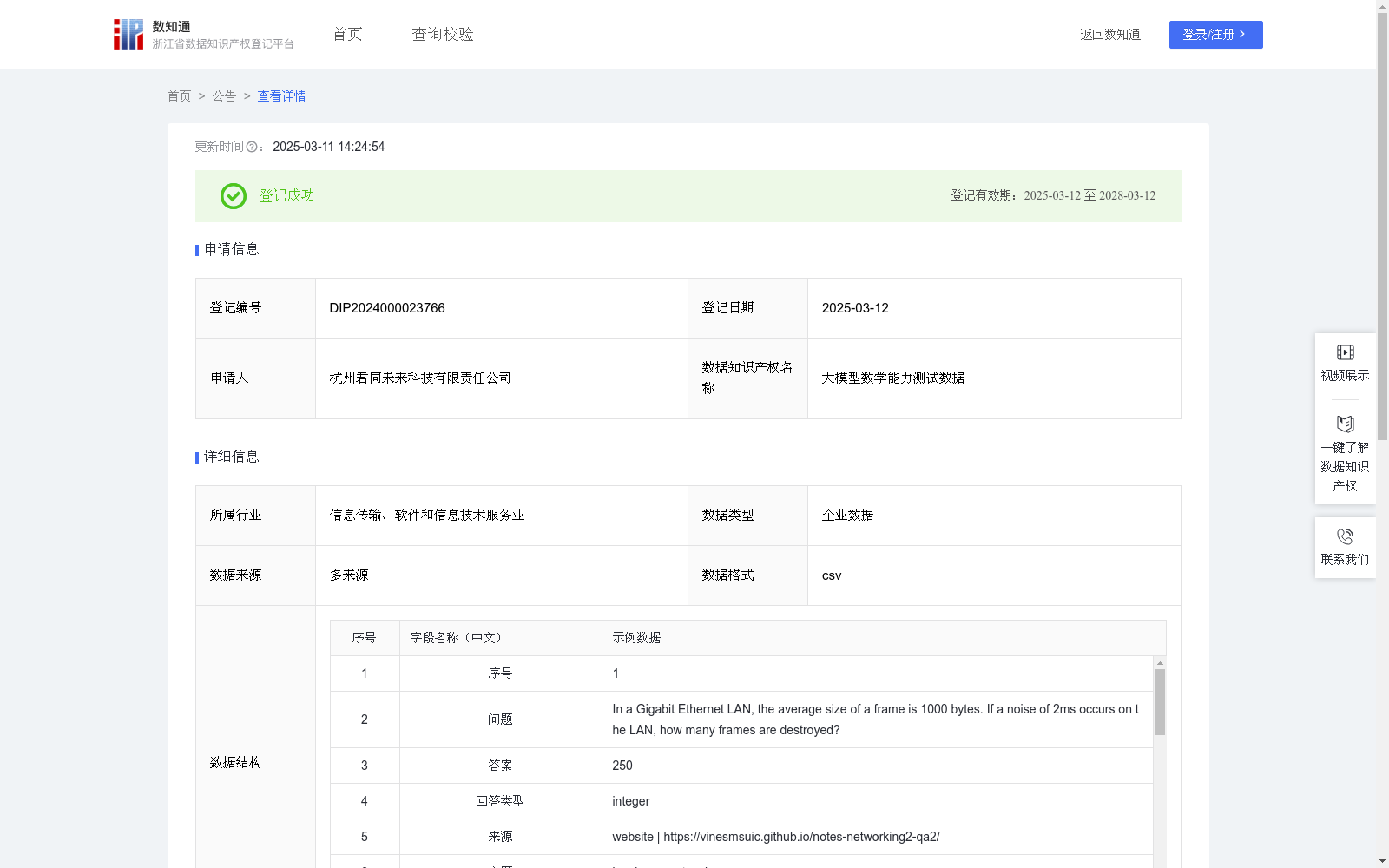
大模型数学能力测试数据
收藏浙江省数据知识产权登记平台2025-03-11 更新2025-03-12 收录
下载链接:
https://www.zjip.org.cn/home/announce/trends/116751
下载链接
链接失效反馈官方服务:
资源简介:
通过精心设计和多层次的数据处理流程,大模型数学能力测试数据集被打造为高质量、高标准化的评估工具。该数据集覆盖广泛的数学主题,包括代数、几何、微积分、数论以及概率与统计,为全面评估大语言模型的数学能力提供了丰富的测试素材,可以深入了解模型在数学问题求解中的语言表达能力、题意快速解析能力以及解答推导过程的表现。测试还能够评估模型在不同应用场景中的适用性,如数学教学辅导、科学研究支持、金融数据分析和工程计算辅助等。这一数据集不仅有助于衡量模型的数学处理能力,还能为实际应用场景提供科学依据和指导。(1) 数据来源:数据集的原始素材来源于Hugging Face开源平台,涵盖公开数学题库、学术会议论文中的数学问题、在线数学学习平台的题目集合,以及人工设计的创新型数学问题。所有数据均标注明确来源,确保其可靠性和科学性。
(2) 数据标准化处理:对收集的数学题目进行全面标准化,包括统一题目格式、规范化语言表达、标准化变量定义以及消除歧义性描述,确保题目清晰易懂,便于大模型解析与处理。
(3) 数据分类与分层:依据主题将题目进行分类并层级划分,涵盖从基础数学知识到高阶数学推理的多个维度,为大模型的多维度能力测试提供科学依据。
(4) 关键信息标注:在题目中添加详尽的辅助标注信息,包括题目类型、解题步骤、推导过程、正确答案以及逻辑分支选择。这些标注为大模型解题分析提供了严谨的验证依据和丰富的评估维度。
(5) 问题改编与生成:基于原始题目集合,通过改编技术生成多样化的题目。例如,变换题目语言表达、替换数据参数或扩展问题条件,提升数据集的多样性和覆盖范围。
(6) 测试指标设计:制定全面的数学能力评估指标,包括问题理解正确率、计算精确度、逻辑推导完整性、解题效率,以及对提示性问题和开放性问题的响应质量,全面衡量模型能力。
(7) 模型评估与验证:利用数据集对大模型进行综合性评估,分析其在理解数学问题、推导解答过程以及生成正确解答方面的表现,并通过对比不同大模型的测试结果,形成系统化的数学能力评价报告,为模型改进和应用提供指导依据。
Designed through elaborate and multi-tiered data processing workflows, the Large Language Model (LLM) Mathematical Ability Test Dataset is developed as a high-quality, highly standardized evaluation tool. This dataset covers a wide range of mathematical topics, including algebra, geometry, calculus, number theory, probability and statistics, providing abundant test materials for comprehensively evaluating the mathematical capabilities of LLMs, and enabling in-depth insights into the model's ability to express mathematical reasoning in natural language, quickly comprehend the intent of mathematical problems, and perform in the derivation and solution of problems. The test can also evaluate the applicability of LLMs in various application scenarios, such as mathematics teaching assistance, scientific research support, financial data analysis, engineering computing assistance, and more. This dataset not only helps measure the mathematical processing capabilities of models but also provides scientific basis and guidance for real-world application scenarios.
(1) Data Source: The original materials of the dataset are sourced from the Hugging Face open-source platform, including public mathematics question banks, mathematical problems from academic conference papers, question collections from online mathematics learning platforms, and innovatively handcrafted manual mathematical problems. All data are clearly annotated with their sources to ensure their reliability and scientific validity.
