CUDABench-Set
收藏github2026-02-13 更新2026-02-14 收录
下载链接:
https://github.com/CUDA-Bench/CUDABench
下载链接
链接失效反馈官方服务:
资源简介:
CUDABench-Set是一个用于评估LLMs文本到CUDA代码生成能力的综合基准数据集。它包含了一系列独特的CUDA任务,每个任务都有详细的元数据、不同难度级别的提示和评估组件。
CUDABench-Set is a comprehensive benchmark dataset designed for evaluating the text-to-CUDA code generation capabilities of Large Language Models (LLMs). It encompasses a series of unique CUDA tasks, each equipped with detailed metadata, prompts of varying difficulty levels, and dedicated evaluation components.
创建时间:
2026-02-09
原始信息汇总
CUDABench 数据集概述
数据集简介
CUDABench 是一个综合性基准测试,旨在评估大语言模型的文本到CUDA代码生成能力。它提供了一个从数据集管理到CUDA代码生成,再到在NVIDIA GPU上进行自动化性能评估的完整流程。
数据集内容与结构
数据集的核心文件为 Datasets/CUDABench-Set.jsonl。该文件每一行是一个JSON对象,代表一个独立的CUDA编程任务。
任务关键字段
- 元数据:
id,task_name: 问题的唯一标识符。inputs/outputs: 张量形状和数据类型的定义。
- 提示词(难度分级):
level1_prompt: 引导式实现,提供任务名称、详细的算法描述以及明确的CUDA实现指南(例如,内存层次结构使用和线程映射策略)。level2_prompt: 算法规范,包含任务名称和算法描述,但省略所有硬件相关的指导。level3_prompt: 概念检索,仅提供任务名称。
- 评估组件:
bench.cu: 参考的CUDA C++实现代码。gen.py: 用于生成随机二进制输入数据和参考输出数据以供测试的Python脚本。compare.py: 用于验证生成的内核代码相对于参考实现正确性的Python脚本。
使用流程
1. 代码生成
使用 Generate 模块查询大语言模型以生成CUDA内核代码。
- 基本命令:
python Generate/main.py - 示例命令:
python Generate/main.py --api_option deepseek --model_name deepseek-reasoner --samples 3 - 输出:生成的代码将保存至
Results/<api_provider>/<model_name>_<level>_pass<k>.jsonl。
2. 评估
使用 Evaluate 模块对生成的代码进行编译、运行和性能分析,并与参考实现进行对比。
- 命令:
python Evaluate/manager.py full <path_to_results_file> - 示例:
python Evaluate/manager.py full Results/deepseek/deepseek-reasoner_level3_pass3.jsonl
运行前提
运行此基准测试前需确保安装以下工具:
- CUDA Toolkit (
nvcc): 用于编译生成的内核代码。 - NVIDIA Nsight Compute (
ncu): 用于性能指标分析。
相关资源
- Hugging Face数据集地址: https://huggingface.co/datasets/CUDABench/CUDABench-Set
- arXiv论文: https://arxiv.org/abs/(论文链接未在提供内容中给出完整地址)
搜集汇总
数据集介绍
