Nemotron-Personas-Brazil
收藏Hugging Face2026-01-27 更新2026-01-28 收录
下载链接:
https://huggingface.co/datasets/nvidia/Nemotron-Personas-Brazil
下载链接
链接失效反馈官方服务:
资源简介:
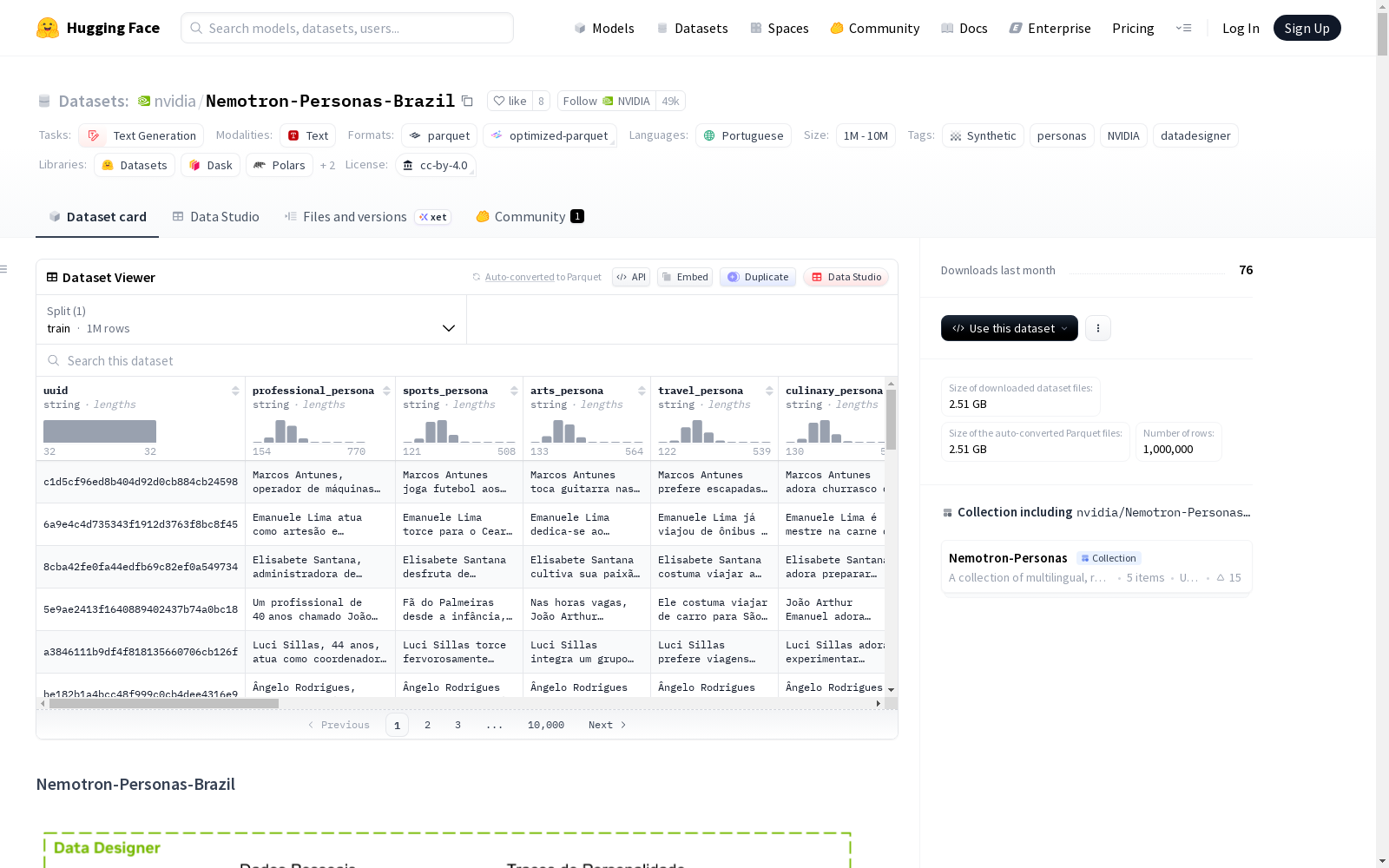
Nemotron-Personas-Brazil 是一个开源(CC BY 4.0)数据集,包含基于巴西真实世界人口统计、地理和人格特质分布生成的合成人物角色,旨在捕捉巴西人口的多样性和丰富性。该数据集是 Nemotron-Personas-USA 的变体,首次在名字、性别、年龄、背景、婚姻状况、教育、职业和位置等属性上与统计数据对齐。数据集由 NVIDIA 与 WideLabs 合作开发,为葡萄牙语的多种建模用例提供高质量人物角色。
数据集包含 100 万条葡萄牙语记录,每条记录包含 6 个人物角色,总计 600 万个人物角色。包含 20 个字段:6 个人物角色字段和 14 个基于官方人口统计和劳动统计的上下文字段。数据集通过反映巴西真实的地理和人口统计分布,提高了合成生成数据的多样性,减轻了偏见,并防止模型崩溃。
数据集使用 NeMo Data Designer 生成,这是一个企业级复合 AI 系统,用于合成数据生成。数据集利用专有的概率图模型(PGM)和 Apache-2.0 许可的 GPT-OSS-120B 模型,以及内置在 Data Designer 中的不断扩展的验证器和评估器集。
数据集适用于商业用途,旨在支持主权 AI 开发,通过解决当前模型训练数据中缺失的数据和潜在偏见,特别是在用于合成数据生成的现有角色数据集中。数据集仅关注成年人。
提供机构:
NVIDIA
创建时间:
2026-01-26
原始信息汇总
Nemotron-Personas-Brazil 数据集概述
基本信息
- 数据集名称:Nemotron-Personas-Brazil
- 发布者:WideLabs & NVIDIA Corporation
- 发布日期:2026年1月26日
- 数据版本:1.0 (01/26/2026)
- 许可证:Creative Commons Attribution 4.0 International License (CC-BY-4.0)
- 语言:葡萄牙语 (pt)
- 任务类别:文本生成 (text-generation)
- 标签:synthetic, personas, NVIDIA, datadesigner
- 数据规模:1M<n<10M
- 下载大小:2514627068 字节
- 数据集大小:5395470286 字节
- 是否商用:是
数据集内容
- 记录数量:1,000,000 条记录(训练集)
- 总人物角色数:每条记录包含6个人物角色,总计6,000,000个角色
- 总标记数:约14亿个标记,其中约4.5亿个为人物角色标记
- 唯一姓名数:约457,000个
- 数据格式:包含20个字段的结构化数据
数据字段
数据集包含20个字段,分为6个人物角色字段和14个上下文字段。
人物角色字段
professional_persona:专业角色,描述主要工作领域、技能、特质和行为sports_persona:体育角色,描述运动兴趣、团队归属感以及健身和锻炼方式arts_persona:艺术角色,描述与创造性表达的互动以及艺术如何塑造其身份travel_persona:旅行角色,描述旅行兴趣和风格culinary_persona:烹饪角色,描述饮食偏好、技能水平及用餐体验方式persona:通用角色,简要概括个人生活观的核心
