generate-readme-eval
收藏Hugging Face2024-09-12 更新2024-12-12 收录
下载链接:
https://huggingface.co/datasets/patched-codes/generate-readme-eval
下载链接
链接失效反馈官方服务:
资源简介:
generate-readme-eval数据集用于评估大型语言模型在总结GitHub仓库并生成README.md文件时的有效性。数据集包含训练集和测试集,分别用于微调和性能评估。数据集从GitHub上选取了400个至少有1000颗星和100个分叉的Python仓库,并限制仓库大小不超过100k个token。评估时,模型被要求根据仓库内容生成README.md文件,并通过多种指标来评估生成的README文件的质量。
The generate-readme-eval dataset is designed to evaluate the effectiveness of large language models (LLMs) when summarizing GitHub repositories and generating README.md files. The dataset comprises a training set and a test set, which are utilized for fine-tuning and performance evaluation, respectively. It includes 400 Python repositories selected from GitHub, each with at least 1000 stars and 100 forks, and the repository size is constrained to no more than 100k tokens. During the evaluation process, models are tasked with generating README.md files based on the content of the corresponding repositories, and the quality of the generated README files is assessed via multiple metrics.
创建时间:
2024-09-12
原始信息汇总
Generate README Eval 数据集概述
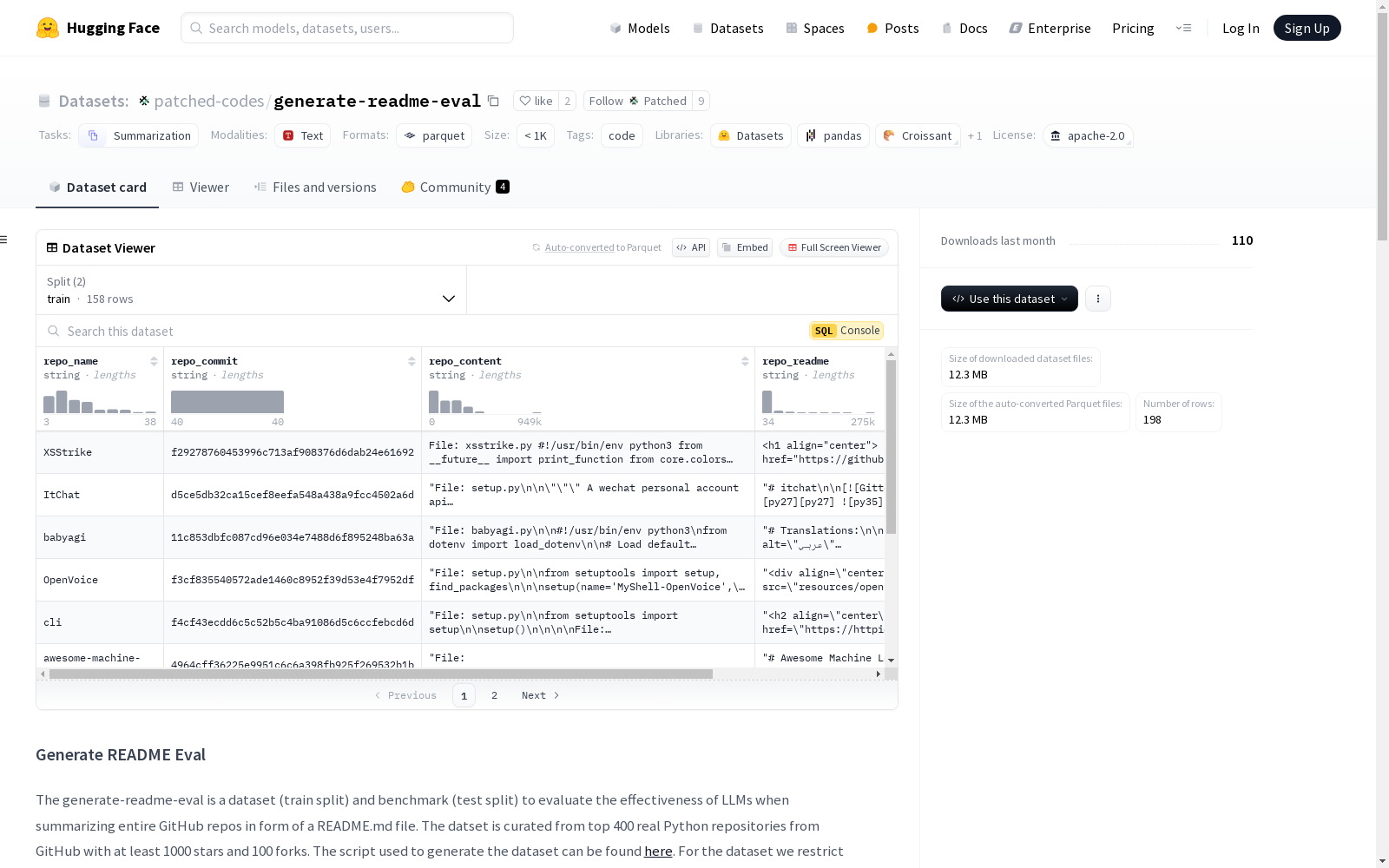
数据集信息
- 特征:
repo_name: 仓库名称,类型为字符串。repo_commit: 仓库提交信息,类型为字符串。repo_content: 仓库内容,类型为字符串。repo_readme: 仓库的README文件内容,类型为字符串。
- 分割:
train: 训练集,包含158个样本,大小为29227644字节。test: 测试集,包含40个样本,大小为8765331字节。
- 下载大小: 12307532字节
- 数据集大小: 37992975字节
- 配置:
default: 数据文件路径包括data/train-*和data/test-*。
- 许可证: Apache 2.0
- 任务类别: 摘要生成
- 标签: 代码
- 大小类别: n<1K
数据集描述
- 来源: 从GitHub上选取的400个Python仓库,每个仓库至少有1000颗星和100个分支。
- 限制: 仅包含大小小于100k tokens的仓库。
- 用途: 用于评估大型语言模型(LLMs)生成README.md文件的效果。
评估方法
-
评估脚本: 使用提供的脚本进行评估,脚本路径为
_script_for_eval.py。 -
评估指标: 包括BLEU、ROUGE、余弦相似度、结构相似度、信息检索、代码一致性和可读性(FRES)。
-
最终评分: 通过加权平均计算,权重如下: python weights = { bleu: 0.1, rouge-1: 0.033, rouge-2: 0.033, rouge-l: 0.034, cosine_similarity: 0.1, structural_similarity: 0.1, information_retrieval: 0.2, code_consistency: 0.2, readability: 0.2 }
-
评估结果: 评估脚本会输出各项指标并存储日志文件。
排行榜
- 当前SOTA模型: Gemini-1.5-Flash-Exp-0827,在零样本设置下表现最佳。
- 模型评分:
