SINAI/ALIA-es-biomedical-pairs
收藏Hugging Face2026-05-06 更新2026-05-10 收录
下载链接:
https://hf-mirror.com/datasets/SINAI/ALIA-es-biomedical-pairs
下载链接
链接失效反馈官方服务:
资源简介:
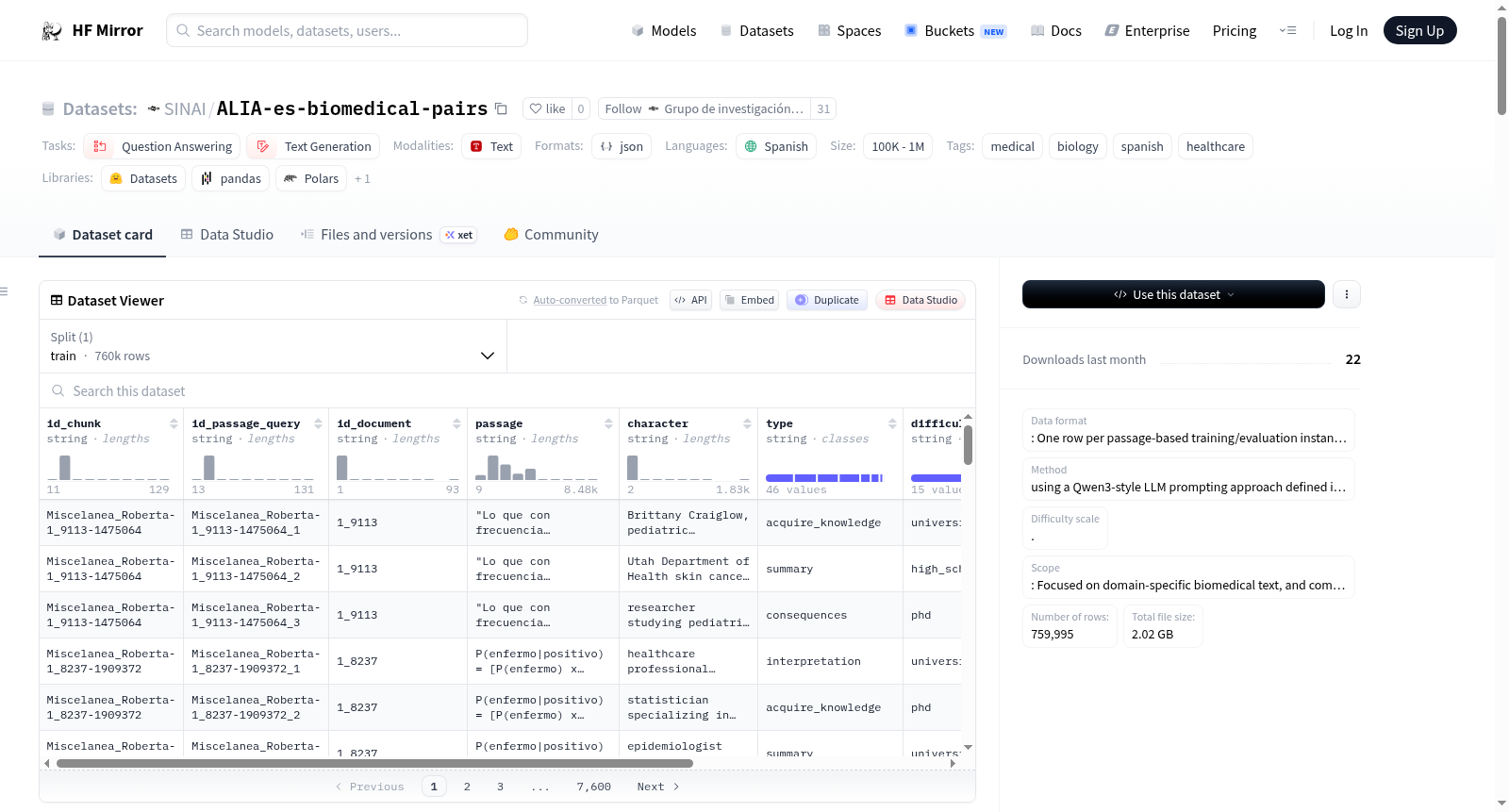
**ALIA西班牙生物医学和医疗保健检索对语料库**包含表格实例,旨在使用基于段落的查询数据训练和评估检索导向模型(例如密集检索器/嵌入编码器),这些查询数据是通过集成在ALIA编码器管道中的Qwen3风格提示工作流生成的。它保留了原始文档和段落的来源,同时暴露了诸如问题`类型`和`难度`(从`高中`到`博士`级别)等控制。
The **ALIA Spanish Biomedical and Healthcare Retrieval Pairs Corpus** contains tabular instances designed to train and evaluate retrieval-oriented models (e.g., dense retrievers / embedding encoders) using passage-grounded query data produced with a Qwen3-style prompting workflow integrated in the ALIA encoders pipeline. It preserves provenance to the original document and chunk while exposing controls such as question `type` and `difficulty` (ranging from `high_school` to `phd` level).