上下文字段
uuid:全局唯一标识符cultural_background:个人文化背景描述skills_and_expertise:叙事格式的专业和个人技能与专长hobbies_and_interests:叙事格式的个人兴趣和娱乐活动skills_and_expertise_list:技能和专业领域列表hobbies_and_interests_list:个人爱好和兴趣列表career_goals_and_ambitions:职业抱负和长期职业目标sex:生物性别(如:男性、女性)age:年龄(岁)marital_status:婚姻状况(如:已婚、单身、离异、丧偶)education_level:最高学历occupation:详细职业municipality:具体城市state:巴西州(联邦单位)country:居住国家
数据集特点
- 数据性质:完全人工生成的合成数据
- 地理覆盖:覆盖巴西所有27个联邦单位,锚定在具体的市和州
- 人口统计对齐:年龄、性别、婚姻状况和教育水平等关键变量反映了巴西当前的人口结构变化
- 职业框架:专业数据与巴西职业分类(CBO)的主要组别严格对齐
- 命名规范:采用巴西地理与统计研究所(IBGE)的命名门户数据,包含超过60,000个独特名字和160,000个姓氏
- 目标人群:仅关注成年人
数据来源与生成
- 基础数据:基于巴西地理与统计研究所(IBGE/SIDRA)发布的人口普查和劳动力数据
- 生成工具:使用NeMo Data Designer(企业级复合AI系统)生成,结合了专有的概率图模型(PGM)和Apache-2.0许可的GPT-OSS-120B模型
- 协作方:与WideLabs合作构建
预期用途
- 主要目标:支持主权AI开发,解决当前模型训练数据中缺失数据和潜在偏见的问题
- 适用场景:用于训练任何模型,特别是改进开放模型和推动技术进步
- 目标用户:从事主权AI、LLM训练的开发人员,以及希望提高合成数据多样性、减轻数据/模型偏见和防止模型崩溃的开发者
限制说明
- 排除内容:不包含NeMo Data Designer中可用的其他字段(如:名字/姓氏和合成地址),也不包含通常与企业客户相关的角色(如:金融、医疗保健)
- 数据局限性:受数据可用性和合理模型复杂性的限制,存在一些必要的独立性假设(例如,给定地点和性别,职业与教育程度独立)
- 身份信息:关于性别认同的综合统计数据(独立于生物性别)无法从国家人口普查中以细粒度格式完全获得
搜集汇总
数据集介绍
构建方式
在合成数据生成领域,Nemotron-Personas-Brazil数据集采用了一种基于真实世界统计分布的严谨构建方法。该数据集依托企业级复合人工智能系统NeMo Data Designer,通过专有的概率图模型(PGM)与开源大语言模型GPT-OSS-120B协同工作,生成合成人物角色。其构建核心在于深度锚定巴西官方统计数据,包括巴西地理与统计研究所(IBGE)发布的人口普查与劳动力市场数据,确保了年龄、性别、教育水平、职业及地理分布等关键变量与巴西人口的真实结构高度对齐。数据生成过程还整合了持续扩展的验证与评估模块,以保障合成角色的质量与统计代表性。
特点
该数据集的核心特征在于其高度的统计真实性与文化代表性。它包含一百万条葡萄牙语记录,每条记录涵盖六个维度的角色描述,总计生成六百万个合成人物。数据集通过二十个结构化字段,不仅提供了专业、体育、艺术、旅行及烹饪等多类型角色文本,还包含了基于巴西官方分类的职业、教育及市级地理单元等十四项上下文属性。其独特之处在于实现了对巴西二十七联邦单位人口密度与分布的精细映射,并融入了超过四十五万个独特姓名,以反映该国真实的语言与民族多样性。这些设计使其在支持合成数据多样性、缓解模型偏见及防止模型坍塌方面具有显著优势。
