LLM-annotation-msmarco-nq
收藏Hugging Face2026-04-01 更新2026-04-02 收录
下载链接:
https://huggingface.co/datasets/Trustworthy-Information-Access/LLM-annotation-msmarco-nq
下载链接
链接失效反馈官方服务:
资源简介:
该数据集名为“Utility-Focused Annotation for IR and RAG”,是一个大规模由大型语言模型(LLM)标注的检索数据集,旨在减少对昂贵人工标注的依赖。数据集通过使用Qwen2.5-32B和Qwen3-32B模型对MS MARCO和NQ数据集中的文档效用进行标注,填补了检索相关性与生成效用之间的空白。具体数据规模包括MS MARCO的约50万查询和NQ的约5万查询。数据集文件包含一个名为'annotation_positive.tsv'的文件,格式为查询ID与正面文档列表的对应关系。该数据集适用于信息检索(IR)和检索增强生成(RAG)系统的训练和评估。
创建时间:
2026-03-31
原始信息汇总
数据集概述
基本信息
- 数据集名称: Utility-Focused LLM Annotation for Retrieval and Retrieval-Augmented Generation
- 托管地址: https://huggingface.co/datasets/Trustworthy-Information-Access/LLM-annotation-msmarco-nq
- 许可证: cc-by-nc-4.0
- 语言: 英语 (en)
- 标签: IR, Retrieval, RAG, Annotation
- 数据规模: 10K<n<100K
研究背景与目的
- 探索利用大语言模型(LLMs)为训练检索和检索增强生成系统标注文档效用,旨在减少对昂贵人工标注的依赖。
- 通过使用LLMs标注文档效用,解决检索相关性与生成效用之间的差距。
- 使用Qwen2.5-32B和Qwen3-32B模型,在MS MARCO数据集和NQ数据集上进行了效用标注。
数据集内容
- 数据集名称: Utility-Focused Annotation for IR and RAG
- 描述: 一个大规模LLM标注的检索数据集。
- 数据源与规模:
- MS MARCO: 约50万条查询。
- NQ: 约5万条查询。
数据结构
- 核心文件:
annotation_positive.tsv - 格式: 以制表符分隔的值文件。
- 字段说明:
query_id pos_d1,pos_d2,pos_d3,...
关联资源
- 研究论文: https://aclanthology.org/2025.emnlp-main.88/ (Accepted to EMNLP 2025 Main)
