SR-Prominence
收藏arXiv2026-05-14 更新2026-05-16 收录
下载链接:
https://huggingface.co/datasets/imolodetskikh/sr-artifact-prominence
下载链接
链接失效反馈官方服务:
资源简介:
SR-Prominence是由莫斯科国立大学团队构建的感知加权超分辨率伪影评估数据集套件,包含来自DeSRA、Open Images和Urban100的3935个伪影掩码。该数据集通过众包标注协议收集了15种主流超分辨率方法生成的伪影区域显著性标签,涵盖自然图像、结构化场景和高分辨率真实场景等多种数据来源。数据集采用自动掩码采集与预处理流程,通过形态学操作优化视觉评估效果,旨在解决传统二值伪影检测方法忽视人类感知差异的问题,为超分辨率模型的感知质量评估与伪影检测提供精细化基准。
SR-Prominence is a perception-weighted super-resolution artifact evaluation dataset suite developed by the team from Lomonosov Moscow State University, consisting of 3935 artifact masks sourced from DeSRA, Open Images, and Urban100. This dataset collects saliency labels for artifact regions generated by 15 mainstream super-resolution methods via crowdsourced annotation protocols, covering diverse data sources including natural images, structured scenes, and high-resolution real-world scenes. The dataset adopts an automatic mask collection and preprocessing pipeline, optimizes visual evaluation effects through morphological operations, and aims to address the limitation of traditional binary artifact detection methods that ignore human perceptual differences, providing a fine-grained benchmark for perceptual quality assessment and artifact detection of super-resolution models.
提供机构:
莫斯科国立大学·人工智能中心; 莫斯科国立大学; 因诺波利斯大学
创建时间:
2026-05-14
原始信息汇总
SR Artifact Prominence 数据集概述
数据集简介
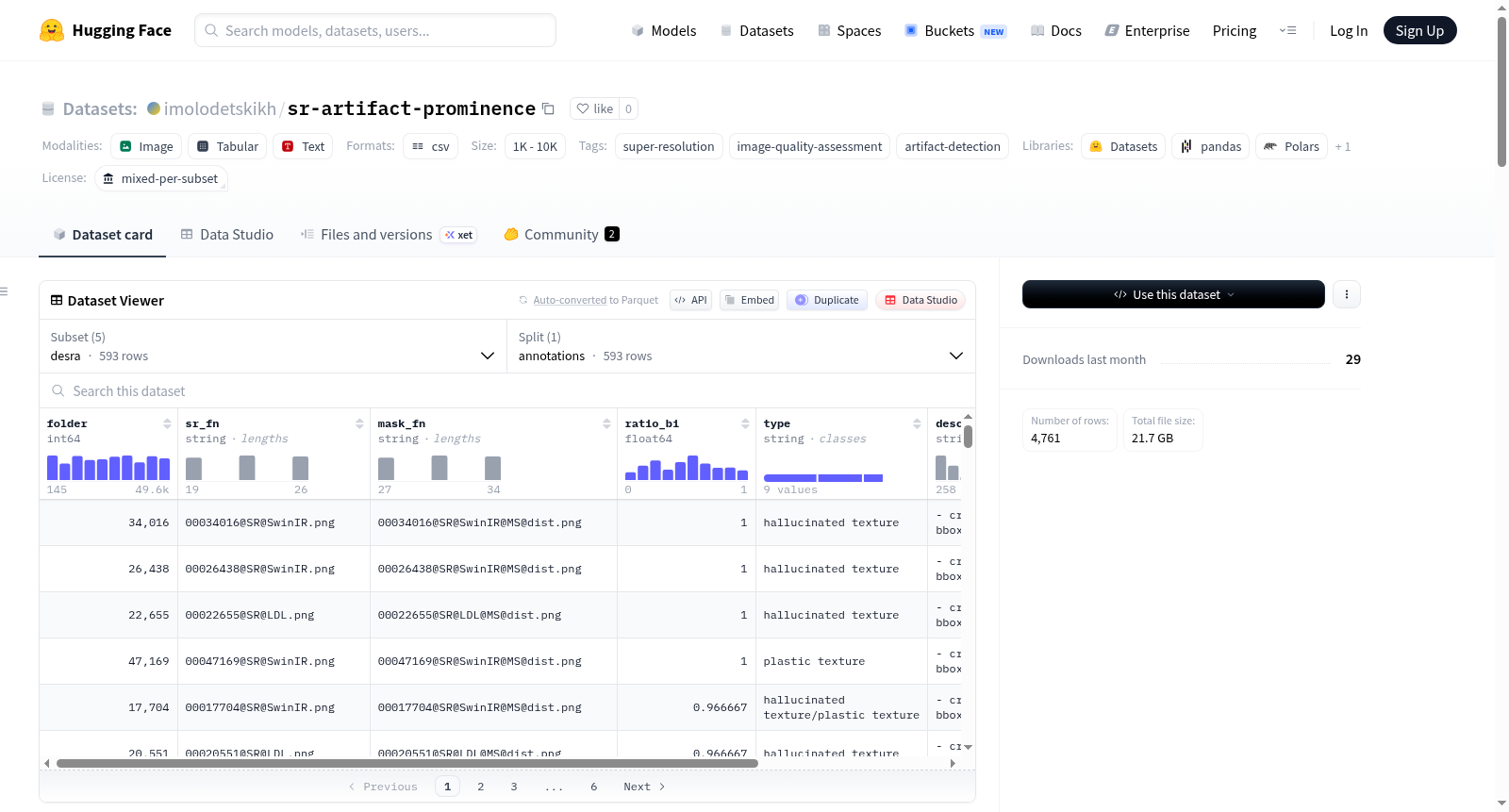
SR Artifact Prominence 是一个用于超分辨率图像伪影区域标注的数据集,包含四个图像子集的标注信息。每个标注区域都经过众包方式获得伪影显著性评分、伪影类型标签和自然语言描述。伪影显著性(Prominence)定义为有效标注工人中认为高亮区域存在明显超分辨率伪影的比例。
子集构成
| 子集 | 来源数据集 | 源图像数 | 标注掩码数 | 说明 |
|---|---|---|---|---|
| open_images | Open Images | 547 | 1,523 | 包含GT、LR-bicubic及多种SR变体 |
| open_images_uncurated | Open Images | 316 | 826 | open_images的子集,用于无对比评分 |
| urban100 | Urban100 | 68 | 873 | 包含GT、LR-bicubic及多种SR变体 |