使用方法
该数据集主要服务于葡萄牙语大型语言模型的训练与优化,特别是在主权人工智能系统开发领域。使用者可通过HuggingFace平台直接加载数据集,利用其丰富的角色文本与上下文属性,生成高质量、多轮次的对话数据,以模拟真实的巴西用户体验。研究人员能够依据具体的州、市、职业或教育水平等字段进行数据筛选与子集构建,从而针对特定人口统计学群体开展模型训练或评估。数据集遵循CC BY 4.0许可协议,允许自由用于商业及非商业目的,为提升模型在巴西文化语境下的表现与公平性提供了关键资源。
背景与挑战
背景概述
在人工智能与合成数据生成领域,构建能够反映真实人口多样性的高质量数据集,对于推进语言模型的本土化与公平性至关重要。Nemotron-Personas-Brazil数据集由NVIDIA与WideLabs于2026年1月联合发布,旨在通过合成生成的人物角色,精准捕捉巴西人口在人口统计、地理分布及人格特质上的丰富多样性。该数据集基于巴西官方人口普查与劳动力统计数据构建,覆盖了包括区域多样性、种族背景、教育水平与职业在内的多维度特征,为开发具有文化敏感性的主权人工智能系统提供了关键数据支持,显著提升了合成数据在代表性与真实性方面的标准。
当前挑战
该数据集致力于解决生成式人工智能中合成数据代表性不足与模型偏见问题,其核心挑战在于如何确保合成人物角色在复杂社会维度上的统计真实性。构建过程中面临多重困难:首先,将离散的官方统计数据转化为连贯、自然的人物叙述需要克服模型独立性的简化假设,例如职业与教育背景的关联性可能未被充分捕捉;其次,人口普查数据在性别认同等敏感属性上缺乏细粒度统计,限制了数据集的全面性;此外,维持超过百万条记录在地区、姓名、职业分布上与真实人口的高度对齐,同时避免生成内容与真实个体产生关联,对生成与验证流程提出了极高的技术要求。
常用场景
经典使用场景
在自然语言处理领域,构建能够理解和生成符合特定文化背景文本的模型是一项核心挑战。Nemotron-Personas-Brazil数据集通过提供一百万条基于巴西真实人口统计分布生成的合成人物档案,为训练和评估葡萄牙语大语言模型提供了丰富的上下文素材。其经典使用场景在于为对话系统、内容生成模型提供多样化、高质量的训练数据,确保模型输出能够精准反映巴西各地区、各社会阶层的语言习惯与文化特质,从而提升模型在葡萄牙语环境下的表现力和适应性。
解决学术问题
该数据集主要致力于解决合成数据生成中的模型崩溃、数据偏见以及文化代表性不足等关键学术问题。通过严格对齐巴西地理与人口统计分布,它确保了生成数据的多样性与真实性,有效缓解了因训练数据单一导致的模型性能退化。其意义在于为构建更具包容性和公平性的人工智能系统提供了方法论范例,推动了主权AI的发展,使得模型能够更好地服务于特定地域与文化群体,为跨文化自然语言处理研究奠定了坚实的数据基础。
衍生相关工作
该数据集的发布催生了一系列围绕文化适配性语言模型和公平性AI评估的衍生研究。经典工作包括基于其构建的巴西葡萄牙语对话生成基准、用于检测和缓解模型地域偏见的评估框架,以及探索合成数据如何影响多语言模型跨文化泛化能力的研究。此外,它也为Nemotron-Personas系列数据集的扩展提供了蓝本,激励了针对其他拉丁美洲国家或特定专业领域(如医疗、法律)的类似高质量合成人物数据集的建设,持续丰富了全球AI数据生态的多样性。
以上内容由遇见数据集搜集并总结生成


