Dz-Emotion
收藏Dz-Emotion 数据集概述
数据集基本信息
- 数据集名称:Dz-Emotion
- 语言:阿拉伯语 (Algerian Arabic dialect/Darija)
- 许可证:cc-by-4.0
- 任务类别:文本分类
- 任务ID:多类别分类
- 多语言性:单语
- 规模类别:1K<n<10K
- 标签:arabic, algerian-arabic, emotion-classification, nlp
数据集描述
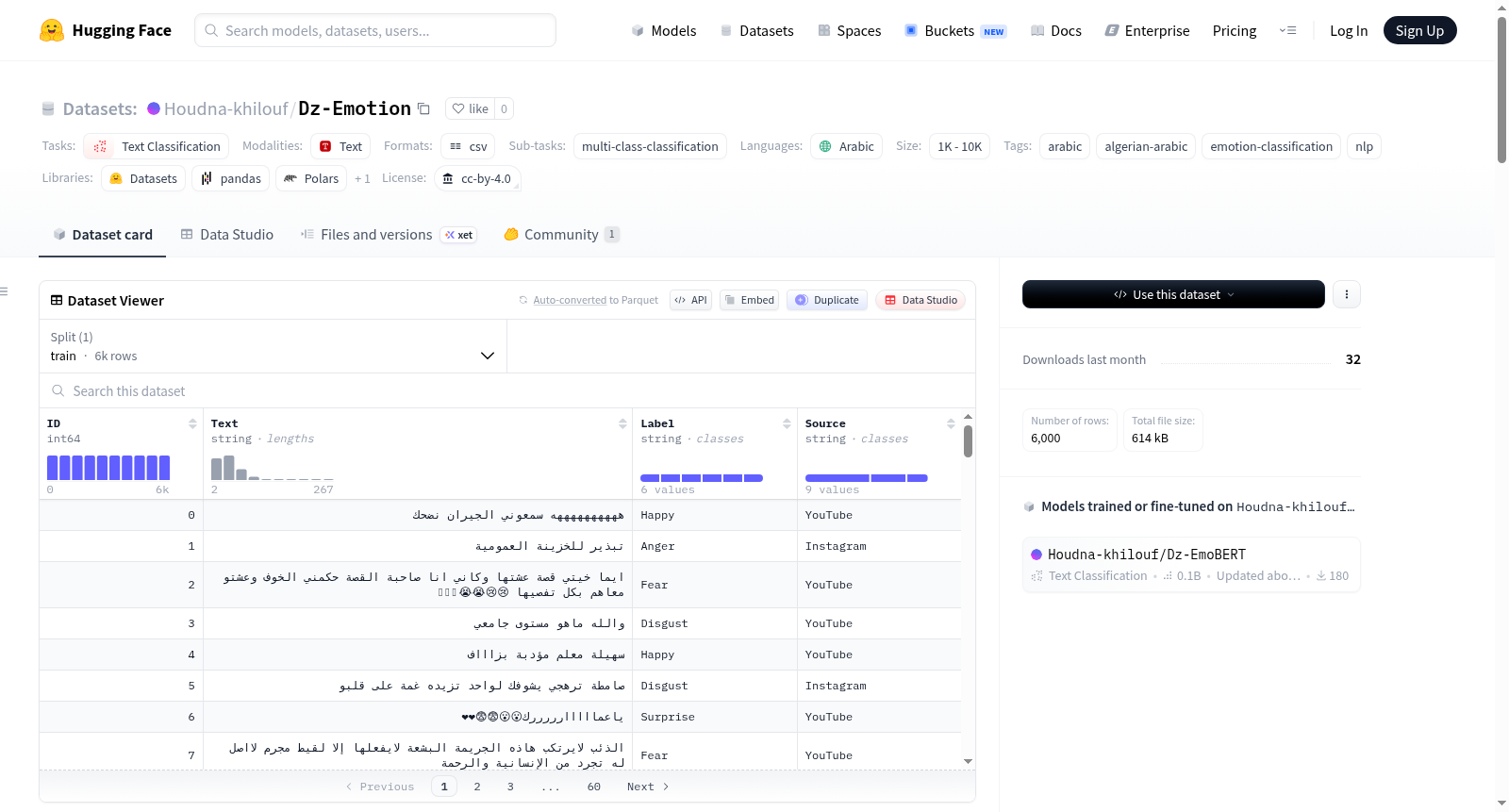
Dz-Emotion 是首个用于阿尔及利亚阿拉伯方言情感检测的大规模人工标注数据集。该数据集包含6,000条社交媒体评论,收集自YouTube、Facebook和Instagram,并根据Ekman的六种基本情绪进行标注:愤怒、悲伤、恐惧、厌恶、快乐、惊讶。该数据集旨在支持针对低资源方言(尤其是阿尔及利亚阿拉伯语)的自然语言处理研究。
相关论文
更多信息请访问论文:https://ieeexplore.ieee.org/document/11472633
相关模型
该数据集用于训练模型:Dz-EmoBERT (https://huggingface.co/Houdna-khilouf/Dz-EmoBERT)。Dz-EmoBERT 是一个针对阿尔及利亚方言文本情感检测进行微调的Transformer模型,在该数据集上达到了94.08%的准确率。
数据结构
数据集以CSV文件格式提供,包含以下列:
- ID:每条评论的唯一标识符
- Text:评论文本(阿尔及利亚方言)
- Label:情感标签
- Source:平台来源 (YouTube, Facebook, Instagram)
数据统计
- 总样本数:6,000
- 类别数:6种情绪
- 每类样本数:1,000 (平衡)
情绪分布
- 愤怒:1000
- 悲伤:1000
- 恐惧:1000
- 厌恶:1000
- 快乐:1000
- 惊讶:1000
数据来源分布
- YouTube:53%
- Instagram:29%
- Facebook:18%
训练/测试划分
- 训练集:80% (4,800个样本)
- 验证集:20% (1,200个样本)
基线结果
该数据集用于微调多个模型,结果如下:
- ARBERT:86.00%
- MARBERT:91.67%
- Dz-EmoBERT:94.08%
局限性
- 从社交媒体收集的数据可能包含噪声和偏见
- 仅关注六种情绪(Ekman模型)
- 仅限于阿尔及利亚方言
联系方式
如有问题或合作机会,请联系:h.khilouf@univ-eltarf.dz
引用
若使用本数据集,请引用: bibtex @inproceedings{khilouf2025dzemotion, title={Dz-Emotion: An Algerian Dialect Dataset for Text-Based Emotion Detection}, author={Khilouf, Houdna and Ziani, Amel and Malek, Nada Ahmed and Schwab, Didier and Yakoubi, Mohamed Amine}, booktitle={2025 International Conference on Recent Advances in Mathematics and Informatics (ICRAMI)}, pages={1--6}, year={2025}, address={Sousse, Tunisia}, doi={10.1109/ICRAMI64946.2025.11472633} }