| urban100_hr | Urban100 | 94 | 946 | 直接使用原始Urban100图像作为SR输入,无更高分辨率GT |
| desra | DeSRA数据集 | 528 | 593 | 仅包含标注,不提供图像 |
数据集结构
annotations/ {open_images,urban100,urban100_hr,desra}.csv images/ open_images/<folder>/<files> urban100/<folder>/<files> urban100_hr/<folder>/<files>
每个标注文件夹包含:
<folder>.png— 源/参考图像<folder>@LR@bicubic_x4.png— 双三次插值低分辨率输入(仅open_images和urban100)<folder>@SR@RLFN_x4.png— RLFN超分辨率输出(如有)- CSV中引用的所有
sr_fn和mask_fn文件
CSV列信息
folder,sr_fn,mask_fn— 图像标识符ratio_bi— 众包显著性分数(有效工人确认伪影的比例)dilated— 掩码预处理标志(形态学操作)type— 伪影类型标签(如“幻觉纹理”、“塑料纹理”)description— 伪影的自然语言描述semantic_categories,semantic_description— 场景内容标签status,semantic_status— 标注完成标志
DeSRA子集说明
DeSRA子集不重新分发图像。CSV中的文件名来源于DeSRA项目(文件来自ImageNet),需从DeSRA项目发布中获取图像后通过folder和sr_fn字段进行关联。
热力图与可复现性
heatmaps/<subset>/<gt_dir>/<method>/<sr_stem>.npy.gz 包含逐像素的伪影显著性热力图。每个热力图是gzip压缩的2D NumPy数组,与sr_fn指定的SR图像对齐。
参考图像对应关系:
- open_images:
gt_RLFN_x4(RLFN伪GT) - urban100:
gt_GT(高分辨率GT)
提供的方法包括:bd_jup、dists、desra、nn-20250421-gtgt-e30。
许可协议
- 所有标注(CSV文件):CC-BY 4.0
- open_images图像:CC-BY 2.0(继承自Open Images)
- urban100和urban100_hr图像:CC(继承自Urban100)
- desra图像:不重新分发,受ImageNet使用条款约束(非商业研究和教育用途)
搜集汇总
数据集介绍
构建方式
SR-Prominence数据集由四个子集构成:Prominence-DeSRA、Prominence-OpenImages、Prominence-Urban100和Prominence-Urban100-HR。首先,对于DeSRA子集,研究者直接收集了DeSRA数据集中所有593个二元伪影掩模的显著性标注。对于其余三个子集,采用全自动掩模收集流程:对超分辨率结果和参考图像运行现有伪影检测与图像质量评估方法以获取热力图,随后使用固定阈值生成候选伪影掩模,每个指标每张超分辨率图像选取10个最强伪影。掩模经过形态学预处理后,通过众包平台由30名评估者标注显著性。整个套件覆盖15种超分辨率方法的3935个伪影掩模。
特点
SR-Prominence的核心创新在于引入“伪影显著性”这一感知加权评估维度,定义为认为某区域包含明显伪影的观看者比例,突破了传统二元标签的局限。数据集呈现多层次结构:DeSRA子集揭示48.2%的实验室二元伪影未被多数观众察觉;OpenImages涵盖多样化自然场景;Urban100聚焦结构化内容如文本和规则图案;Urban100-HR则模拟无高分辨率参考的真实应用场景。标注采用质量控制流程,包括训练问题与随机控制题。基线检测方法融合DISTS、局部残差方差和块级失真特征,表现优于诸多专业检测器。
使用方法
