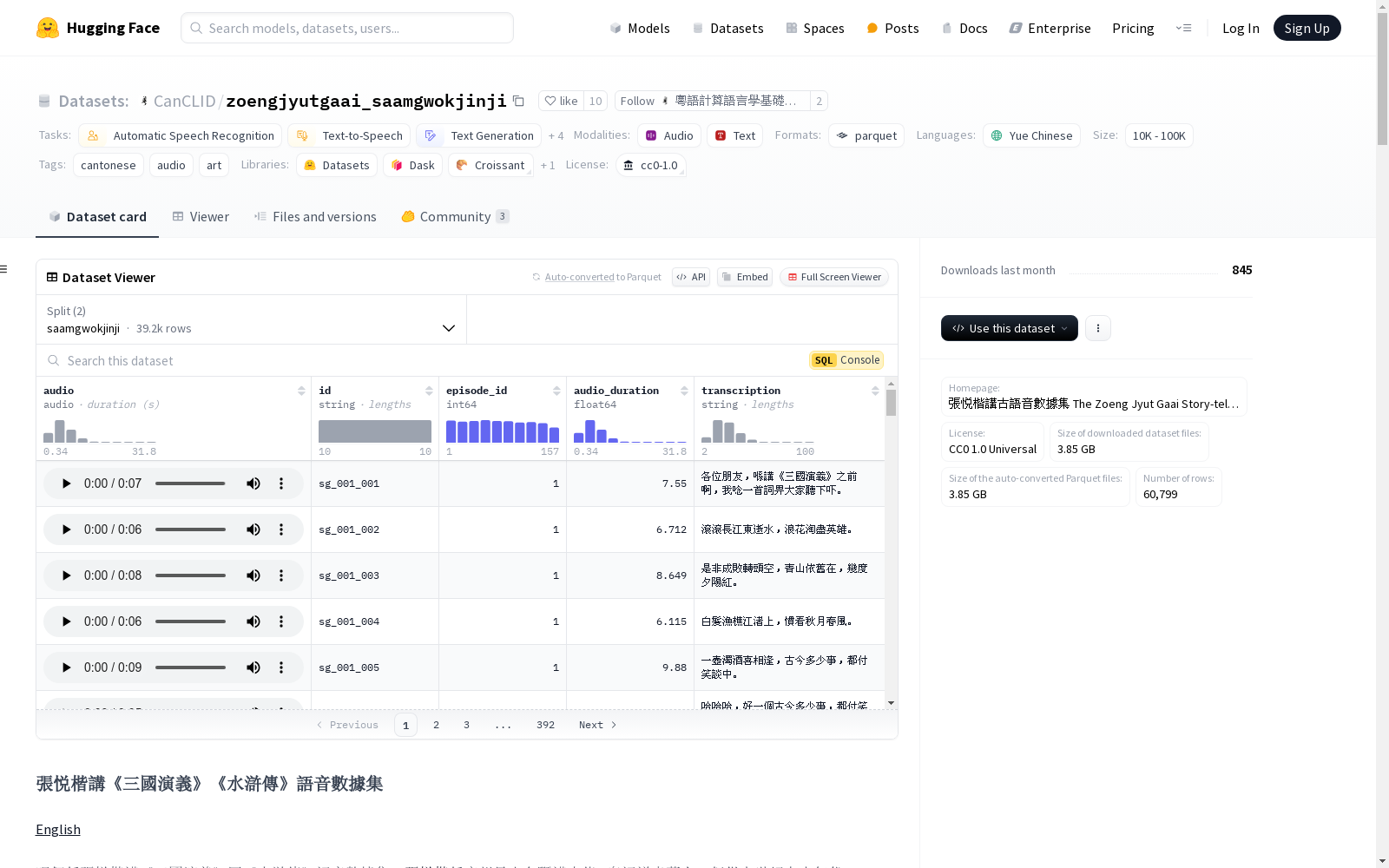
构建方式
该数据集的构建过程始于从YouTube及国内评书网站下载录音源文件,通常为每集半小时长的.webm或.mp3格式。随后,使用字幕工具为这些录音添加字幕,生成对应的.srt文件。接着,将源录音尽可能无压缩地转换为.opus格式。通过运行cut.py脚本,将每集.opus文件根据.srt文件中的时间点切分成单句,并将对应的文本写入数据集的xxx.csv文件中。最后,通过Python脚本将数据推送至HuggingFace平台。
特点
该数据集包含了张悦楷讲述的《三国演义》和《水浒传》的粤语语音数据,具有48000 Hz的采样率,所有文本均采用汉字转写,无阿拉伯数字或英文字母,且使用全角标点。数据集中的音频文件经过切分,适合用于语音合成(TTS)和语音识别(ASR)的训练或测试,同时也适用于语言学、文学研究及艺术欣赏。
使用方法
用户可以通过Python代码直接从HuggingFace加载该数据集,或使用命令行工具选择性地下载特定目录以节省时间和空间。数据集中的音频文件支持多种格式转换,用户可根据需要将.opus文件转换为.wav格式,或进行重采样处理。此外,数据集提供了详细的统计脚本和切分脚本,便于用户进行数据分析和处理。
背景与挑战
背景概述
《zoengjyutgaai_saamgwokjinji》数据集是一个专注于粤语说书艺术的语音数据集,收录了著名粤语说书艺人张悦楷讲述的《三国演义》和《水浒传》的音频内容。张悦楷自上世纪七十年代起在广东各大电台进行说书表演,其声音成为许多广州人的共同记忆。该数据集由CanCLID团队构建,旨在为语音合成(TTS)、语音识别(ASR)以及语言学、文学研究提供高质量的粤语语音数据。数据集包含近4万条音频片段,涵盖了丰富的粤语语音特征和文化背景,为粤语语音技术的研究与发展提供了重要资源。
当前挑战
该数据集在构建和应用过程中面临多重挑战。首先,粤语作为一种复杂的方言,其语音特征与普通话存在显著差异,如何在语音识别和合成任务中准确捕捉这些特征是一个技术难题。其次,数据集的构建依赖于从网络平台获取的原始音频,这些音频的质量和格式参差不齐,需要进行复杂的预处理和格式转换。此外,粤语文本的规范化处理也面临挑战,尤其是在标点符号、数字和字母的转换过程中,如何保持文本的一致性和准确性是一个关键问题。最后,数据集的规模较大,存储和处理这些数据需要高性能的计算资源,这对研究者的硬件条件提出了较高要求。
常用场景
经典使用场景
在语音技术领域,zoengjyutgaai_saamgwokjinji数据集被广泛应用于语音合成(TTS)和语音识别(ASR)的研究与开发。该数据集包含了张悦楷讲述的《三国演义》和《水浒传》的粤语语音数据,为研究者提供了丰富的语音样本和对应的文本转录,极大地推动了粤语语音处理技术的发展。
解决学术问题
该数据集解决了粤语语音处理中的多个关键问题,如语音识别的准确性和语音合成的自然度。通过提供高质量的语音和文本对,研究者可以训练更精确的语音识别模型和更自然的语音合成系统。此外,该数据集还为语言学和文学研究提供了宝贵的资源,帮助学者深入分析粤语的语音特征和文学表达。
衍生相关工作
该数据集衍生了许多经典的研究工作,如基于深度学习的粤语语音识别模型和语音合成系统。这些工作不仅在学术界引起了广泛关注,还在工业界得到了实际应用。例如,一些研究团队利用该数据集开发了高精度的粤语语音识别系统,并将其应用于智能家居和车载语音控制系统中,极大地提升了用户体验。
以上内容由遇见数据集搜集并总结生成


