Signor_processed
收藏Hugging Face2026-02-05 更新2026-02-07 收录
下载链接:
https://huggingface.co/datasets/GleghornLab/Signor_processed
下载链接
链接失效反馈官方服务:
资源简介:
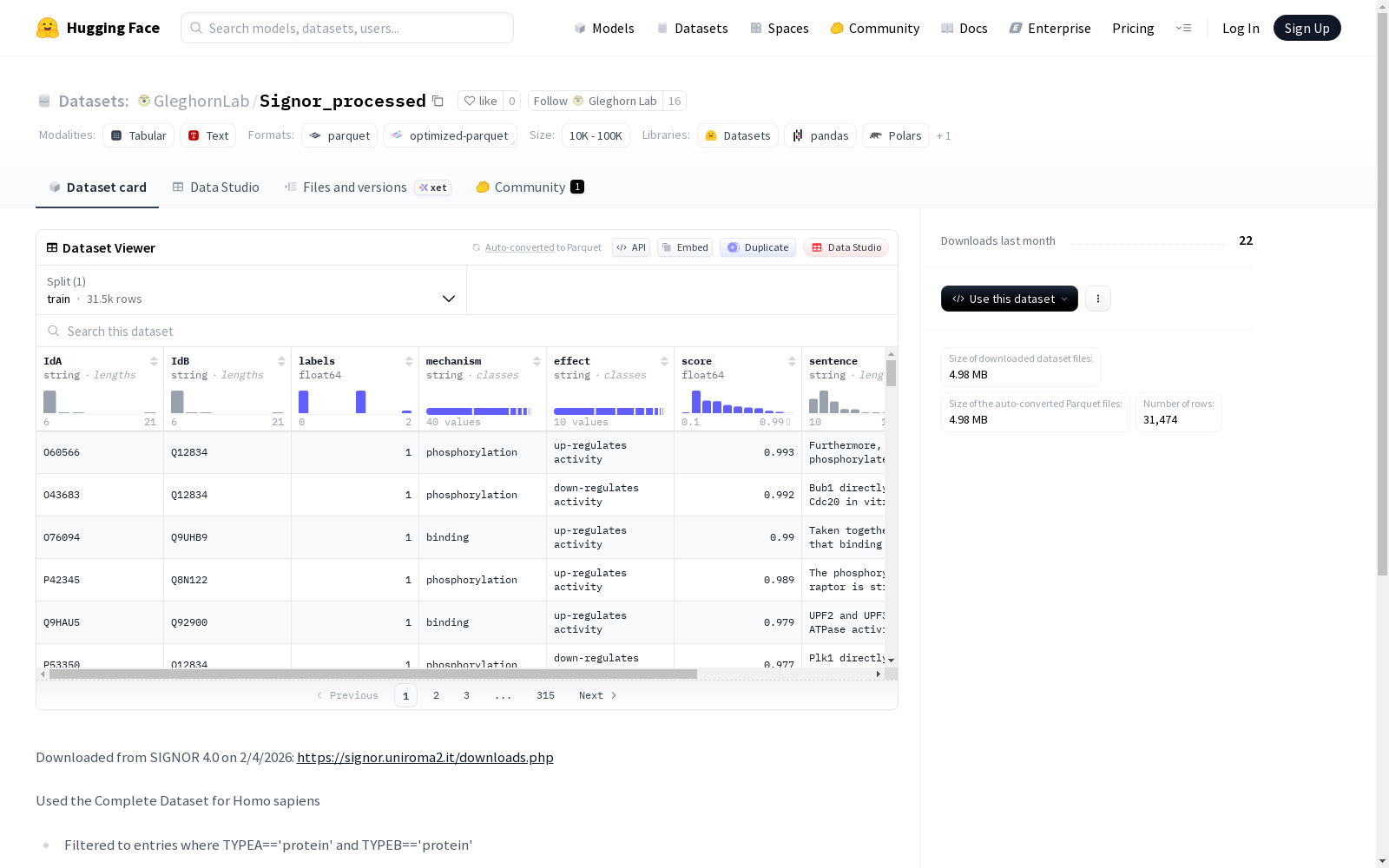
该数据集来源于SIGNOR 4.0数据库,包含人类(Homo sapiens)蛋白质-蛋白质相互作用数据。数据集经过严格筛选,仅保留TYPEA和TYPEB均为'protein'且DIRECT为'YES'的条目,排除了EFFECT为'uknown'或'form complex'的条目,并进行了去重处理。数据集包含以下特征字段:IdA(字符串)、IdB(字符串)、labels(浮点数)、mechanism(字符串)、effect(字符串)、score(浮点数)、sentence(字符串)和signor_id(字符串)。标签分配规则为:EFFECT为'binding'的条目及其反向条目标记为2,其余条目标记为1并添加其反向条目(标记为0)。数据集包含31,474个训练样本,总大小约12.8MB。适用于蛋白质相互作用预测和相关生物医学研究任务。
提供机构:
Gleghorn Lab
创建时间:
2026-02-05
搜集汇总
数据集介绍
构建方式
在生物信息学领域,蛋白质相互作用数据的系统化整理对于理解细胞信号传导至关重要。Signor_processed数据集基于SIGNOR 4.0数据库构建,专门针对智人(Homo sapiens)的完整数据集进行筛选。构建过程首先保留了类型为蛋白质的实体间直接相互作用条目,并剔除了效应未知或为“形成复合物”的记录。通过精选相关列并重命名,去除了重复数据后,依据相互作用的性质分配标签:将“结合”效应及其反向存在的条目标记为2,其余条目标记为1,并进一步通过反转这些条目的标识符生成标签为0的负样本对,从而构建了一个包含正负样本的平衡数据集。
特点
该数据集在信号传导研究领域展现出显著的结构化特征,其核心在于对蛋白质相互作用的多维度标注。每条记录不仅包含相互作用的蛋白质标识符(IdA与IdB),还详细描述了作用机制(mechanism)、效应(effect)及置信度评分(score),并附有支持该关系的原始句子(sentence)和SIGNOR唯一标识(signor_id)。标签系统经过精心设计,采用0、1、2三级分类,区分无相互作用、一般相互作用及特异性结合关系,这种细粒度标注为机器学习模型提供了丰富的监督信号。数据集规模适中,包含超过三万个训练样本,确保了数据的代表性与可用性。
使用方法