数据集提供两种使用模式。基准测试中,评估者运行检测方法生成热力图,按固定阈值提取候选掩模,并与人工显著性标注对比,计算平均显著性与置信掩模数量。免阈值评分协议计算掩模内外部热力值中位数之差与标注显著性的斯皮尔曼相关系数,无需额外众包。伪高分辨率参考协议使用轻量级超分辨率方法(如RLFN)生成参考,使全参考指标可在无真实高分辨率图像的场景中应用。研究者可通过Hugging Face平台获取数据与基线模型。
背景与挑战
背景概述
超分辨率(SR)技术在近年来取得了长足进展,从基于CNN的模型到Diffusion与Transformer架构,生成的图像在感知质量上日益精进。然而,伴随这一进步而来的是日益突出的伪影问题——包括不自然的纹理、扭曲的结构以及异样的图案,这些瑕疵严重削弱了最终输出的视觉可信度。在此背景下,2025年由莫斯科国立大学AI中心的研究团队(Ivan Molodetskikh、Kirill Malyshev、Mark Mirgaleev等)创建了SR-Prominence数据集。该研究的核心问题在于:传统方法将伪影简单二分为“存在”或“不存在”,忽略了不同伪影在视觉显著性上的巨大差异。SR-Prominence通过众包协议定义了“伪影显著性”这一评价目标,量化了观众对伪影的觉察比例,填补了超分辨率领域中分级语义评价的关键空白。该数据集包含3,935个伪影掩码,覆盖DeSRA、Open Images、Urban100及其无高清参考的Urban100-HR四个子集,对超分辨率质量评估、伪影检测及模型测评领域产生了深远影响。
当前挑战
超分辨率伪影评价面临的核心挑战在于:现有检测和评价方法大多以二值形式(有无伪影)标记缺陷,而实际中,不同伪影的视觉干扰程度差异悬殊——例如,建筑物上的扭曲文字与水面上的轻微纹理错误,虽同属伪影类别,但前者极易引起观众注意,后者几乎不可察觉。SR-Prominence针对此问题提出“显著性”作为衡量伪影感知影响的分级指标,其挑战体现在两方面:其一,领域难题在于如何在模型评价体系中引入对伪影视觉关注度的量化,以便区分高干扰与低干扰缺陷,避免检测模型过度拟合低影响伪影而忽略真正令人反感的瑕疵;其二,构建过程中面临众包标注稳定性与效率的权衡——为了获得可靠的显著性分数,需综合大量观测者判断,但过多参与者会导致成本激增,而太少则置信区间过大(仅30名评估者时的置信区间约为±20%),同时还需通过训练与质控问题过滤不可靠答卷,以保障标注质量。
常用场景
经典使用场景
在图像超分辨率领域,SR-Prominence数据集被广泛用于评估超分辨率方法生成伪影的感知显著性。研究者利用该数据集对各类超分辨率模型——包括基于CNN、Transformer以及扩散模型的算法——进行横评,聚焦于伪影是否被多数观察者察觉。其经典用法是替代传统的二值伪影判定,转而采用人群标注的显著性分数作为评价标准,从而更精准地反映伪影对视觉体验的真实损害。该数据集覆盖了自然图像、结构化城市场景以及无真实高分辨率参考的真实环境,为模型在不同场景下的伪影表现提供了全面测试平台。
实际应用
SR-Prominence的实际应用聚焦于超分辨率系统的质量监控与模型优化。在工业界,图像增强服务需要确保输出的视觉真实性,该数据集提供了一套无需重复人群标注的评分协议,使得工程师能够快速评估新方法在用户端产生可见伪影的风险。同时,数据集支持伪真实参考流程,可在无高分辨率真值的实际部署场景中应用全参考指标,帮助调优模型参数或选择伪影更少的推理模型。例如,在移动端影像增强、卫星图像复原等任务中,SR-Prominence被用来筛选和验证低伪影生成方案,提升产品在用户视觉体验上的稳定性。
衍生相关工作
围绕SR-Prominence数据集衍生了一系列重要工作,推动了伪影检测与感知评价的融合。其中,基于该数据集的基准评测揭示了全参考指标(如SSIM和DISTS)在局部显著性预测上的优势,催生了将结构相似性与纹理畸变感知相结合的融合检测方法。研究者还设计了一个基于多层感知机的轻量级显著性基线,整合块级DISTS、局部残差方差等特征,在不同子集上取得一致优势。此外,该数据集启发了对伪影类型和语义上下文的深入研究,如利用视觉语言模型分析伪影在文字、城市场景与自然景物中的差异性,为后续开发语义感知的伪影抑制算法铺设了实验基础。
以上内容由遇见数据集搜集并总结生成


