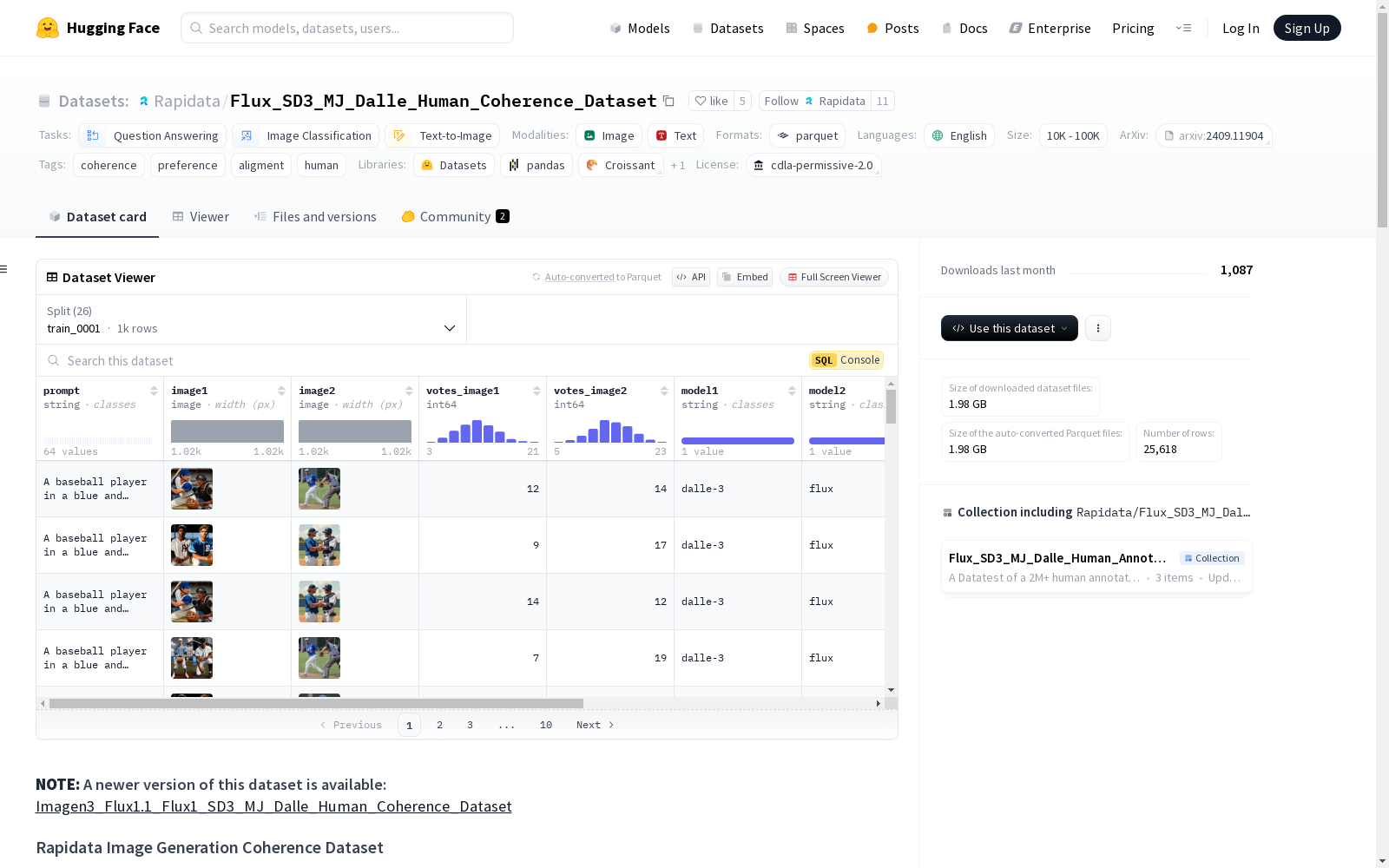
Flux_SD3_MJ_Dalle_Human_Coherence_Dataset
收藏Rapidata Image Generation Coherence Dataset
概述
该数据集是用于文本到图像模型的最大规模人类标注一致性数据集之一,包含超过700,000个人类投票,用于选择哪个生成的图像更一致。这是我们完整200万投票集合的三分之一。该偏好数据集是与领先的AI模型(包括Flux.1、DALL-E 3、MidJourney和Stable Diffusion)生成的图像进行比较的更大评估的一部分。完整的集合还包括两个同等规模的数据集,专注于图像偏好和文本-图像对齐,可在我们的个人资料中获取。该广泛的数据集在仅2天内使用Rapidata的创新标注技术收集,展示了在大规模人类反馈收集方面的前所未有的效率。
关键特征
- 大规模: 在48小时内收集了超过700,000个个人类偏好投票
- 全球代表性: 从145个国家的144,292名参与者中收集
- 多样化的提示: 282个精心策划的提示测试图像生成的各个方面
- 领先模型: 在四个最先进的图像生成模型之间进行比较
- 严格的方法论: 使用成对比较并内置质量控制
- 丰富的用户数据: 包括关于年龄、性别和地理位置的标注者信息
应用
该数据集对于以下方面非常有价值:
- 训练和微调图像生成模型
- 理解全球对AI生成图像的偏好
- 开发更好的生成模型评估指标
- 研究跨文化审美偏好
- 基准测试新的图像生成模型
数据收集由Rapidata提供支持
传统上需要数周或数月的数据收集工作在仅48小时内完成,这得益于Rapidata的创新标注平台。我们的技术支持:
- 大规模快速数据收集
- 全球覆盖145多个国家
- 内置质量保证机制
- 全面的代表性
- 成本效益高的大规模标注
引用
如果您在研究中使用此数据集,请引用我们的Startup Rapidata和我们的论文:"Finding the Subjective Truth: Collecting 2 Million Votes for Comprehensive Gen-AI Model Evaluation" (arXiv:2409.11904v2)
@misc{christodoulou2024findingsubjectivetruthcollecting, title={Finding the Subjective Truth: Collecting 2 Million Votes for Comprehensive Gen-AI Model Evaluation}, author={Dimitrios Christodoulou and Mads Kuhlmann-Jørgensen}, year={2024}, eprint={2409.11904}, archivePrefix={arXiv}, primaryClass={cs.CV}, url={https://arxiv.org/abs/2409.11904}, }