- 模型: https://huggingface.co/hengranZhang/Utility_focused_annotation
- 其他数据集: https://huggingface.co/datasets/fnlp/OmniAction
- 代码仓库: https://github.com/Trustworthy-Information-Access/Utility-Focused-LLM-Annotation
- 框架图: https://raw.githubusercontent.com/Trustworthy-Information-Access/Utility-Focused-LLM-Annotation/main/framework.jpg
引用信息
bibtex @inproceedings{zhang2025utility, title={Utility-Focused LLM Annotation for Retrieval and Retrieval-Augmented Generation}, author={Zhang, Hengran and Tang, Minghao and Bi, Keping and Guo, Jiafeng and Liu, Shihao and Shi, Daiting and Yin, Dawei and Cheng, Xueqi}, booktitle={Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing}, pages={1683--1702}, year={2025} }
搜集汇总
数据集介绍
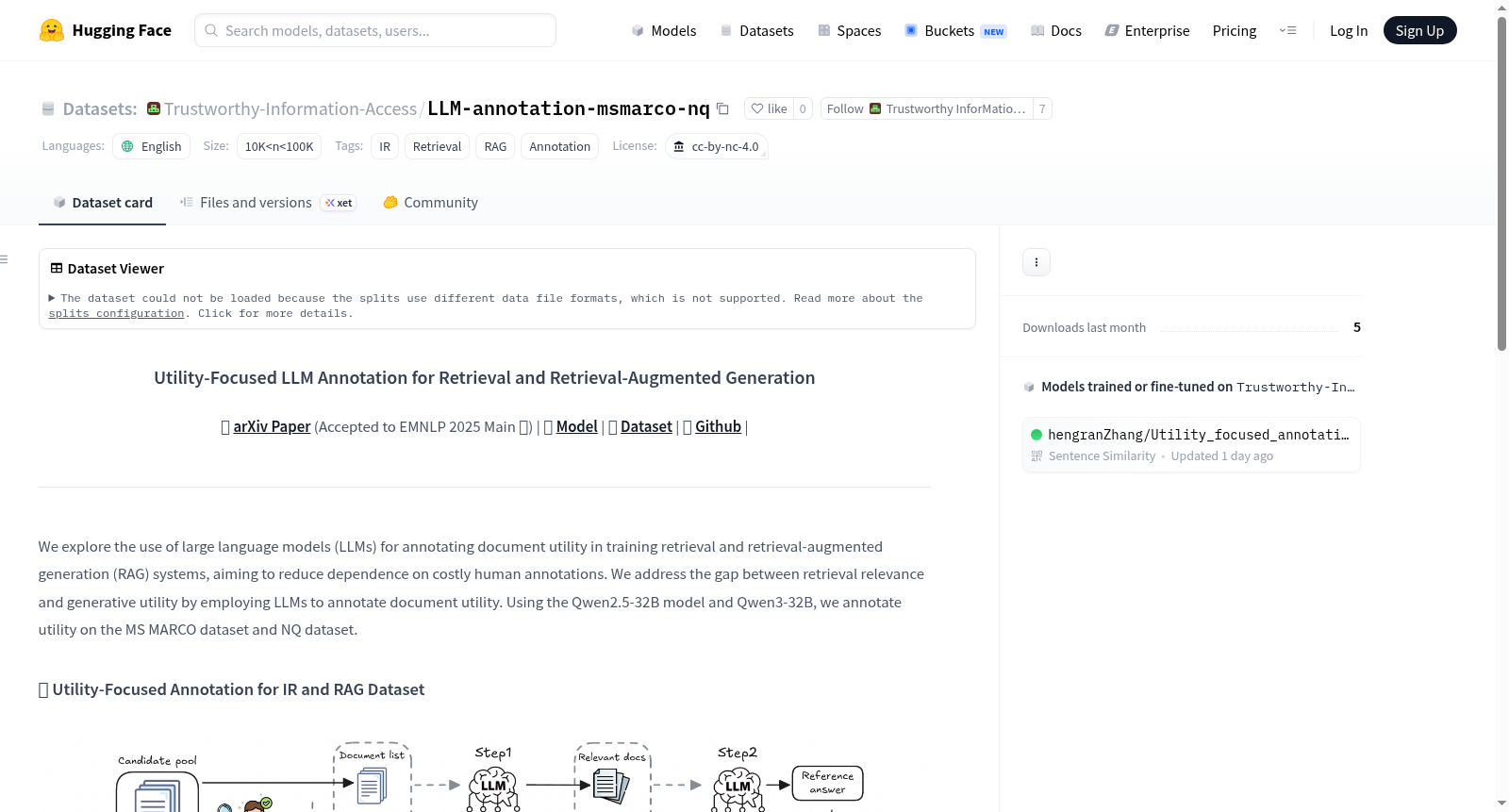
构建方式
在信息检索与检索增强生成领域,传统依赖人工标注的方式成本高昂且难以扩展。为此,该数据集采用先进的大语言模型进行文档效用标注,以弥检索相关性与生成效用之间的鸿沟。具体构建过程中,研究团队运用Qwen2.5-32B与Qwen3-32B模型,对MS MARCO数据集中约50万条查询及NQ数据集中约5万条查询进行了系统性的效用标注,从而生成了大规模、高质量的标注数据,为训练检索与RAG系统提供了可靠基础。
特点
该数据集的核心特点在于其专注于文档的生成效用,而非传统的检索相关性,这直接契合了检索增强生成任务的实际需求。数据集规模庞大,覆盖了MS MARCO与NQ两个广泛使用的基准,确保了数据的多样性与代表性。其标注结果以结构化形式呈现,例如annotation_positive.tsv文件清晰列出了查询ID及其对应的正面文档序列,便于后续模型训练与评估。这种以效用为中心的标注视角,为开发更精准、实用的检索与生成系统开辟了新路径。
使用方法
该数据集主要服务于信息检索与检索增强生成系统的训练与评估。研究人员可直接加载数据集文件,利用其中提供的查询与经过大语言模型标注的效用文档对,来训练或微调检索器模型,使其能够更好地识别对后续生成任务有实际帮助的文档。在RAG系统构建中,该数据可用于优化检索模块,确保检索到的文档不仅相关,而且具备高度的生成效用。数据集的标准化格式也方便与现有评估框架集成,进行系统性的性能对比与分析。