对于研究人员而言,该数据集可直接应用于蛋白质相互作用预测与关系分类任务。典型的使用流程是从HuggingFace平台加载数据集,利用其预定义的训练分割进行模型训练与评估。在机器学习实践中,可以结合IdA、IdB、sentence等文本特征,以及mechanism、effect等类别特征,构建多模态输入。标签字段(labels)作为监督目标,适用于分类或回归模型,以预测蛋白质对之间是否存在相互作用及其类型。此外,score字段可作为训练权重或模型置信度校准的参考,而signor_id便于追溯至原始数据库进行深入验证或扩展分析。
背景与挑战
背景概述
Signor_processed数据集源于SIGNOR 4.0数据库,该数据库由意大利罗马大学的研究团队于2026年构建,专注于系统生物学领域中的信号网络关系标注。该数据集的核心研究问题在于解析蛋白质间的相互作用机制与效应,特别是直接调控关系,为信号转导通路建模、药物靶点发现及疾病机制研究提供结构化知识支持。通过筛选人类蛋白质的直接作用条目,并清理未知效应与冗余数据,该数据集强化了生物医学计算中关系预测的可靠性,对网络药理学与系统生物学的发展产生了实质性推动。
当前挑战
该数据集旨在解决蛋白质相互作用预测中的机制与效应分类挑战,尤其在区分结合、激活、抑制等精细生物功能时面临语义模糊性与标注不一致性。构建过程中的挑战包括从原始SIGNOR数据库中过滤非蛋白质条目与间接关系,处理效应字段的缺失或歧义值,以及通过标签分配策略处理双向作用对的对称性问题,确保数据的一致性与可计算性。
常用场景
经典使用场景
在生物信息学领域,Signor_processed数据集为蛋白质相互作用研究提供了结构化资源。该数据集通过筛选人类蛋白质间的直接作用关系,并标注效应类型与置信度,常用于构建蛋白质信号网络模型。研究者利用其标注的激活、抑制或结合等效应,训练机器学习模型以预测未知的蛋白质相互作用,从而揭示细胞信号传导的复杂机制。
衍生相关工作
基于Signor_processed数据集,衍生了一系列经典研究工作。例如,研究人员开发了基于图神经网络的蛋白质相互作用预测模型,利用该数据集的标签进行训练与验证。此外,该数据集常被整合到多组学分析流程中,与基因表达、代谢数据结合,用于构建全细胞信号图谱,促进了系统生物学领域的模型开发与理论创新。
数据集最近研究
最新研究方向
在生物信息学领域,蛋白质相互作用网络的研究正日益深入,Signor_processed数据集作为SIGNOR数据库的衍生资源,聚焦于人类蛋白质间的直接调控关系。近期研究热点围绕利用该数据集训练深度学习模型,以预测蛋白质相互作用的机制与效应,特别是在药物发现和疾病机理解析中的应用。通过整合自然语言处理技术,从科学文献中提取结构化知识,该数据集支持了多任务学习框架的开发,增强了模型在生物医学文本挖掘中的泛化能力。其高质量标注为系统生物学提供了可靠基准,推动了精准医疗和靶向治疗的前沿探索,在人工智能驱动的生命科学研究中展现出重要价值。
以上内容由遇见数据集搜集并总结生成


