SeLeRoSa
收藏Hugging Face2025-06-18 更新2025-06-19 收录
下载链接:
https://huggingface.co/datasets/unstpb-nlp/SeLeRoSa
下载链接
链接失效反馈官方服务:
资源简介:
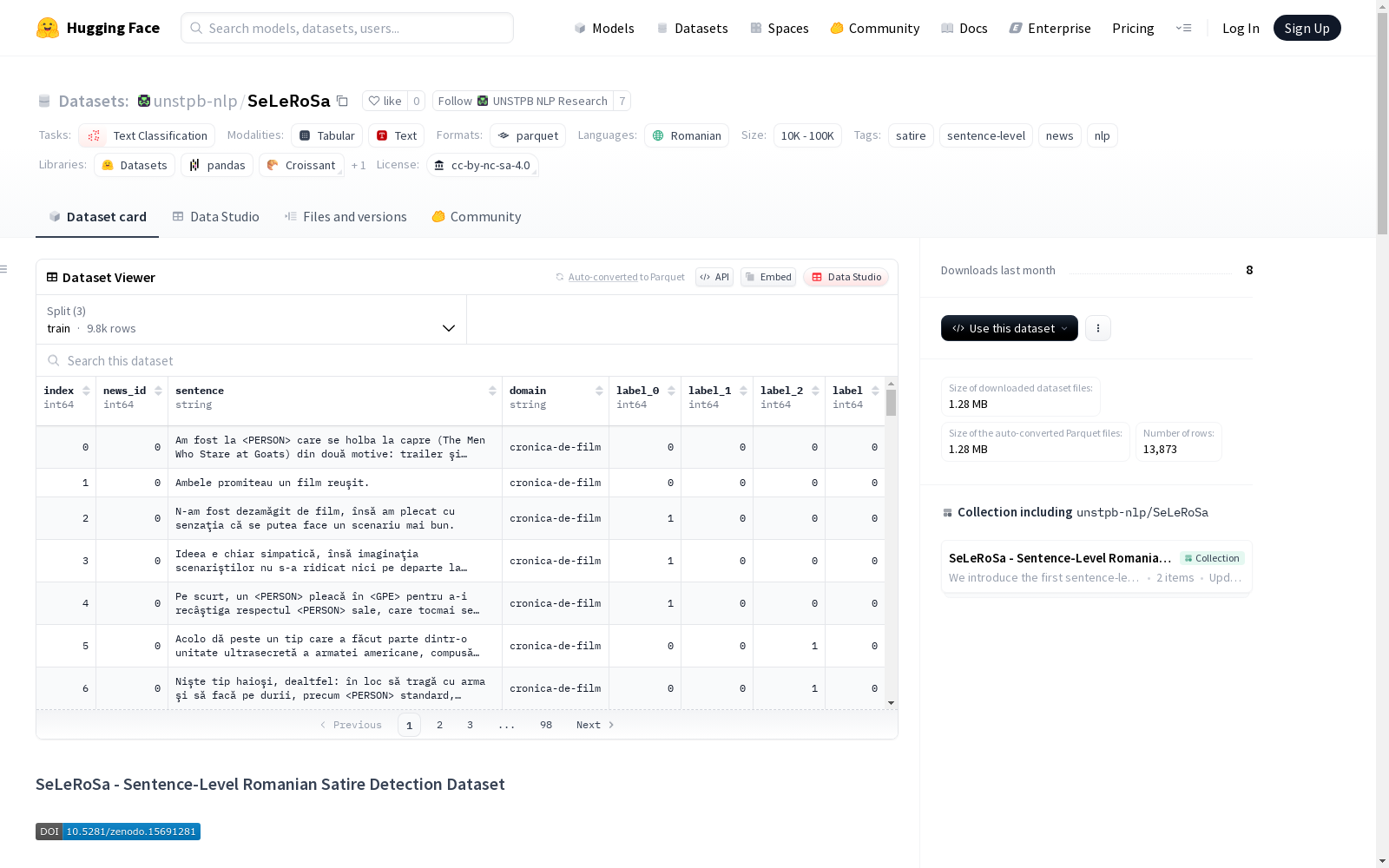
SeLeRoSa是一个罗马尼亚语新闻文章句级别讽刺检测数据集。该数据集包含13,873个跨越不同领域(如社会问题、IT、科学和电影)的手动注释句子。数据集通过使用Spacy替换命名实体和URLs进行了匿名化处理。数据集分为训练集、验证集和测试集,分别包含9800、2000和2073个样本。每个样本包括索引、新闻ID、句子、领域、三个注释者的标签以及通过多数投票聚合的标签。
创建时间:
2025-06-17
原始信息汇总
SeLeRoSa - Sentence-Level Romanian Satire Detection Dataset
数据集概述
- 名称: SeLeRoSa
- 任务类别: 文本分类
- 语言: 罗马尼亚语 (ro)
- 标签: 讽刺检测、句子级别、新闻、自然语言处理
- 许可证: CC-BY-NC-SA-4.0
- 数据规模: 10K<n<100K
数据集详情
-
特征:
index: 唯一标识符 (int64)news_id: 新闻源唯一标识符 (int64)sentence: 匿名化句子 (string)domain: 句子所属领域 (string)label_0: 第一位标注者的标签 (0-常规, 1-讽刺) (int64)label_1: 第二位标注者的标签 (int64)label_2: 第三位标注者的标签 (int64)label: 多数投票聚合标签 (int64)
-
领域分类:
life-deathit-stiintacronica-de-film
-
数据分割:
- 训练集: 9800 样本 (1,857,040 字节)
- 验证集: 2000 样本 (377,467 字节)
- 测试集: 2073 样本 (399,651 字节)
匿名化处理
- 使用 Spacy 替换命名实体:
- 人物 →
<PERSON> - 国家/宗教/政治团体 →
<NORP> - 地缘政治实体 →
<GPE> - 组织 →
<ORG> - 地点 →
<LOC> - 设施 →
<FAC>
- 人物 →
- URL 替换为
@URL标签
使用方式
python from datasets import load_dataset from torch.utils.data import DataLoader
dataset = load_dataset("unstpb-nlp/SeLeRoSa", split="train") dataloader = DataLoader(dataset)
相关资源
- 处理后的数据集: https://huggingface.co/datasets/unstpb-nlp/SeLeRoSa-proc
- 代码与实验: https://github.com/razvanalex-phd/SeLeRoSa
引用
bibtex @software{smadu_2025_15689794, author = {Smădu, Răzvan-Alexandru and Iuga, Andreea and Cercel, Dumitru-Clementin and Pop, Florin}, title = {SeLeRoSa - Sentence-Level Romanian Satire Detection Dataset}, year = 2025, publisher = {Zenodo}, doi = {10.5281/zenodo.15689794}, url = {https://doi.org/10.5281/zenodo.15689794} }