背景与挑战
背景概述
在信息检索与检索增强生成领域,高质量的训练数据是提升系统性能的关键。传统方法依赖人工标注,成本高昂且难以规模化。为应对这一挑战,由清华大学、中国科学院等机构的研究人员于2025年提出了LLM-annotation-msmarco-nq数据集。该数据集旨在探索利用大语言模型对文档效用进行自动化标注,以弥合检索相关性与生成效用之间的鸿沟,从而降低对人工标注的依赖,推动检索与RAG系统的训练效率与效果。其核心研究问题聚焦于如何通过LLM生成的效用标注,优化检索排序与生成质量,为相关领域提供了大规模、低成本的数据资源,对信息检索与自然语言处理的研究具有重要影响力。
当前挑战
该数据集致力于解决信息检索与检索增强生成中效用评估的挑战。传统检索系统通常基于相关性排序,但高相关性文档未必能有效支持后续生成任务,这导致检索与生成环节脱节。构建过程中,研究人员面临如何确保LLM标注的准确性与一致性,以及如何将效用标注无缝集成到现有训练流程中的难题。此外,处理MS MARCO和NQ等大规模数据集时,需平衡标注效率与质量,避免引入模型偏见,这些挑战共同构成了数据集开发与应用的核心障碍。
常用场景
经典使用场景
在信息检索与检索增强生成领域,传统方法依赖于人工标注的相关性判断,成本高昂且难以扩展。LLM-annotation-msmarco-nq数据集通过引入大型语言模型对文档效用进行自动化标注,为训练检索模型和RAG系统提供了大规模、高质量的标注数据。该数据集经典应用于微调检索器或重排序模型,使其能够更精准地识别与查询在语义和生成任务上均具有高实用价值的文档,从而提升端到端检索系统的性能。
衍生相关工作
围绕该数据集衍生的经典工作主要集中在效用感知的检索模型设计与RAG系统优化。例如,基于其标注数据训练的稠密检索器(如ANCE、DPR的变体)在MS MARCO和NQ基准测试中取得了显著提升。同时,一系列研究探索了如何将文档效用分数无缝集成到生成器的注意力机制或提示工程中,从而催生了如“效用加权检索”和“动态文档选择”等新颖方法,持续推动着检索与生成协同演进的前沿研究。
数据集最近研究
最新研究方向
在信息检索与检索增强生成领域,传统依赖人工标注评估文档相关性的方法面临成本高昂与效率瓶颈。LLM-annotation-msmarco-nq数据集通过引入大语言模型对MS MARCO和NQ数据集进行实用性标注,旨在弥合检索相关性与生成效用之间的鸿沟。这一前沿探索聚焦于利用Qwen2.5-32B与Qwen3-32B等先进模型自动化生成标注,推动检索模型与RAG系统向效用驱动范式演进,显著降低对人工标注的依赖,并为高效、可扩展的检索训练与评估提供新基准。该研究呼应了当前人工智能领域对自动化、低成本数据标注的迫切需求,为构建更稳健、实用的信息访问系统奠定了数据基础。
以上内容由遇见数据集搜集并总结生成


