sussy_data
收藏Hugging Face2025-04-04 更新2025-04-07 收录
下载链接:
https://huggingface.co/datasets/ItsTYtan/sussy_data
下载链接
链接失效反馈官方服务:
资源简介:
该数据集包含了使用distilabel工具生成的关于新加坡公共住房话题的问题。这些问题旨在分析受访者的政治立场,特别是左翼或右翼的政治倾向。数据集的问题生成遵循一定的指导原则,如保持问题中立、不提出特定的政治立场、避免冒犯性问题等,并且要求使用清晰易懂的语言。数据集中的例子显示了如何按照格式要求生成10个不同的问题,这些问题覆盖了话题的各个方面,并允许评估受访者的政治观点。
创建时间:
2025-03-24
搜集汇总
数据集介绍
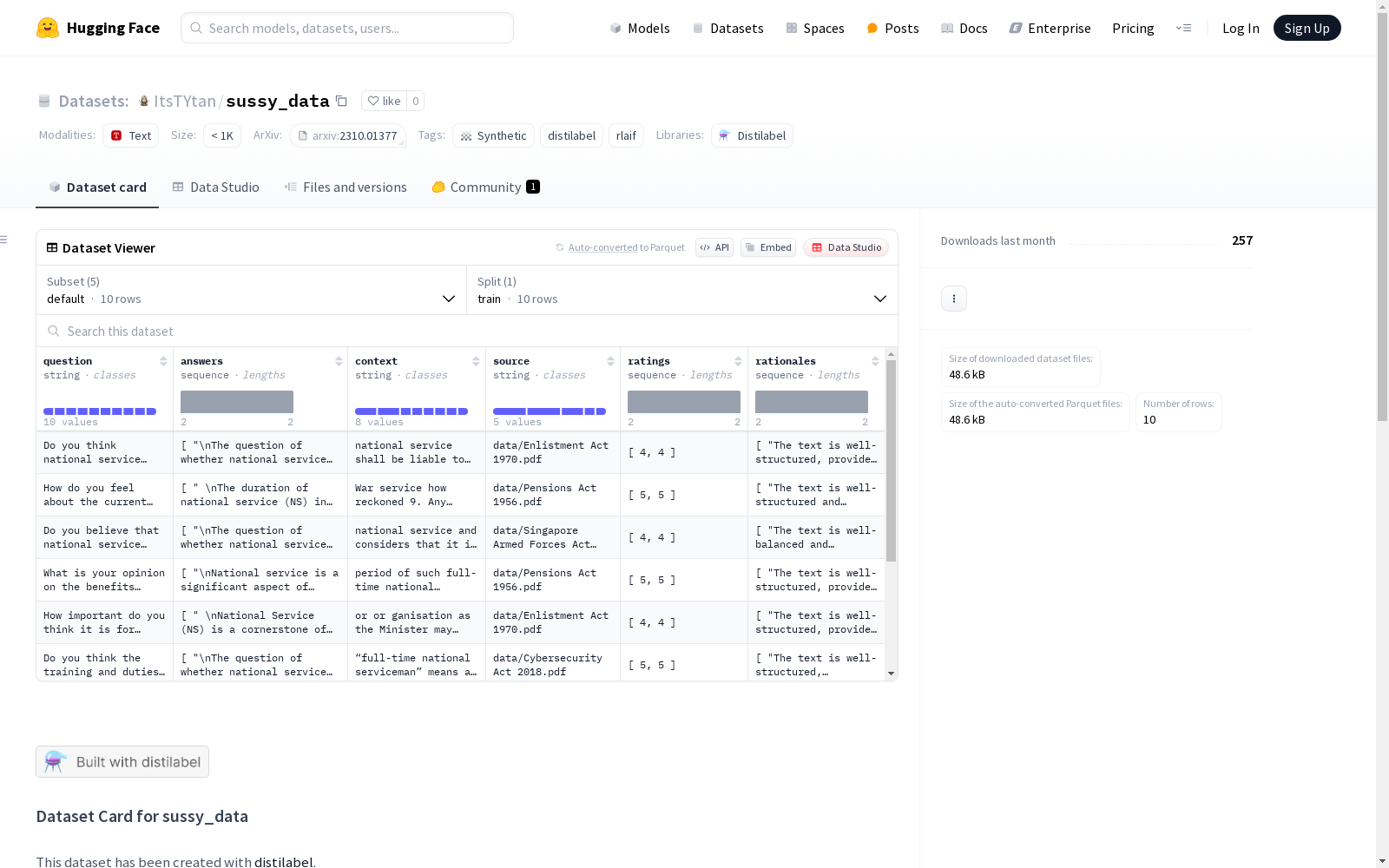
构建方式
sussy_data数据集通过distilabel框架构建,采用多配置策略生成不同子集。数据来源包括法律文本解析和AI生成内容,通过结构化管道处理原始文档并合成问答对。构建过程中整合了文本生成模型输出与人工标注元素,采用分阶段质量验证确保数据可靠性。各子集通过独立配置文件管理,支持灵活的数据组合与扩展。
特点
该数据集突出表现为多模态结构设计,包含问答对、评分依据和生成溯源信息。核心特征包括详尽的元数据标注,如token统计和模型来源,以及双盲评分机制下的质量评估。数据维度涵盖指令遵循、上下文理解和生成质量评估,特别适合强化学习与反馈优化研究。不同配置间的差异化设计为对比实验提供了天然基准。
使用方法
研究者可通过HuggingFace接口直接加载特定配置,或使用distilabel复现完整数据管道。典型应用场景包括:使用default配置进行问答质量评估,调用text_generation子集研究RAG技术,或结合open_router配置分析多模型输出差异。数据加载支持全量获取或分片处理,内置的结构化字段便于进行细粒度的统计分析。
背景与挑战
背景概述