提供机构:
SINAI
搜集汇总
数据集介绍
构建方式
该数据集源自SINAI研究组整合的ALIA-es-biomedical语料库,该库汇聚了临床摘要、PubMed翻译文本、卫生机构出版物等丰富的西班牙语生物医学资料。原始文档经精细切分形成段落块,并保留文档级与段落级溯源标识。在此基础上,项目利用Qwen3风格的提示词工程管线,为每个段落自动生成对应的问题,同时赋予问题类型与难度等级(高中、大学、博士)等元数据标签,从而构建出大规模、高质量的查询-段落配对数据集。
特点
数据集囊括近76万条实例,覆盖14种问题类型与3个学术难度层级,其中大学级别占比最高。问题设计模拟特定角色(如儿科皮肤科医生)的提问视角,增强了交互真实感。数据来源多元,以Translated_Pubmed和Miscelanea_Roberta为主,兼顾CIMA_AEMPS、Wikipedia_Biomedical等专业资源,为领域检索与问答任务提供了丰富的训练与评估素材。
使用方法
用户可通过HuggingFace Datasets库加载数据集,并基于'difficulty'字段按难度层级进行过滤,以构建分层训练集或评估集。推荐按'doc_id'而非段落ID划分数据,以避免上下文泄露。该数据集专为训练密集检索编码器而设计,亦可用于领域特定检索增强生成(RAG)系统的微调与评估,支持通过'source_id'实现细粒度的溯源与消融实验。
背景与挑战
背景概述
在自然语言处理领域中,面向特定领域的检索与问答系统发展迅速,尤其在生物医学这一专业性强、术语密集的场景下,高质量、领域专属的语料资源成为推动模型进步的关键。ALIA-es-biomedical-pairs数据集由西班牙哈恩大学SINAI研究团队于2026年创建,依托ALIA项目与SCAYLE超级计算资源,旨在填补西班牙语生物医学与医疗健康领域检索对训练数据的空白。该数据集源于SINAI/ALIA-es-biomedical语料库,融合了PubMed翻译文献、临床摘要、卫生机构出版物等多源内容,通过Qwen3式大语言模型提示工程自动生成查询-段落对,并引入难度分级(高中、大学、博士)与问题类型标签,强调来源溯源与数据透明度。该数据集已收录超过75万实例,为西班牙语生物医学密集检索模型训练与评估提供了规模化、结构化、领域适配的语料基础,对推动低资源语言的专业NLP应用具有重要示范意义。
当前挑战
该数据集所面临的挑战首先体现在生物医学领域的复杂性与专业性上,西班牙语生物医学文本蕴含大量医学术语、概念层级与跨语言翻译造成的语义偏差,使得模型需具备深度领域理解能力方能实现精准检索,这远超通用语言模型的范畴。在构建过程中,数据集面临难度分级校准的挑战,即由模型自动划分的‘高中’、‘大学’、‘博士’级别可能与人类专家判断存在差异,影响评估的科学性。此外,数据来源分布极不均衡,Translated_Pubmed与Miscelanea_Roberta两大来源占比超过95%,可能导致模型过拟合特定文体风格,削弱泛化能力。合成查询的LLM伪影也是不可忽视的问题,生成的提问模式可能与真实用户查询存在风格差异,需额外过滤处理。最终,以块级而非文档级划分数据集时存在信息泄露风险,推荐采用文档级拆分以保证评估的公平性。
常用场景
经典使用场景
ALIA-es-biomedical-pairs数据集专为检索导向模型的训练与评估而设计,其核心应用场景在于构建面向西班牙语生物医学领域的稠密检索器与嵌入编码器。该数据集以段落为锚点,通过Qwen3风格的提示流程生成对应的查询,形成高质量的查询-段落配对实例,从而支撑模型在域内文本检索任务上的有效学习。研究人员可依据问题的类型和难度层级(高中、大学、博士)对数据进行分层筛选,开展细粒度的模型性能分析与消融实验。
解决学术问题
该数据集有效解决了西班牙语生物医学领域检索数据集匮乏的困境,尤其针对专业词汇密集、知识结构复杂的医疗与生物学文本,填补了面向非英语资源在低资源语言场景下的检索基准空白。它使学术界得以系统性地探讨密集检索模型在域内文本上的泛化能力、难度感知的校准效应,以及跨来源文档(如PubMed翻译、临床摘要、药监资料)的一致性检索挑战。该资源推动了对合成查询与真实用户查询之间分布差异的深入研究。
衍生相关工作
该数据集衍生了一系列相关研究工作,包括但不限于基于其难度标签设计的跨级别检索能力评估框架,以及利用其来源标识符开展的多源文档一致性检索实验。此外,基于该数据的稠密编码器训练流程已被整合至ALIA-UJA项目脚本,催生了针对生物医学西班牙语的最优分块策略与查询生成管线研究。未来,它有望与MESINESP、MedlinePlus等基准结合,推动跨语种医学检索的系统性评估与迁移学习探索。
以上内容由遇见数据集搜集并总结生成


