ru-semantic-anomaly
收藏Hugging Face2025-11-19 更新2025-11-20 收录
下载链接:
https://huggingface.co/datasets/VorSgushenki/ru-semantic-anomaly
下载链接
链接失效反馈官方服务:
资源简介:
俄语语义异常数据集,包含1065对句子,每对句子由一个语义异常的句子和其流畅自然的修正句子组成。所有错误都是人工制作并具有语言学动因。
创建时间:
2025-11-17
原始信息汇总
Russian Semantic Anomaly Dataset 数据集概述
数据集基本信息
- 语言:俄语
- 许可证:MIT
- 数据集名称:Russian Semantic Anomaly Dataset
- 标签:俄语、语义错误、对比、分类、文本校正、语言学
- 规模:1K<n<10K
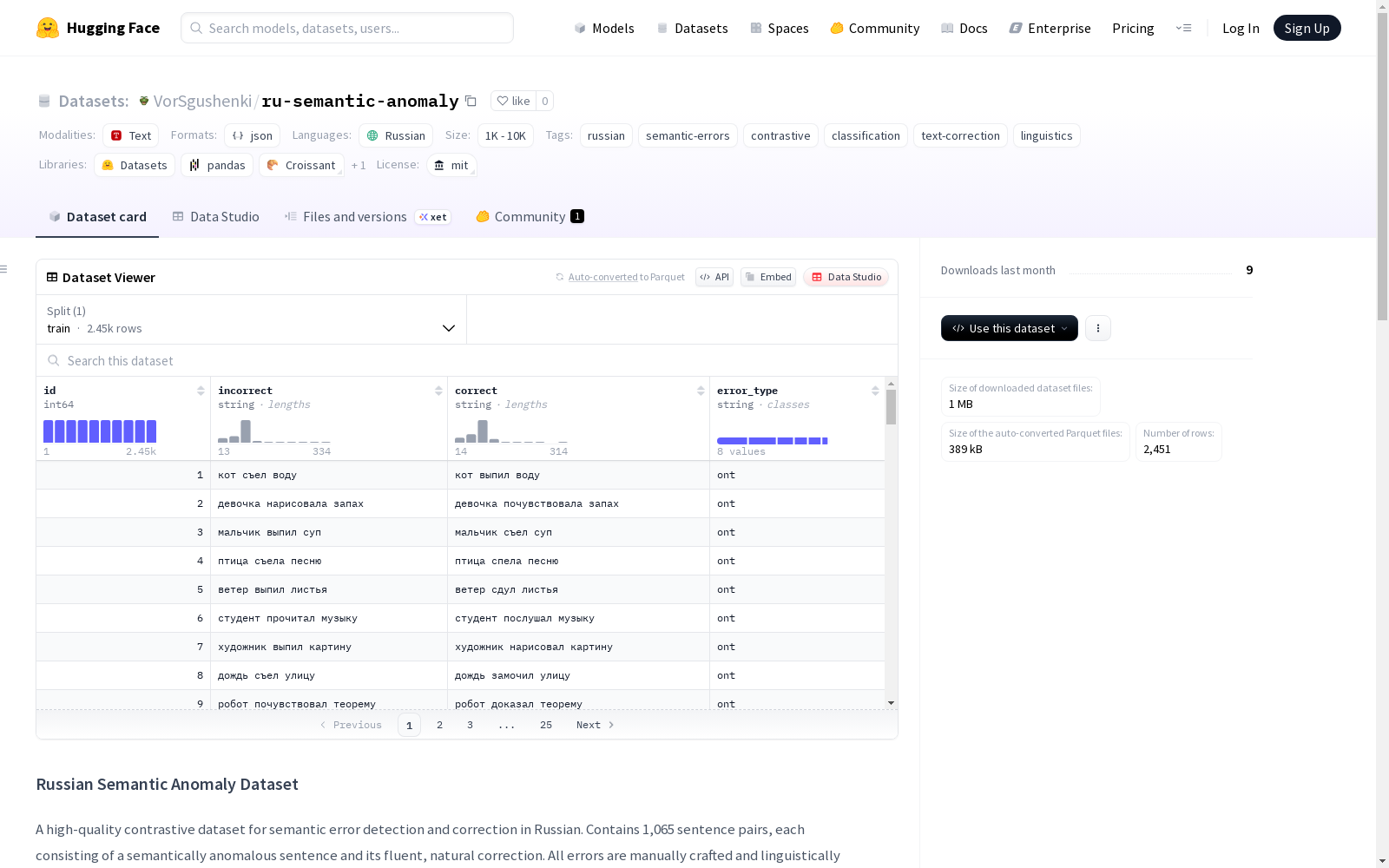
数据集内容
- 总句对数量:2,450
- 异常句子数量:1,750
- 正确(负例)样本数量:700
- 错误类型:6种细粒度语义类别
- 平均长度:30个单词(包含59个长例句,长度为55-70个单词)
错误类型分类
| 类型 | 描述 | 示例 |
|---|---|---|
ont |
本体不兼容 | 测量希望、称量悲伤 |
role |
论元结构违反 | 校准忧郁、称量悲伤 |
agent |
错误施事 | 机器累了、书诞生了想法 |
causal |
虚假因果关系 | 焦虑引起了短路 |
met |
转喻转换 | 幸福的钥匙、服务器存储记忆 |
temp-spat |
时空悖论 | 小偷偷走了早晨、导航仪导向过去 |
ok |
语义有效句子 | — |
用途
- 二元分类:检测语义异常
- 细粒度分类:分类错误类型
- 文本校正:生成流畅的改写句子
- 大语言模型评估:测试俄语模型的语义推理能力
数据结构
每条记录包含:
id:唯一标识符incorrect:语义异常句子correct:流畅自然的校正句子error_type:错误类型(ont/role/agent/causal/met/temp-spat/ok)
数据示例
json { "id": 1007, "incorrect": "Поскольку надежда не поддаётся калибровке по международной системе единиц, инженер всё же попытался отрегулировать её с помощью микрометрического винта...", "correct": "Инженер знал, что надежду нельзя измерить приборами, но, регулируя параметры реактора с предельной точностью, он цеплялся за неё как за последний шанс...", "error_type": "role" }
搜集汇总
数据集介绍
构建方式