(2) Data Standardization Processing: Comprehensive standardization is performed on the collected mathematical problems, including unifying question formats, standardizing linguistic expressions, standardizing variable definitions, and eliminating ambiguous descriptions, to ensure that the questions are clear and easy to understand, facilitating parsing and processing by LLMs.
(3) Data Classification and Hierarchization: The questions are classified and hierarchically divided according to their topics, covering multiple dimensions from basic mathematical knowledge to advanced mathematical reasoning, providing a scientific basis for multi-dimensional capability testing of LLMs.
(4) Key Information Annotation: Detailed auxiliary annotation information is added to the questions, including question types, solution steps, derivation processes, correct answers, and logical branch selections. These annotations provide rigorous verification basis and rich evaluation dimensions for LLM problem-solving analysis.
(5) Question Adaptation and Generation: Based on the original question collection, diverse questions are generated through adaptation techniques, such as transforming the linguistic expression of questions, replacing data parameters, or expanding problem conditions, to enhance the diversity and coverage of the dataset.
(6) Test Indicator Design: Comprehensive mathematical ability evaluation indicators are formulated, including problem understanding accuracy, calculation precision, logical derivation completeness, problem-solving efficiency, and response quality to prompt-based and open-ended questions, to comprehensively measure model capabilities.
(7) Model Evaluation and Validation: Comprehensive evaluations of LLMs are conducted using the dataset, analyzing their performance in comprehending mathematical problems, deriving solution processes, and generating correct answers. By comparing the test results of different LLMs, a systematic mathematical ability evaluation report is formed, providing guidance for model improvement and application.
提供机构:
杭州君同未来科技有限责任公司
创建时间:
2024-12-23
搜集汇总
数据集介绍
特点
该数据集是一个用于评估大语言模型数学能力的高质量测试工具,包含518条记录,覆盖广泛的数学主题,每年更新一次。数据来源于多个公开渠道,经过标准化处理和分类,适用于数学教学、科研支持等多个应用场景。
以上内容由遇见数据集搜集并总结生成