sussy_data数据集是由Argilla团队通过distilabel框架构建的合成数据集,专注于文本生成与评估领域。该数据集创建于2024年,作为UltraFeedback研究的衍生成果,旨在探索规模化AI反馈对语言模型优化的影响。数据集包含多配置文本生成结果、人工评分及评估依据,其核心价值在于为RLAIF(基于AI反馈的强化学习)研究提供结构化评估基准。通过集成不同模型生成内容和人工反馈数据,该数据集为研究语言模型对齐、生成质量评估等关键问题提供了新的实验平台。
当前挑战
该数据集面临双重技术挑战:在领域问题层面,需解决文本生成质量评估的主观性难题,包括评分标准一致性保持和多维度生成特性(如事实性、流畅性)的量化评估;在构建过程层面,合成数据的真实性验证成为关键瓶颈,需要平衡自动化生成效率与人工校验精度。数据异构性带来的整合困难也不容忽视,不同配置(如带RAG与无RAG生成)的结果可比性建立需要复杂的标准化处理。此外,小规模样本(n<1K)对统计显著性的影响,以及评分者间信度(inter-rater reliability)的保障,均为该数据集应用中的潜在限制因素。
常用场景
经典使用场景
在自然语言处理领域,sussy_data数据集以其独特的结构成为评估和优化文本生成模型的重要工具。该数据集通过包含问题、答案、上下文及评分等多维度信息,为研究者提供了丰富的语料库,特别适用于对话系统和问答系统的开发与测试。其精心设计的评分机制和详细注释,使得模型在生成文本时能够更好地理解用户意图并提升回答质量。
实际应用
在实际应用中,sussy_data数据集已被广泛应用于智能客服、教育辅助和内容生成等多个领域。企业利用该数据集训练和优化其对话系统,以提供更精准和人性化的服务。教育机构则通过该数据集开发智能辅导系统,帮助学生更好地理解和掌握复杂概念。此外,内容创作者也借助该数据集生成更符合读者需求的文本内容。
衍生相关工作
基于sussy_data数据集,研究者们已经开展了一系列创新性工作。这些工作包括开发更先进的文本质量评估算法、探索多模态对话系统以及研究跨语言文本生成技术。数据集中的评分机制和详细注释也为后续研究提供了重要参考,推动了整个文本生成领域的发展。
以上内容由遇见数据集搜集并总结生成