在语义异常检测研究领域,俄语语义异常数据集通过人工构建方式精心编制了2,450组对比句对。该数据集包含1,750个语义异常句子与700个正确例句,所有异常句均基于六类语言学理论手工设计,包括本体论冲突、论元结构错配、非生命体施事等典型语义偏差现象,每个异常句都配有经过语言学家验证的流畅修正版本。
特点
该数据集最显著的特征在于其系统性的语义错误分类体系,六种精细标注的错误类型覆盖了从词汇层面到句法语义接口的典型异常模式。数据规模达到千对级别,平均句长30词并包含59个长难句实例,既保证了数据多样性又兼顾了实际应用场景的复杂性。所有语料均采用自然语言生成,避免了机械替换产生的伪数据,为俄语语义理解研究提供了高质量的评估基准。
使用方法
研究者可基于该数据集开展三层级任务:通过对比句对实现语义异常的二元分类,利用细粒度错误标签进行多类别语义偏差识别,或将其作为序列生成任务的训练数据以开发文本自动修正系统。数据以标准JSON格式组织,每个样本包含原始异常句、修正句及错误类型标注,可直接接入现代自然语言处理 pipeline。该设计特别适用于评估俄语大语言模型在语义合理性判断与错误纠正方面的能力。
背景与挑战
背景概述
在自然语言处理领域,语义异常检测作为深层语言理解的关键任务,长期面临标注数据稀缺的挑战。俄罗斯语义异常数据集由语言学研究者于2023年构建,聚焦俄语语义逻辑违背现象的系统化标注。该数据集通过人工构造六类精细语义错误,包括本体论冲突、论元结构违例等语言学范畴,为俄语语义推理模型提供了首个专业评测基准,显著推动了斯拉夫语系语言的深层语义理解研究。
当前挑战
语义异常检测需解决抽象概念与具象谓词间逻辑冲突的识别难题,如‘测量希望’这类本体错配现象的建模。数据集构建过程中面临双重挑战:在语言学层面需保持错误类型的理论完备性,避免主观标注偏差;在工程层面需平衡语义违背的自然度与检测难度,特别是长距离依赖结构中隐喻性错误的构造。此外,俄语丰富的格变化系统与自由语序特性,进一步增加了语义角色标注的复杂性。
常用场景
经典使用场景
在自然语言处理领域,俄语语义异常数据集为语义错误检测与修正提供了关键资源。该数据集通过精心设计的对比句对,支持模型区分语义合理与异常表达,尤其适用于俄语语境下的语义一致性分析。研究者可基于其六类细粒度错误类型,系统评估模型对本体论冲突、角色错配等复杂语义现象的识别能力,为语义理解研究奠定数据基础。
实际应用
在现实应用层面,该数据集为俄语智能写作辅助系统提供了核心训练素材。教育科技领域可基于其构建语法检查工具,精准识别学生作文中的语义矛盾;内容创作平台则能利用该数据优化文本自动校对功能,提升俄语媒体内容的语义流畅度。此外,司法文书与医疗报告等专业文本的语义验证场景中,该数据集亦能有效防范因语义歧义引发的理解偏差。
衍生相关工作
该数据集已催生多项语义分析领域的创新研究。基于其构建的对比学习框架被广泛应用于俄语预训练模型的语义校准任务,衍生出如SemanticBERT-RU等专用模型。在跨语言迁移学习中,该数据集的错误分类体系为构建多语言语义异常知识图谱提供了范式参考,相关成果更推动了如语义对抗攻击检测、隐喻理解等前沿方向的方法创新。
以上内容由遇见数据集搜集并总结生成