bleu: 0.0072rouge-1: 0.1196rouge-2: 0.0169rouge-l: 0.1151cosine_similarity: 0.3029structural_similarity: 0.2416information_retrieval: 0.4450code_consistency: 0.0796readability: 0.3790weighted_score: 0.2443
少样本学习
- 挑战: 由于上下文长度限制和准确性权衡,少样本学习难以显著提升性能。
- 实验结果: 1-shot效果最佳,增加样本数量后性能不再提升。
搜集汇总
数据集介绍
构建方式
generate-readme-eval 数据集通过精选 GitHub 上拥有至少 1000 星标和 100 次分叉的 400 个顶级 Python 仓库构建而成。为确保数据集适用于大型语言模型(LLM)的上下文限制,所有仓库的代码量均控制在 10 万 tokens 以内。数据集的训练集部分可用于模型微调,而测试集则用于评估模型生成 README.md 文件的能力。数据生成脚本公开透明,确保了数据集的可靠性和可复现性。
特点
该数据集的核心特点在于其专注于评估 LLM 在生成 GitHub 仓库 README.md 文件时的表现。数据集不仅包含传统的自然语言处理指标(如 BLEU 和 ROUGE),还引入了结构相似性、代码一致性、可读性和信息检索等定制化评估指标。这些指标通过加权平均计算最终得分,全面衡量模型生成内容的准确性和实用性。此外,数据集还提供了基准测试的 Oracle 分数,为模型性能提供了明确的参考标准。
使用方法
使用 generate-readme-eval 数据集时,用户可通过提供的评估脚本对模型进行测试。评估过程中,模型需根据仓库的全部内容生成结构化的 README.md 文件,并与实际 README 文件进行多维度对比。评估结果包括各项指标的详细得分及最终加权分数,并自动生成日志文件。用户可通过提交日志文件参与公开排行榜,展示模型性能。此外,数据集支持 few-shot 实验,但需注意上下文长度和指标间的权衡关系。
背景与挑战
背景概述
generate-readme-eval数据集旨在评估大型语言模型(LLMs)在生成GitHub仓库README.md文件时的表现。该数据集由GitHub上400个最受欢迎的Python仓库构建而成,这些仓库至少拥有1000颗星和100个分支。数据集创建于2024年,主要研究人员通过限制仓库大小在100k tokens以内,以确保整个仓库内容能够一次性输入到LLM的上下文中。该数据集不仅为模型微调提供了训练集,还为评估模型性能提供了测试集。其核心研究问题在于如何通过LLM生成结构化的README文件,并评估其与真实README文件在多个指标上的相似性。该数据集对代码摘要和信息检索领域的研究具有重要意义。
当前挑战
generate-readme-eval数据集面临的主要挑战包括两个方面。首先,在解决领域问题上,生成高质量的README文件需要模型具备强大的上下文理解能力和信息提取能力,尤其是在处理复杂代码库时,模型需要准确捕捉代码与文档之间的关联性。其次,在数据集构建过程中,研究人员面临如何平衡仓库规模与模型上下文限制的挑战。尽管限制仓库大小在100k tokens以内有助于模型处理,但这也可能导致部分大型仓库的信息丢失。此外,评估过程中如何设计合理的指标(如结构相似性、代码一致性、可读性等)以全面衡量生成README的质量,也是一个重要的技术难题。
常用场景
经典使用场景
在自然语言处理领域,generate-readme-eval数据集被广泛用于评估大型语言模型(LLMs)在生成GitHub仓库README文件时的表现。通过将整个仓库的内容输入模型,并要求其生成结构化的README文件,研究人员能够深入分析模型在代码总结和信息提取方面的能力。该数据集特别适用于研究模型在处理长上下文时的表现,尤其是在代码库的复杂性和多样性背景下。
实际应用
在实际应用中,generate-readme-eval数据集为开发者和技术团队提供了强大的工具,用于自动化生成高质量的README文件。通过利用该数据集训练的模型,开发者能够快速生成与代码库内容高度一致的文档,减少手动编写文档的时间成本。此外,该数据集还可用于优化代码库的可读性和可维护性,帮助开源社区提升项目的整体质量。
衍生相关工作
generate-readme-eval数据集催生了一系列相关研究工作,特别是在技术文档生成和代码总结领域。例如,基于该数据集的研究推动了模型在长上下文处理能力的提升,如Google Gemini模型的优化。此外,该数据集还启发了对多模态文档生成的研究,结合代码和自然语言生成更丰富的技术文档。这些工作不仅扩展了数据集的应用范围,也为未来的技术文档自动化生成提供了新的研究方向。
以上内容由遇见数据集搜集并总结生成