搜集汇总
数据集介绍
构建方式
在新闻文本分析领域,讽刺性内容的识别对于信息真实性验证具有重要意义。SeLeRoSa数据集通过系统化流程构建,研究人员从罗马尼亚语新闻文章中提取13,873个句子,涵盖社会议题、信息技术、科学和电影等多个领域。采用三重人工标注机制确保数据质量,每位标注者独立判断句子是否具有讽刺特征,最终通过多数表决机制确定标签。为保护隐私,使用Spacy工具对命名实体进行标准化替换,并手动过滤未识别的常见实体,形成匿名化文本语料。
使用方法
该数据集可通过Hugging Face生态便捷调用,使用者需预先安装datasets和torch依赖库。典型应用场景包含加载训练集至PyTorch数据加载器,实现端到端的模型训练流程。数据集中每个样本提供索引、新闻ID、匿名化句子文本、领域分类和三层标注等结构化字段,其中label字段作为经过多数表决的最终标签推荐用于模型训练。研究人员还可通过配置参数灵活选择训练、验证或测试分片,支持不同实验场景的需求。
背景与挑战
背景概述
SeLeRoSa数据集是首个针对罗马尼亚语新闻文章句子级讽刺检测任务构建的专用数据集,由Răzvan-Alexandru Smădu等研究者于2025年发布。该数据集包含13,873条跨社会议题、信息技术、科学和电影等多领域的手工标注句子,旨在解决虚假信息传播中更具隐蔽性的语言现象——通过句子级讽刺手法植入看似合理实则虚假的内容。作为自然语言处理领域的重要补充,该数据集填补了罗马尼亚语在细粒度讽刺分析方面的空白,并为大语言模型在低资源语言场景下的性能评估提供了基准平台。
当前挑战
该数据集面临双重挑战:在领域问题层面,句子级讽刺检测需克服上下文依赖性、语义模糊性以及文化特定性表达等自然语言理解难题,现有大语言模型在零样本场景下的表现仍存在显著局限;在构建过程中,匿名化处理要求精确平衡语义保留与隐私保护,需通过多阶段实体替换和人工校验确保数据质量,同时三标注者标注机制带来的分歧消弭也增加了标注复杂度。多领域文本的讽刺表达差异性进一步提高了标注一致性的维持难度。
常用场景
经典使用场景
在自然语言处理领域,讽刺检测一直是文本分类任务中的重要研究方向。SeLeRoSa作为首个罗马尼亚语句级别的讽刺检测数据集,为研究者提供了丰富的标注数据,广泛应用于讽刺识别模型的训练与评估。该数据集通过精细的句子级标注,使得模型能够捕捉讽刺表达在语法和语义上的微妙特征,为讽刺检测任务提供了可靠的数据支持。
解决学术问题
SeLeRoSa数据集解决了讽刺检测任务中数据稀缺的问题,尤其是在低资源语言罗马尼亚语中。通过提供多领域、多标注的句子级数据,该数据集为讽刺检测模型的开发和评估提供了标准化基准。此外,其匿名化处理确保了数据的隐私性,同时保留了讽刺表达的语义特征,为研究讽刺在新闻文本中的传播机制提供了重要工具。
实际应用
在实际应用中,SeLeRoSa数据集可用于新闻媒体平台的虚假信息过滤系统。通过识别新闻中的讽刺内容,平台能够更准确地标记潜在误导性信息,从而提升内容的可信度。此外,该数据集还可用于社交媒体监控,帮助识别和过滤讽刺性言论,维护健康的网络环境。
数据集最近研究
最新研究方向
在自然语言处理领域,讽刺检测作为文本情感分析的重要分支,近年来受到广泛关注。SeLeRoSa数据集作为首个罗马尼亚语句子级讽刺检测数据集,为低资源语言环境下的细粒度文本分析提供了宝贵资源。当前研究聚焦于探索大型语言模型在零样本和小样本场景下的性能表现,特别是针对跨语言迁移学习和领域自适应等前沿方向。该数据集的多标注特性为研究标注者间一致性及集成学习算法提供了实验基础,其多领域覆盖特性也推动了领域泛化技术在讽刺检测中的应用。随着虚假信息检测需求的增长,SeLeRoSa为开发更鲁棒的社交媒体内容审核系统提供了关键数据支持。
以上内容由遇见数据集搜集并总结生成