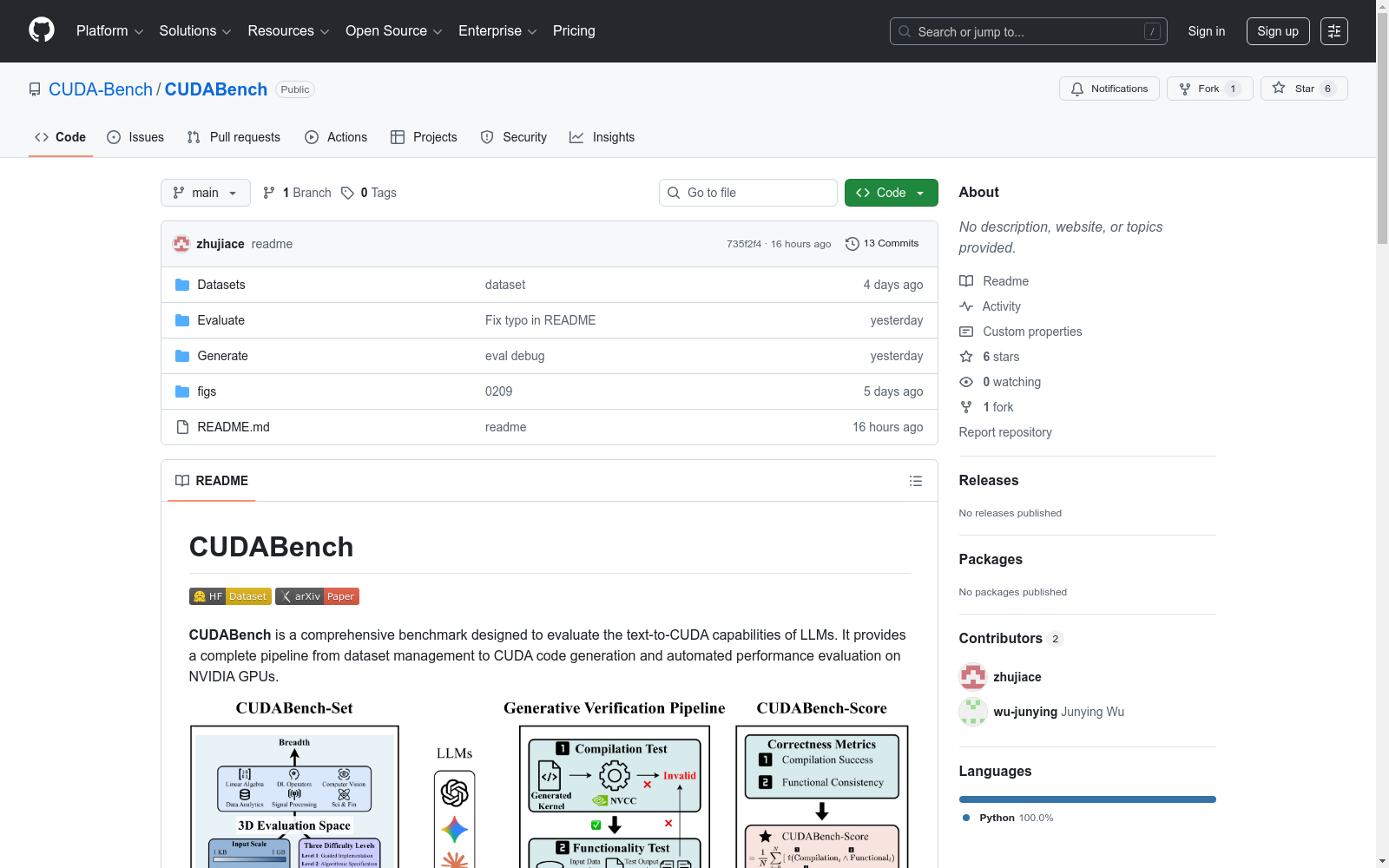
构建方式
CUDABench-Set数据集的构建遵循系统化工程原则,其核心任务以JSON行格式组织,每个条目代表一个独立的CUDA编程问题。数据集通过精心设计的三个难度层级提示词构建:第一层级提供详尽的算法描述与显式硬件实现指导;第二层级保留算法规范但省略硬件细节;第三层级仅给出任务名称以考察概念检索能力。每个任务均配备参考CUDA实现代码、数据生成脚本及结果验证工具,确保评估框架的完整性与可复现性。
特点
该数据集具备多层次评估体系,通过分级提示机制模拟从新手到专家的编程场景,有效衡量大语言模型在不同知识密度下的代码生成能力。其特色在于集成端到端的性能评测管道,不仅验证生成代码的功能正确性,更能通过NVIDIA专业工具链对内核执行效率进行量化分析。数据集覆盖典型GPU计算任务,张量形状与数据类型定义清晰,为模型在并行计算领域的推理能力提供标准化测试基准。
使用方法
使用该数据集需遵循标准化工作流:首先通过Generate模块调用大语言模型生成CUDA内核代码,支持DeepSeek、OpenAI等多种API接口,可配置采样次数与提示层级。随后利用Evaluate模块进行全流程评估,该模块自动调用nvcc编译器构建内核,通过Nsight Compute采集性能指标,并执行数据正确性验证。用户可通过命令行参数灵活控制评估粒度,生成结果将结构化存储于指定目录,便于横向对比不同模型的代码生成质量与运行效率。
背景与挑战
背景概述
随着大型语言模型在代码生成领域的广泛应用,评估其生成高性能并行计算代码的能力成为研究热点。CUDABench-Set数据集由相关研究团队于近期构建,旨在系统评估大模型在文本到CUDA代码生成任务上的表现。该数据集聚焦于GPU加速计算场景,通过提供多层次提示和完整评估流程,为核心研究问题——即大模型能否理解并实现复杂的并行算法与硬件优化——提供了标准化测试基准。其对高性能计算与人工智能交叉领域的影响力在于,推动了代码生成模型向专业化、实用化方向发展,为自动化并行编程工具的开发奠定了实证基础。
当前挑战
该数据集致力于解决文本到CUDA代码生成这一领域问题,其核心挑战在于要求模型不仅需理解算法语义,还需掌握GPU内存层次、线程映射等硬件特定优化知识,以生成正确且高效的内核代码。在构建过程中,挑战体现在设计涵盖不同难度层级的提示工程,确保任务多样性与代表性;同时,建立自动化编译、运行与性能分析的评估管道,需克服跨平台兼容性、结果可复现性以及准确度量生成代码性能与正确性的技术难题。
常用场景
经典使用场景
在异构计算与高性能计算领域,CUDABench-Set数据集被广泛用于评估大型语言模型在文本到CUDA代码生成任务中的能力。该数据集通过提供多难度级别的提示,模拟了从详细指导到概念性描述的编程场景,使研究者能够系统测试模型在理解算法逻辑、硬件架构映射及并行编程模式方面的表现。经典使用场景包括在学术实验中,利用该数据集生成CUDA内核代码,随后通过自动化编译与性能分析流程,量化模型生成代码的正确性、效率及可扩展性,为模型优化提供基准依据。
实际应用
在实际应用层面,CUDABench-Set数据集为工业界与科研机构的GPU编程工具开发提供了关键支持。它可用于训练和微调代码生成模型,辅助开发者在CUDA并行编程中快速原型化内核代码,降低手动编写高性能计算代码的复杂度。例如,在深度学习框架优化、科学计算加速或图形渲染引擎开发中,该数据集能帮助自动化生成经过验证的CUDA实现,提升开发效率并确保代码性能。此外,它还为编译器与编程语言设计提供了测试用例,推动工具链的智能化演进。
衍生相关工作
围绕CUDABench-Set数据集,已衍生出多项经典研究工作,主要集中在代码生成模型的评估与优化方向。例如,基于该数据集的基准测试被用于比较不同大型语言模型在CUDA代码生成任务上的性能,催生了针对硬件感知生成的模型架构改进。同时,研究者利用其多级提示设计,探索了指导性提示对生成代码质量的影响,进而提出了增强模型代码逻辑与并行化能力的训练策略。这些工作不仅深化了对文本到代码生成机制的理解,也为后续更广泛的编程语言生成基准树立了范例。
以上内容由遇见数据集搜集并总结生成


